 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Weight Evaluation for Pruning Large Language Models: Enhancing Performance and Sustainability
Feb 24, 2025The exponential growth of large language models (LLMs) like ChatGPT has revolutionized artificial intelligence, offering unprecedented capabilities in natural language processing. However, the extensive computational resources required for training these models have significant environmental implications, including high carbon emissions, energy consumption, and water usage. This research presents a novel approach to LLM pruning, focusing on the systematic evaluation of individual weight importance throughout the training process. By monitoring parameter evolution over time, we propose a method that effectively reduces model size without compromising performance. Extensive experiments with both a scaled-down LLM and a large multimodal model reveal that moderate pruning enhances efficiency and reduces loss, while excessive pruning drastically deteriorates model performance. These findings highlight the critical need for optimized AI models to ensure sustainable development, balancing technological advancement with environmental responsibility.
Bio-Inspired Adaptive Neurons for Dynamic Weighting in Artificial Neural Networks
Dec 02, 2024



Traditional neural networks employ fixed weights during inference, limiting their ability to adapt to changing input conditions, unlike biological neurons that adjust signal strength dynamically based on stimuli. This discrepancy between artificial and biological neurons constrains neural network flexibility and adaptability. To bridge this gap, we propose a novel framework for adaptive neural networks, where neuron weights are modeled as functions of the input signal, allowing the network to adjust dynamically in real-time. Importantly, we achieve this within the same traditional architecture of an Artificial Neural Network, maintaining structural familiarity while introducing dynamic adaptability. In our research, we apply Chebyshev polynomials as one of the many possible decomposition methods to achieve this adaptive weighting mechanism, with polynomial coefficients learned during training. Out of the 145 datasets tested, our adaptive Chebyshev neural network demonstrated a marked improvement over an equivalent MLP in approximately 8\% of cases, performing strictly better on 121 datasets. In the remaining 24 datasets, the performance of our algorithm matched that of the MLP, highlighting its ability to generalize standard neural network behavior while offering enhanced adaptability. As a generalized form of the MLP, this model seamlessly retains MLP performance where needed while extending its capabilities to achieve superior accuracy across a wide range of complex tasks. These results underscore the potential of adaptive neurons to enhance generalization, flexibility, and robustness in neural networks, particularly in applications with dynamic or non-linear data dependencies.
Pushing Boundaries: Exploring Zero Shot Object Classification with Large Multimodal Models
Dec 30, 2023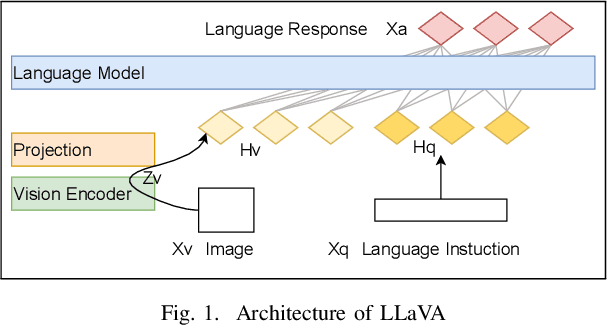
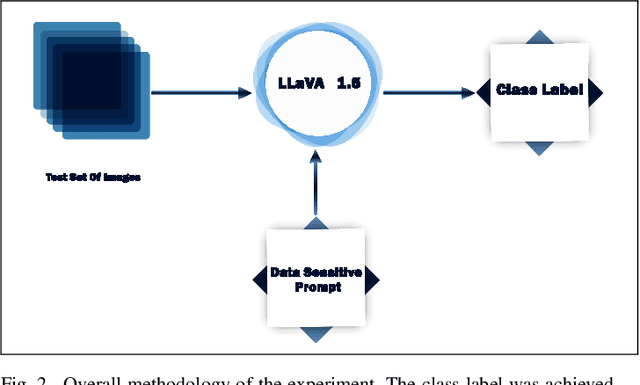


$ $The synergy of language and vision models has given rise to Large Language and Vision Assistant models (LLVAs), designed to engage users in rich conversational experiences intertwined with image-based queries. These comprehensive multimodal models seamlessly integrate vision encoders with Large Language Models (LLMs), expanding their applications in general-purpose language and visual comprehension. The advent of Large Multimodal Models (LMMs) heralds a new era in Artificial Intelligence (AI) assistance, extending the horizons of AI utilization. This paper takes a unique perspective on LMMs, exploring their efficacy in performing image classification tasks using tailored prompts designed for specific datasets. We also investigate the LLVAs zero-shot learning capabilities. Our study includes a benchmarking analysis across four diverse datasets: MNIST, Cats Vs. Dogs, Hymnoptera (Ants Vs. Bees), and an unconventional dataset comprising Pox Vs. Non-Pox skin images. The results of our experiments demonstrate the model's remarkable performance, achieving classification accuracies of 85\%, 100\%, 77\%, and 79\% for the respective datasets without any fine-tuning. To bolster our analysis, we assess the model's performance post fine-tuning for specific tasks. In one instance, fine-tuning is conducted over a dataset comprising images of faces of children with and without autism. Prior to fine-tuning, the model demonstrated a test accuracy of 55\%, which significantly improved to 83\% post fine-tuning. These results, coupled with our prior findings, underscore the transformative potential of LLVAs and their versatile applications in real-world scenarios.
* 5 pages,6 figures, 4 tables, Accepted on The International Symposium on Foundation and Large Language Models (FLLM2023)
Can ChatGPT be Your Personal Medical Assistant?
Dec 19, 2023The advanced large language model (LLM) ChatGPT has shown its potential in different domains and remains unbeaten due to its characteristics compared to other LLMs. This study aims to evaluate the potential of using a fine-tuned ChatGPT model as a personal medical assistant in the Arabic language. To do so, this study uses publicly available online questions and answering datasets in Arabic language. There are almost 430K questions and answers for 20 disease-specific categories. GPT-3.5-turbo model was fine-tuned with a portion of this dataset. The performance of this fine-tuned model was evaluated through automated and human evaluation. The automated evaluations include perplexity, coherence, similarity, and token count. Native Arabic speakers with medical knowledge evaluated the generated text by calculating relevance, accuracy, precision, logic, and originality. The overall result shows that ChatGPT has a bright future in medical assistance.
* 5 pages, 7 figures, two tables, Accepted on The International Symposium on Foundation and Large Language Models (FLLM2023)
IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C)
Oct 06, 2022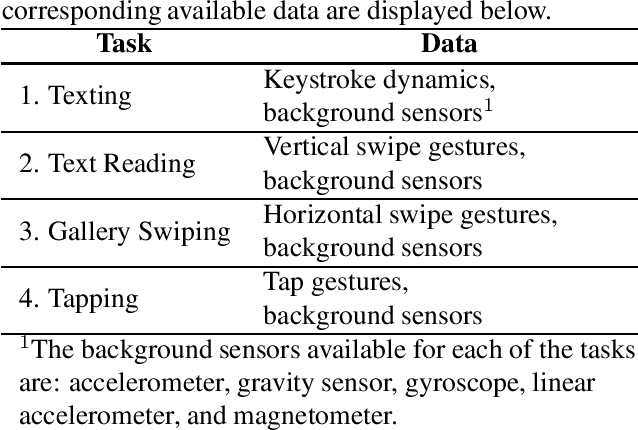
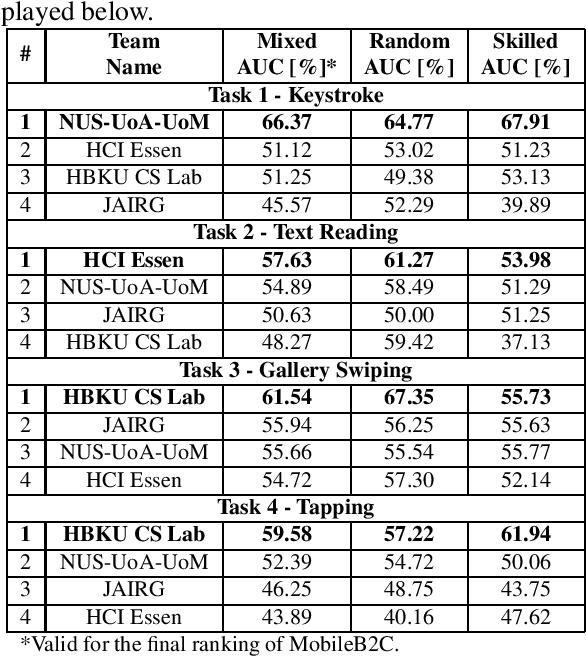
This paper describes the experimental framework and results of the IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C). The aim of MobileB2C is benchmarking mobile user authentication systems based on behavioral biometric traits transparently acquired by mobile devices during ordinary Human-Computer Interaction (HCI), using a novel public database, BehavePassDB, and a standard experimental protocol. The competition is divided into four tasks corresponding to typical user activities: keystroke, text reading, gallery swiping, and tapping. The data are composed of touchscreen data and several background sensor data simultaneously acquired. "Random" (different users with different devices) and "skilled" (different user on the same device attempting to imitate the legitimate one) impostor scenarios are considered. The results achieved by the participants show the feasibility of user authentication through behavioral biometrics, although this proves to be a non-trivial challenge. MobileB2C will be established as an on-going competition.