 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepthwise Separable Convolutions with Deep Residual Convolutions
Nov 12, 2024

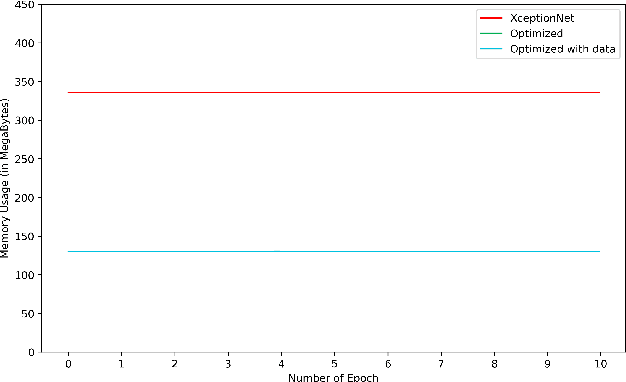
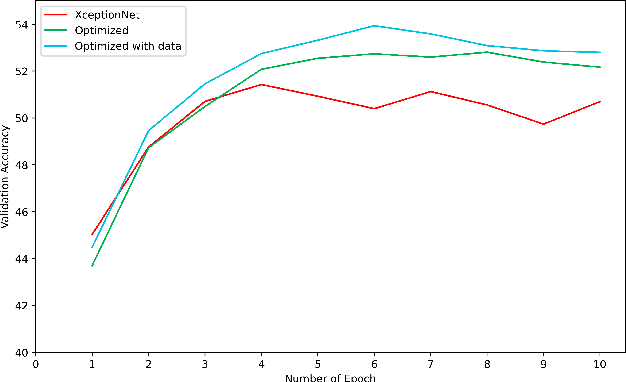
The recent advancement of edge computing enables researchers to optimize various deep learning architectures to employ them in edge devices. In this study, we aim to optimize Xception architecture which is one of the most popular deep learning algorithms for computer vision applications. The Xception architecture is highly effective for object detection tasks. However, it comes with a significant computational cost. The computational complexity of Xception sometimes hinders its deployment on resource-constrained edge devices. To address this, we propose an optimized Xception architecture tailored for edge devices, aiming for lightweight and efficient deployment. We incorporate the depthwise separable convolutions with deep residual convolutions of the Xception architecture to develop a small and efficient model for edge devices. The resultant architecture reduces parameters, memory usage, and computational load. The proposed architecture is evaluated on the CIFAR 10 object detection dataset. The evaluation result of our experiment also shows the proposed architecture is smaller in parameter size and requires less training time while outperforming Xception architecture performance.
Better to Ask in English: Evaluation of Large Language Models on English, Low-resource and Cross-Lingual Settings
Oct 17, 2024Large Language Models (LLMs) are trained on massive amounts of data, enabling their application across diverse domains and tasks. Despite their remarkable performance, most LLMs are developed and evaluated primarily in English. Recently, a few multi-lingual LLMs have emerged, but their performance in low-resource languages, especially the most spoken languages in South Asia, is less explored. To address this gap, in this study, we evaluate LLMs such as GPT-4, Llama 2, and Gemini to analyze their effectiveness in English compared to other low-resource languages from South Asia (e.g., Bangla, Hindi, and Urdu). Specifically, we utilized zero-shot prompting and five different prompt settings to extensively investigate the effectiveness of the LLMs in cross-lingual translated prompts. The findings of the study suggest that GPT-4 outperformed Llama 2 and Gemini in all five prompt settings and across all languages. Moreover, all three LLMs performed better for English language prompts than other low-resource language prompts. This study extensively investigates LLMs in low-resource language contexts to highlight the improvements required in LLMs and language-specific resources to develop more generally purposed NLP applications.
Do Large Language Models Speak All Languages Equally? A Comparative Study in Low-Resource Settings
Aug 05, 2024



Large language models (LLMs) have garnered significant interest in natural language processing (NLP), particularly their remarkable performance in various downstream tasks in resource-rich languages. Recent studies have highlighted the limitations of LLMs in low-resource languages, primarily focusing on binary classification tasks and giving minimal attention to South Asian languages. These limitations are primarily attributed to constraints such as dataset scarcity, computational costs, and research gaps specific to low-resource languages. To address this gap, we present datasets for sentiment and hate speech tasks by translating from English to Bangla, Hindi, and Urdu, facilitating research in low-resource language processing. Further, we comprehensively examine zero-shot learning using multiple LLMs in English and widely spoken South Asian languages. Our findings indicate that GPT-4 consistently outperforms Llama 2 and Gemini, with English consistently demonstrating superior performance across diverse tasks compared to low-resource languages. Furthermore, our analysis reveals that natural language inference (NLI) exhibits the highest performance among the evaluated tasks, with GPT-4 demonstrating superior capabilities.