 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan GPT-4 Identify Propaganda? Annotation and Detection of Propaganda Spans in News Articles
Paper and Code
Feb 27, 2024


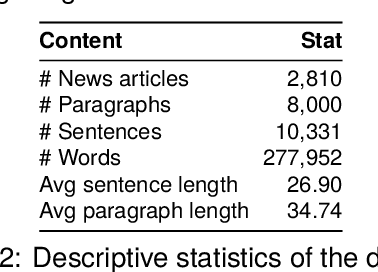
The use of propaganda has spiked on mainstream and social media, aiming to manipulate or mislead users. While efforts to automatically detect propaganda techniques in textual, visual, or multimodal content have increased, most of them primarily focus on English content. The majority of the recent initiatives targeting medium to low-resource languages produced relatively small annotated datasets, with a skewed distribution, posing challenges for the development of sophisticated propaganda detection models. To address this challenge, we carefully develop the largest propaganda dataset to date, ArPro, comprised of 8K paragraphs from newspaper articles, labeled at the text span level following a taxonomy of 23 propagandistic techniques. Furthermore, our work offers the first attempt to understand the performance of large language models (LLMs), using GPT-4, for fine-grained propaganda detection from text. Results showed that GPT-4's performance degrades as the task moves from simply classifying a paragraph as propagandistic or not, to the fine-grained task of detecting propaganda techniques and their manifestation in text. Compared to models fine-tuned on the dataset for propaganda detection at different classification granularities, GPT-4 is still far behind. Finally, we evaluate GPT-4 on a dataset consisting of six other languages for span detection, and results suggest that the model struggles with the task across languages. Our dataset and resources will be released to the community.