 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Prediction of Type 2 Diabetes Using Multimodal data and Tabular Transformers
Jan 19, 2026This study introduces a novel approach for early Type 2 Diabetes Mellitus (T2DM) risk prediction using a tabular transformer (TabTrans) architecture to analyze longitudinal patient data. By processing patients` longitudinal health records and bone-related tabular data, our model captures complex, long-range dependencies in disease progression that conventional methods often overlook. We validated our TabTrans model on a retrospective Qatar BioBank (QBB) cohort of 1,382 subjects, comprising 725 men (146 diabetic, 579 healthy) and 657 women (133 diabetic, 524 healthy). The study integrated electronic health records (EHR) with dual-energy X-ray absorptiometry (DXA) data. To address class imbalance, we employed SMOTE and SMOTE-ENN resampling techniques. The proposed model`s performance is evaluated against conventional machine learning (ML) and generative AI models, including Claude 3.5 Sonnet (Anthropic`s constitutional AI), GPT-4 (OpenAI`s generative pre-trained transformer), and Gemini Pro (Google`s multimodal language model). Our TabTrans model demonstrated superior predictive performance, achieving ROC AUC $\geq$ 79.7 % for T2DM prediction compared to both generative AI models and conventional ML approaches. Feature interpretation analysis identified key risk indicators, with visceral adipose tissue (VAT) mass and volume, ward bone mineral density (BMD) and bone mineral content (BMC), T and Z-scores, and L1-L4 scores emerging as the most important predictors associated with diabetes development in Qatari adults. These findings demonstrate the significant potential of TabTrans for analyzing complex tabular healthcare data, providing a powerful tool for proactive T2DM management and personalized clinical interventions in the Qatari population. Index Terms: tabular transformers, multimodal data, DXA data, diabetes, T2DM, feature interpretation, tabular data
An Early Investigation into the Utility of Multimodal Large Language Models in Medical Imaging
Jun 02, 2024Recent developments in multimodal large language models (MLLMs) have spurred significant interest in their potential applications across various medical imaging domains. On the one hand, there is a temptation to use these generative models to synthesize realistic-looking medical image data, while on the other hand, the ability to identify synthetic image data in a pool of data is also significantly important. In this study, we explore the potential of the Gemini (\textit{gemini-1.0-pro-vision-latest}) and GPT-4V (gpt-4-vision-preview) models for medical image analysis using two modalities of medical image data. Utilizing synthetic and real imaging data, both Gemini AI and GPT-4V are first used to classify real versus synthetic images, followed by an interpretation and analysis of the input images. Experimental results demonstrate that both Gemini and GPT-4 could perform some interpretation of the input images. In this specific experiment, Gemini was able to perform slightly better than the GPT-4V on the classification task. In contrast, responses associated with GPT-4V were mostly generic in nature. Our early investigation presented in this work provides insights into the potential of MLLMs to assist with the classification and interpretation of retinal fundoscopy and lung X-ray images. We also identify key limitations associated with the early investigation study on MLLMs for specialized tasks in medical image analysis.
An Intelligent Monitoring System of Vehicles on Highway Traffic
May 27, 2019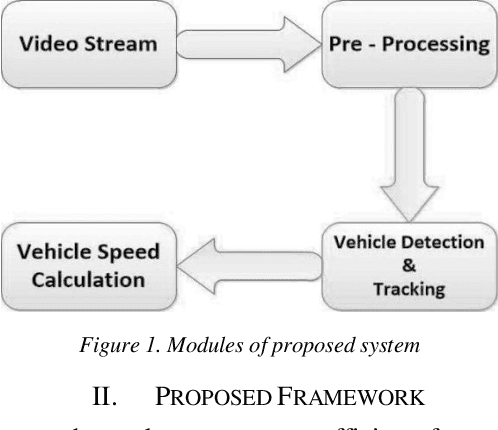
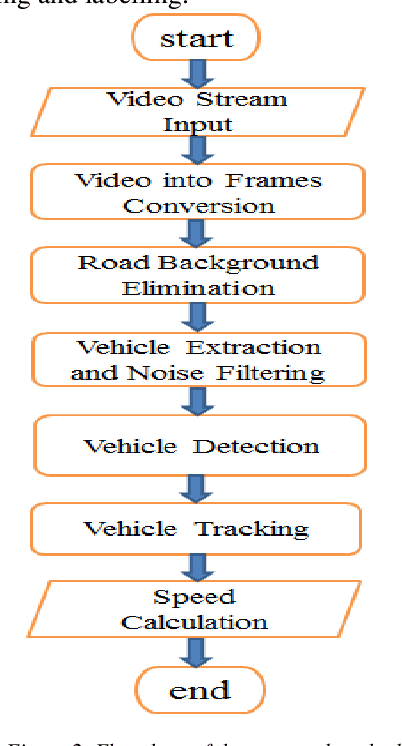


Vehicle speed monitoring and management of highways is the critical problem of the road in this modern age of growing technology and population. A poor management results in frequent traffic jam, traffic rules violation and fatal road accidents. Using traditional techniques of RADAR, LIDAR and LASAR to address this problem is time-consuming, expensive and tedious. This paper presents an efficient framework to produce a simple, cost efficient and intelligent system for vehicle speed monitoring. The proposed method uses an HD (High Definition) camera mounted on the road side either on a pole or on a traffic signal for recording video frames. On the basis of these frames, a vehicle can be tracked by using radius growing method, and its speed can be calculated by calculating vehicle mask and its displacement in consecutive frames. The method uses pattern recognition, digital image processing and mathematical techniques for vehicle detection, tracking and speed calculation. The validity of the proposed model is proved by testing it on different highways.
* 5 pages
Higher Accurate Recognition of Handwritten Pashto Letters through Zoning Feature by using K-Nearest Neighbour and Artificial Neural Network
Apr 06, 2019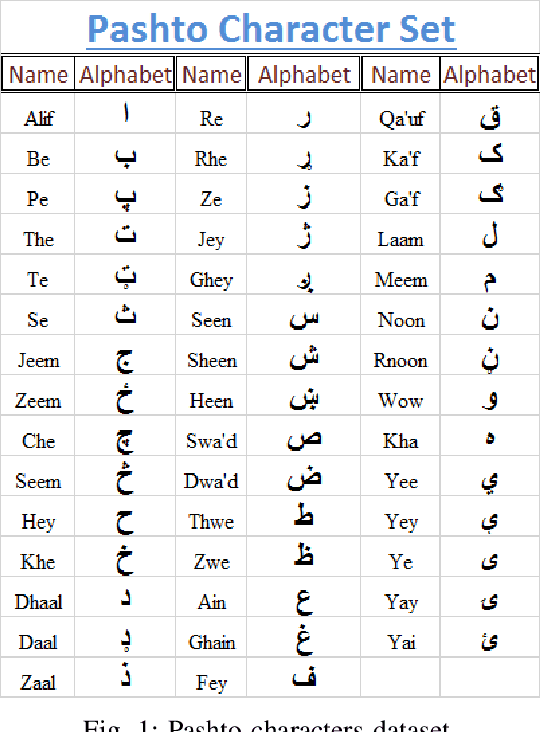
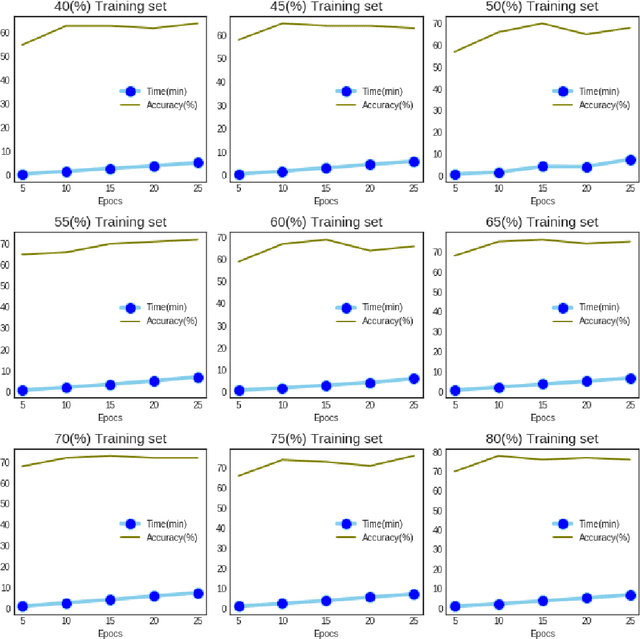
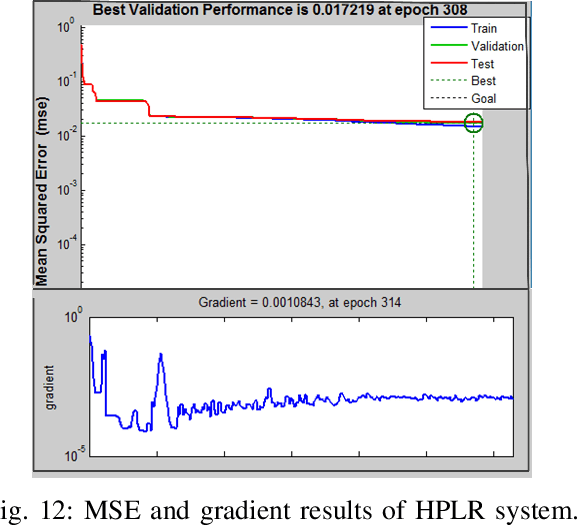
This paper presents a recognition system for handwritten Pashto letters. However, handwritten character recognition is a challenging task. These letters not only differ in shape and style but also vary among individuals. The recognition becomes further daunting due to the lack of standard datasets for inscribed Pashto letters. In this work, we have designed a database of moderate size, which encompasses a total of 4488 images, stemming from 102 distinguishing samples for each of the 44 letters in Pashto. The recognition framework uses zoning feature extractor followed by K-Nearest Neighbour (KNN) and Neural Network (NN) classifiers for classifying individual letter. Based on the evaluation of the proposed system, an overall classification accuracy of approximately 70.05% is achieved by using KNN while 72% is achieved by using NN.
* (IJACSA) International Journal of Advanced Computer Science and Applications,