 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNullpointer at CheckThat! 2024: Identifying Subjectivity from Multilingual Text Sequence
Paper and Code

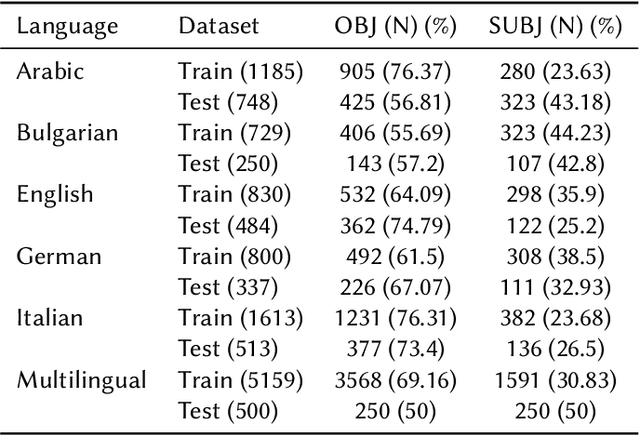
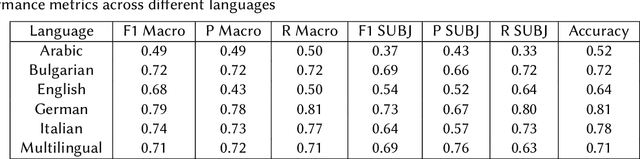
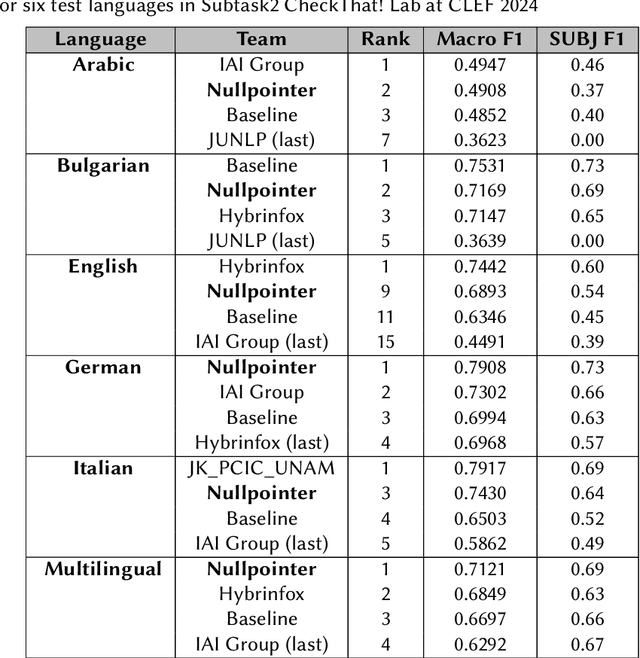
This study addresses a binary classification task to determine whether a text sequence, either a sentence or paragraph, is subjective or objective. The task spans five languages: Arabic, Bulgarian, English, German, and Italian, along with a multilingual category. Our approach involved several key techniques. Initially, we preprocessed the data through parts of speech (POS) tagging, identification of question marks, and application of attention masks. We fine-tuned the sentiment-based Transformer model 'MarieAngeA13/Sentiment-Analysis-BERT' on our dataset. Given the imbalance with more objective data, we implemented a custom classifier that assigned greater weight to objective data. Additionally, we translated non-English data into English to maintain consistency across the dataset. Our model achieved notable results, scoring top marks for the multilingual dataset (Macro F1=0.7121) and German (Macro F1=0.7908). It ranked second for Arabic (Macro F1=0.4908) and Bulgarian (Macro F1=0.7169), third for Italian (Macro F1=0.7430), and ninth for English (Macro F1=0.6893).