 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-based Unsupervised Framing Analysis (SUFA): A Novel Approach for Computational Framing Analysis
May 21, 2025This research presents a novel approach to computational framing analysis, called Semantic Relations-based Unsupervised Framing Analysis (SUFA). SUFA leverages semantic relations and dependency parsing algorithms to identify and assess entity-centric emphasis frames in news media reports. This innovative method is derived from two studies -- qualitative and computational -- using a dataset related to gun violence, demonstrating its potential for analyzing entity-centric emphasis frames. This article discusses SUFA's strengths, limitations, and application procedures. Overall, the SUFA approach offers a significant methodological advancement in computational framing analysis, with its broad applicability across both the social sciences and computational domains.
LlamaLens: Specialized Multilingual LLM for Analyzing News and Social Media Content
Oct 20, 2024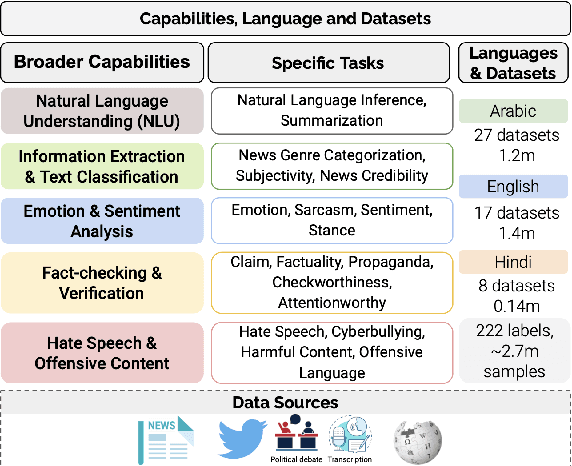
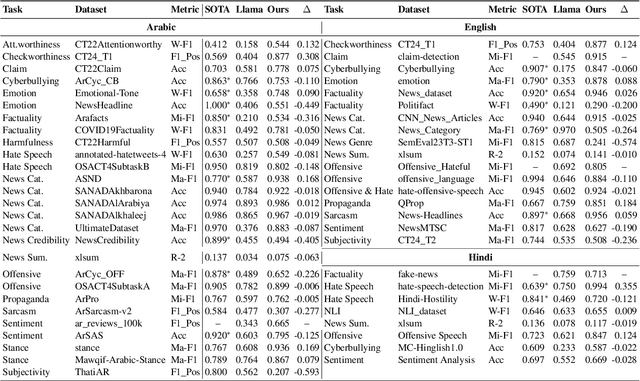
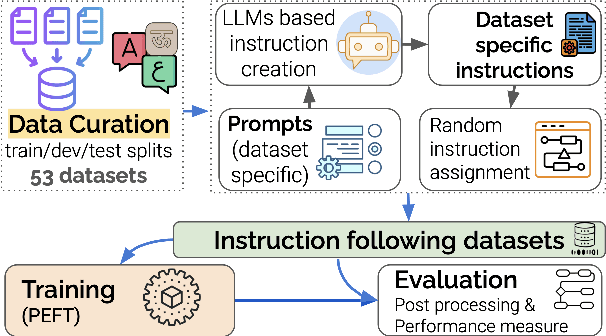
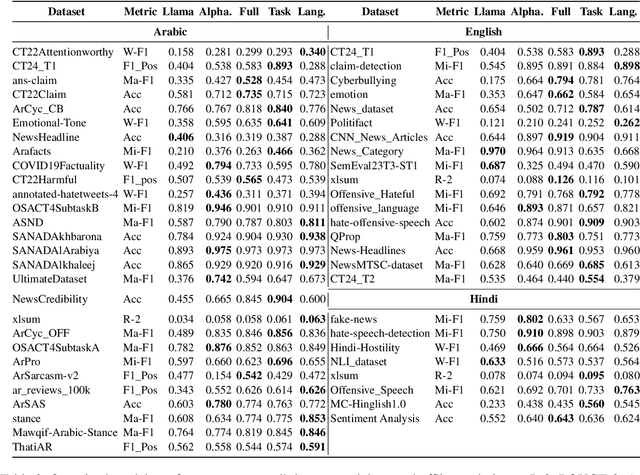
Large Language Models (LLMs) have demonstrated remarkable success as general-purpose task solvers across various fields, including NLP, healthcare, finance, and law. However, their capabilities remain limited when addressing domain-specific problems, particularly in downstream NLP tasks. Research has shown that models fine-tuned on instruction-based downstream NLP datasets outperform those that are not fine-tuned. While most efforts in this area have primarily focused on resource-rich languages like English and broad domains, little attention has been given to multilingual settings and specific domains. To address this gap, this study focuses on developing a specialized LLM, LlamaLens, for analyzing news and social media content in a multilingual context. To the best of our knowledge, this is the first attempt to tackle both domain specificity and multilinguality, with a particular focus on news and social media. Our experimental setup includes 19 tasks, represented by 52 datasets covering Arabic, English, and Hindi. We demonstrate that LlamaLens outperforms the current state-of-the-art (SOTA) on 16 testing sets, and achieves comparable performance on 10 sets. We make the models and resources publicly available for the research community.(https://huggingface.co/QCRI)
Exploring the Potential of the Large Language Models in Identifying Misleading News Headlines
May 06, 2024

In the digital age, the prevalence of misleading news headlines poses a significant challenge to information integrity, necessitating robust detection mechanisms. This study explores the efficacy of Large Language Models (LLMs) in identifying misleading versus non-misleading news headlines. Utilizing a dataset of 60 articles, sourced from both reputable and questionable outlets across health, science & tech, and business domains, we employ three LLMs- ChatGPT-3.5, ChatGPT-4, and Gemini-for classification. Our analysis reveals significant variance in model performance, with ChatGPT-4 demonstrating superior accuracy, especially in cases with unanimous annotator agreement on misleading headlines. The study emphasizes the importance of human-centered evaluation in developing LLMs that can navigate the complexities of misinformation detection, aligning technical proficiency with nuanced human judgment. Our findings contribute to the discourse on AI ethics, emphasizing the need for models that are not only technically advanced but also ethically aligned and sensitive to the subtleties of human interpretation.
Not all Fake News is Written: A Dataset and Analysis of Misleading Video Headlines
Oct 20, 2023
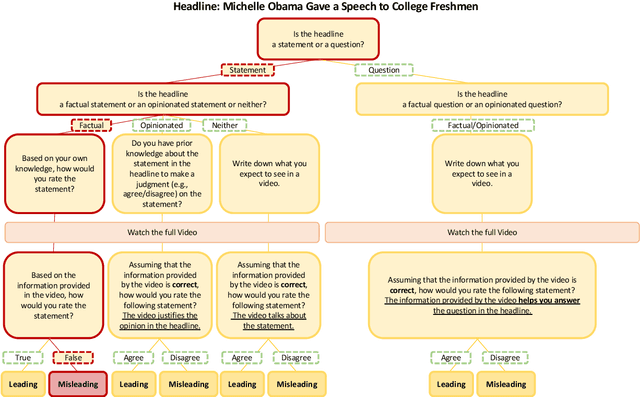


Polarization and the marketplace for impressions have conspired to make navigating information online difficult for users, and while there has been a significant effort to detect false or misleading text, multimodal datasets have received considerably less attention. To complement existing resources, we present multimodal Video Misleading Headline (VMH), a dataset that consists of videos and whether annotators believe the headline is representative of the video's contents. After collecting and annotating this dataset, we analyze multimodal baselines for detecting misleading headlines. Our annotation process also focuses on why annotators view a video as misleading, allowing us to better understand the interplay of annotators' background and the content of the videos.
A Benchmark Dataset of Check-worthy Factual Claims
Apr 29, 2020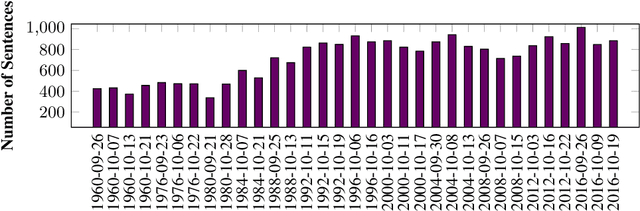
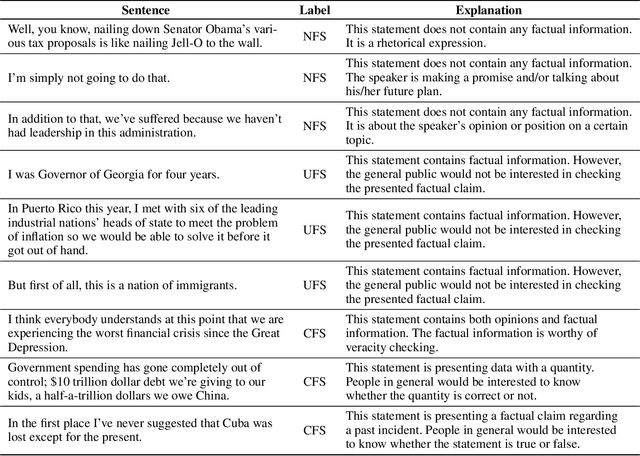
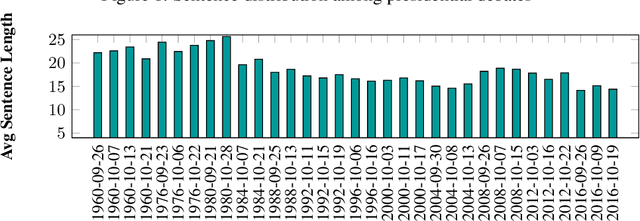

In this paper we present the ClaimBuster dataset of 23,533 statements extracted from all U.S. general election presidential debates and annotated by human coders. The ClaimBuster dataset can be leveraged in building computational methods to identify claims that are worth fact-checking from the myriad of sources of digital or traditional media. The ClaimBuster dataset is publicly available to the research community, and it can be found at http://doi.org/10.5281/zenodo.3609356.
Automatically Assessing Quality of Online Health Articles
Apr 07, 2020


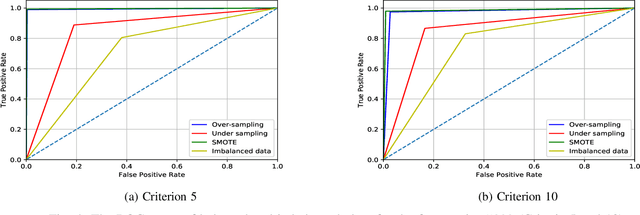
The information ecosystem today is overwhelmed by an unprecedented quantity of data on versatile topics are with varied quality. However, the quality of information disseminated in the field of medicine has been questioned as the negative health consequences of health misinformation can be life-threatening. There is currently no generic automated tool for evaluating the quality of online health information spanned over a broad range. To address this gap, in this paper, we applied a data mining approach to automatically assess the quality of online health articles based on 10 quality criteria. We have prepared a labeled dataset with 53012 features and applied different feature selection methods to identify the best feature subset with which our trained classifier achieved an accuracy of 84%-90% varied over 10 criteria. Our semantic analysis of features shows the underpinning associations between the selected features & assessment criteria and further rationalize our assessment approach. Our findings will help in identifying high-quality health articles and thus aiding users in shaping their opinion to make the right choice while picking health-related help from online.
Examining the Role of Clickbait Headlines to Engage Readers with Reliable Health-related Information
Nov 25, 2019Clickbait headlines are frequently used to attract readers to read articles. Although this headline type has turned out to be a technique to engage readers with misleading items, it is still unknown whether the technique can be used to attract readers to reliable pieces. This study takes the opportunity to test its efficacy to engage readers with reliable health articles. A set of online surveys would be conducted to test readers' engagement with and perception about clickbait headlines with reliable articles. After that, we would design an automation system to generate clickabit headlines to maximize user engagement.
Towards Automated Sexual Violence Report Tracking
Nov 16, 2019

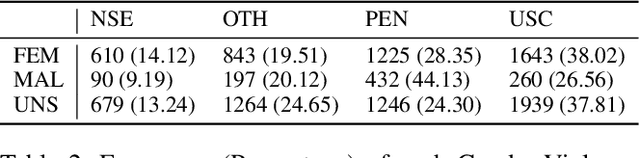
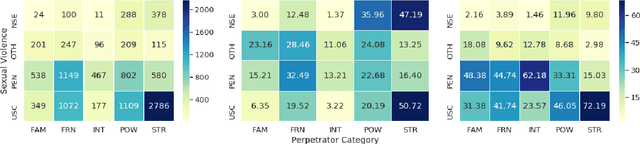
Tracking sexual violence is a challenging task. In this paper, we present a supervised learning-based automated sexual violence report tracking model that is more scalable, and reliable than its crowdsource based counterparts. We define the sexual violence report tracking problem by considering victim, perpetrator contexts and the nature of the violence. We find that our model could identify sexual violence reports with a precision and recall of 80.4% and 83.4%, respectively. Moreover, we also applied the model during and after the \#MeToo movement. Several interesting findings are discovered which are not easily identifiable from a shallow analysis.
Diving Deep into Clickbaits: Who Use Them to What Extents in Which Topics with What Effects?
Mar 28, 2017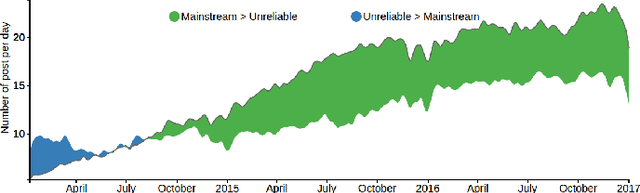

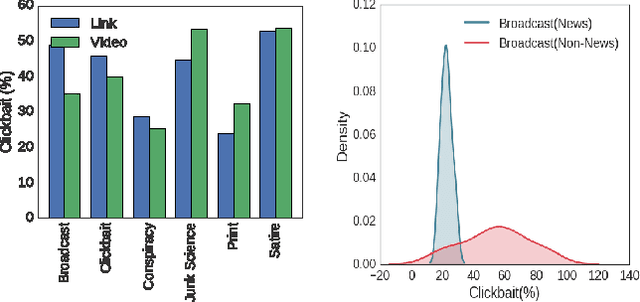
The use of alluring headlines (clickbait) to tempt the readers has become a growing practice nowadays. For the sake of existence in the highly competitive media industry, most of the on-line media including the mainstream ones, have started following this practice. Although the wide-spread practice of clickbait makes the reader's reliability on media vulnerable, a large scale analysis to reveal this fact is still absent. In this paper, we analyze 1.67 million Facebook posts created by 153 media organizations to understand the extent of clickbait practice, its impact and user engagement by using our own developed clickbait detection model. The model uses distributed sub-word embeddings learned from a large corpus. The accuracy of the model is 98.3%. Powered with this model, we further study the distribution of topics in clickbait and non-clickbait contents.
Dis-S2V: Discourse Informed Sen2Vec
Oct 25, 2016



Vector representation of sentences is important for many text processing tasks that involve clustering, classifying, or ranking sentences. Recently, distributed representation of sentences learned by neural models from unlabeled data has been shown to outperform the traditional bag-of-words representation. However, most of these learning methods consider only the content of a sentence and disregard the relations among sentences in a discourse by and large. In this paper, we propose a series of novel models for learning latent representations of sentences (Sen2Vec) that consider the content of a sentence as well as inter-sentence relations. We first represent the inter-sentence relations with a language network and then use the network to induce contextual information into the content-based Sen2Vec models. Two different approaches are introduced to exploit the information in the network. Our first approach retrofits (already trained) Sen2Vec vectors with respect to the network in two different ways: (1) using the adjacency relations of a node, and (2) using a stochastic sampling method which is more flexible in sampling neighbors of a node. The second approach uses a regularizer to encode the information in the network into the existing Sen2Vec model. Experimental results show that our proposed models outperform existing methods in three fundamental information system tasks demonstrating the effectiveness of our approach. The models leverage the computational power of multi-core CPUs to achieve fine-grained computational efficiency. We make our code publicly available upon acceptance.