 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemeLens: Multilingual Multitask VLMs for Memes
Jan 18, 2026Memes are a dominant medium for online communication and manipulation because meaning emerges from interactions between embedded text, imagery, and cultural context. Existing meme research is distributed across tasks (hate, misogyny, propaganda, sentiment, humour) and languages, which limits cross-domain generalization. To address this gap we propose MemeLens, a unified multilingual and multitask explanation-enhanced Vision Language Model (VLM) for meme understanding. We consolidate 38 public meme datasets, filter and map dataset-specific labels into a shared taxonomy of $20$ tasks spanning harm, targets, figurative/pragmatic intent, and affect. We present a comprehensive empirical analysis across modeling paradigms, task categories, and datasets. Our findings suggest that robust meme understanding requires multimodal training, exhibits substantial variation across semantic categories, and remains sensitive to over-specialization when models are fine-tuned on individual datasets rather than trained in a unified setting. We will make the experimental resources and datasets publicly available for the community.
MemeIntel: Explainable Detection of Propagandistic and Hateful Memes
Feb 23, 2025The proliferation of multimodal content on social media presents significant challenges in understanding and moderating complex, context-dependent issues such as misinformation, hate speech, and propaganda. While efforts have been made to develop resources and propose new methods for automatic detection, limited attention has been given to label detection and the generation of explanation-based rationales for predicted labels. To address this challenge, we introduce MemeIntel, an explanation-enhanced dataset for propaganda memes in Arabic and hateful memes in English, making it the first large-scale resource for these tasks. To solve these tasks, we propose a multi-stage optimization approach and train Vision-Language Models (VLMs). Our results demonstrate that this approach significantly improves performance over the base model for both \textbf{label detection} and explanation generation, outperforming the current state-of-the-art with an absolute improvement of ~3% on ArMeme and ~7% on Hateful Memes. For reproducibility and future research, we aim to make the MemeIntel dataset and experimental resources publicly available.
Reasoning About Persuasion: Can LLMs Enable Explainable Propaganda Detection?
Feb 23, 2025There has been significant research on propagandistic content detection across different modalities and languages. However, most studies have primarily focused on detection, with little attention given to explanations justifying the predicted label. This is largely due to the lack of resources that provide explanations alongside annotated labels. To address this issue, we propose a multilingual (i.e., Arabic and English) explanation-enhanced dataset, the first of its kind. Additionally, we introduce an explanation-enhanced LLM for both label detection and rationale-based explanation generation. Our findings indicate that the model performs comparably while also generating explanations. We will make the dataset and experimental resources publicly available for the research community.
Can Large Language Models Predict the Outcome of Judicial Decisions?
Jan 15, 2025Large Language Models (LLMs) have shown exceptional capabilities in Natural Language Processing (NLP) across diverse domains. However, their application in specialized tasks such as Legal Judgment Prediction (LJP) for low-resource languages like Arabic remains underexplored. In this work, we address this gap by developing an Arabic LJP dataset, collected and preprocessed from Saudi commercial court judgments. We benchmark state-of-the-art open-source LLMs, including LLaMA-3.2-3B and LLaMA-3.1-8B, under varying configurations such as zero-shot, one-shot, and fine-tuning using QLoRA. Additionally, we used a comprehensive evaluation framework combining quantitative metrics (BLEU and ROUGE) and qualitative assessments (Coherence, legal language, clarity). Our results demonstrate that fine-tuned smaller models achieve comparable performance to larger models in task-specific contexts while offering significant resource efficiency. Furthermore, we investigate the effects of prompt engineering and fine-tuning on model outputs, providing insights into performance variability and instruction sensitivity. By making the dataset, implementation code, and models publicly available, we establish a robust foundation for future research in Arabic legal NLP.
LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content
Oct 20, 2024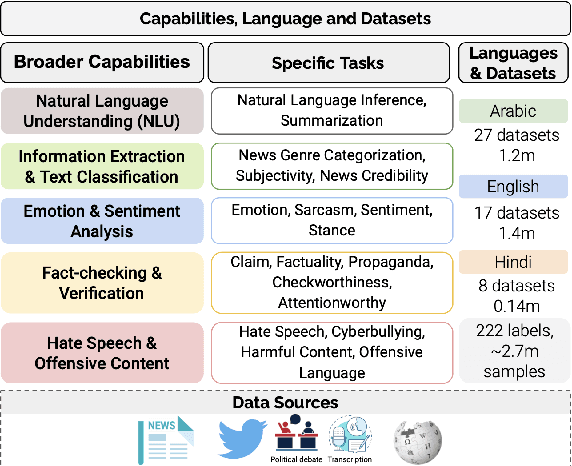
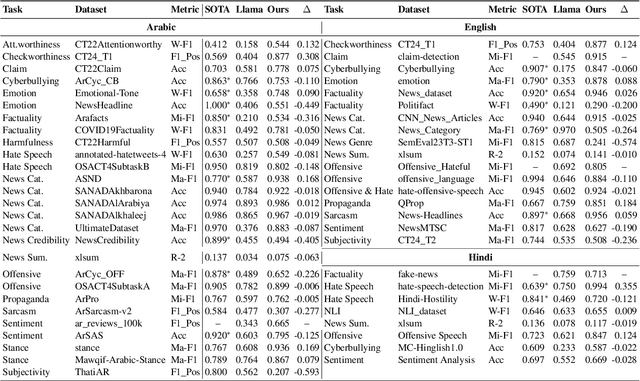
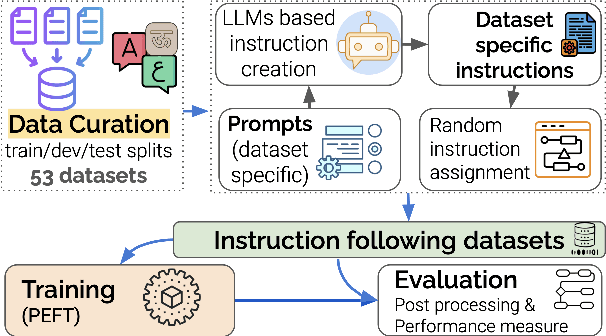
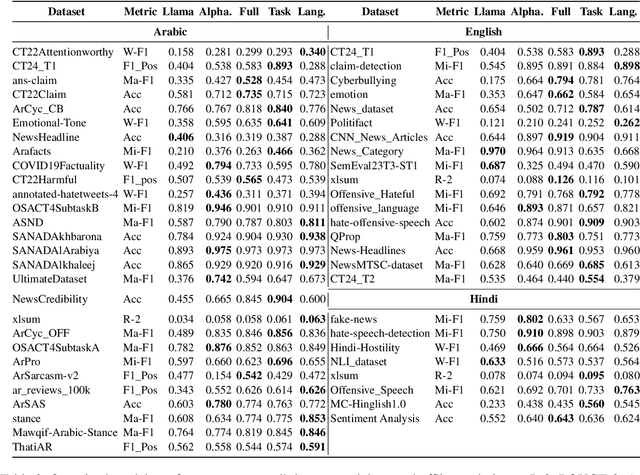
Large Language Models (LLMs) have demonstrated remarkable success as general-purpose task solvers across various fields, including NLP, healthcare, finance, and law. However, their capabilities remain limited when addressing domain-specific problems, particularly in downstream NLP tasks. Research has shown that models fine-tuned on instruction-based downstream NLP datasets outperform those that are not fine-tuned. While most efforts in this area have primarily focused on resource-rich languages like English and broad domains, little attention has been given to multilingual settings and specific domains. To address this gap, this study focuses on developing a specialized LLM, LlamaLens, for analyzing news and social media content in a multilingual context. To the best of our knowledge, this is the first attempt to tackle both domain specificity and multilinguality, with a particular focus on news and social media. Our experimental setup includes 19 tasks, represented by 52 datasets covering Arabic, English, and Hindi. We demonstrate that LlamaLens outperforms the current state-of-the-art (SOTA) on 16 testing sets, and achieves comparable performance on 10 sets. We make the models and resources publicly available for the research community.(https://huggingface.co/QCRI)
Native vs Non-Native Language Prompting: A Comparative Analysis
Sep 11, 2024



Large language models (LLMs) have shown remarkable abilities in different fields, including standard Natural Language Processing (NLP) tasks. To elicit knowledge from LLMs, prompts play a key role, consisting of natural language instructions. Most open and closed source LLMs are trained on available labeled and unlabeled resources--digital content such as text, images, audio, and videos. Hence, these models have better knowledge for high-resourced languages but struggle with low-resourced languages. Since prompts play a crucial role in understanding their capabilities, the language used for prompts remains an important research question. Although there has been significant research in this area, it is still limited, and less has been explored for medium to low-resourced languages. In this study, we investigate different prompting strategies (native vs. non-native) on 11 different NLP tasks associated with 12 different Arabic datasets (9.7K data points). In total, we conducted 197 experiments involving 3 LLMs, 12 datasets, and 3 prompting strategies. Our findings suggest that, on average, the non-native prompt performs the best, followed by mixed and native prompts.