 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting LLMs to Compose Meta-Review Drafts from Peer-Review Narratives of Scholarly Manuscripts
Feb 23, 2024One of the most important yet onerous tasks in the academic peer-reviewing process is composing meta-reviews, which involves understanding the core contributions, strengths, and weaknesses of a scholarly manuscript based on peer-review narratives from multiple experts and then summarizing those multiple experts' perspectives into a concise holistic overview. Given the latest major developments in generative AI, especially Large Language Models (LLMs), it is very compelling to rigorously study the utility of LLMs in generating such meta-reviews in an academic peer-review setting. In this paper, we perform a case study with three popular LLMs, i.e., GPT-3.5, LLaMA2, and PaLM2, to automatically generate meta-reviews by prompting them with different types/levels of prompts based on the recently proposed TELeR taxonomy. Finally, we perform a detailed qualitative study of the meta-reviews generated by the LLMs and summarize our findings and recommendations for prompting LLMs for this complex task.
Word Embeddings Revisited: Do LLMs Offer Something New?
Feb 16, 2024Learning meaningful word embeddings is key to training a robust language model. The recent rise of Large Language Models (LLMs) has provided us with many new word/sentence/document embedding models. Although LLMs have shown remarkable advancement in various NLP tasks, it is still unclear whether the performance improvement is merely because of scale or whether underlying embeddings they produce significantly differ from classical encoding models like Sentence-BERT (SBERT) or Universal Sentence Encoder (USE). This paper systematically investigates this issue by comparing classical word embedding techniques against LLM-based word embeddings in terms of their latent vector semantics. Our results show that LLMs tend to cluster semantically related words more tightly than classical models. LLMs also yield higher average accuracy on the Bigger Analogy Test Set (BATS) over classical methods. Finally, some LLMs tend to produce word embeddings similar to SBERT, a relatively lighter classical model.
SNNLP: Energy-Efficient Natural Language Processing Using Spiking Neural Networks
Jan 31, 2024As spiking neural networks receive more attention, we look toward applications of this computing paradigm in fields other than computer vision and signal processing. One major field, underexplored in the neuromorphic setting, is Natural Language Processing (NLP), where most state-of-the-art solutions still heavily rely on resource-consuming and power-hungry traditional deep learning architectures. Therefore, it is compelling to design NLP models for neuromorphic architectures due to their low energy requirements, with the additional benefit of a more human-brain-like operating model for processing information. However, one of the biggest issues with bringing NLP to the neuromorphic setting is in properly encoding text into a spike train so that it can be seamlessly handled by both current and future SNN architectures. In this paper, we compare various methods of encoding text as spikes and assess each method's performance in an associated SNN on a downstream NLP task, namely, sentiment analysis. Furthermore, we go on to propose a new method of encoding text as spikes that outperforms a widely-used rate-coding technique, Poisson rate-coding, by around 13\% on our benchmark NLP tasks. Subsequently, we demonstrate the energy efficiency of SNNs implemented in hardware for the sentiment analysis task compared to traditional deep neural networks, observing an energy efficiency increase of more than 32x during inference and 60x during training while incurring the expected energy-performance tradeoff.
FaNS: a Facet-based Narrative Similarity Metric
Sep 09, 2023
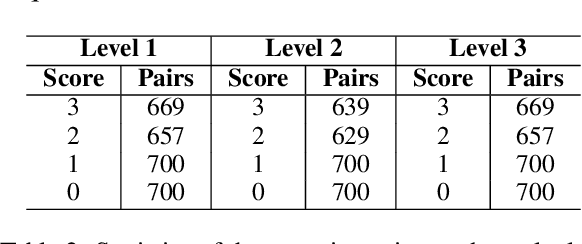

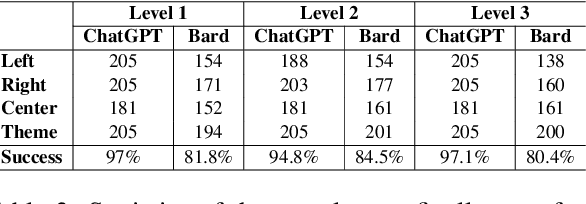
Similar Narrative Retrieval is a crucial task since narratives are essential for explaining and understanding events, and multiple related narratives often help to create a holistic view of the event of interest. To accurately identify semantically similar narratives, this paper proposes a novel narrative similarity metric called Facet-based Narrative Similarity (FaNS), based on the classic 5W1H facets (Who, What, When, Where, Why, and How), which are extracted by leveraging the state-of-the-art Large Language Models (LLMs). Unlike existing similarity metrics that only focus on overall lexical/semantic match, FaNS provides a more granular matching along six different facets independently and then combines them. To evaluate FaNS, we created a comprehensive dataset by collecting narratives from AllSides, a third-party news portal. Experimental results demonstrate that the FaNS metric exhibits a higher correlation (37\% higher) than traditional text similarity metrics that directly measure the lexical/semantic match between narratives, demonstrating its effectiveness in comparing the finer details between a pair of narratives.
Redundancy Aware Multi-Reference Based Gainwise Evaluation of Extractive Summarization
Aug 04, 2023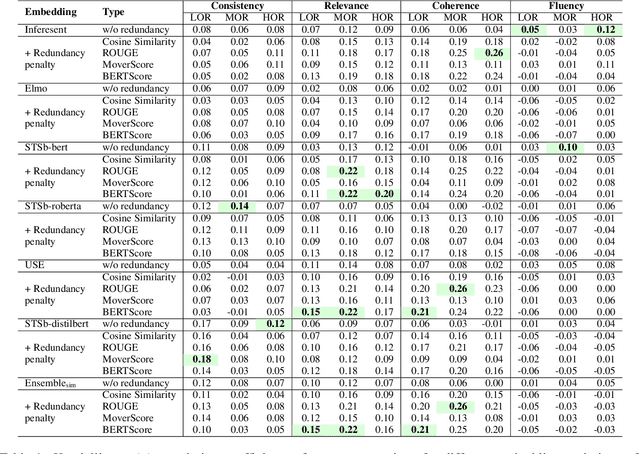
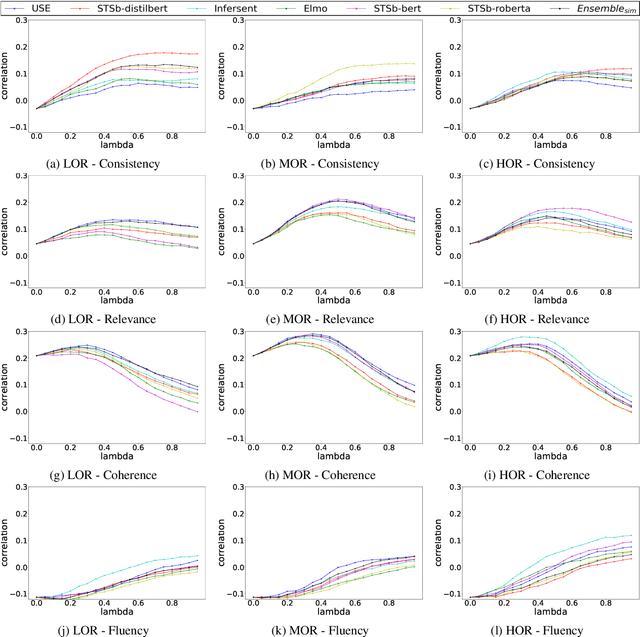

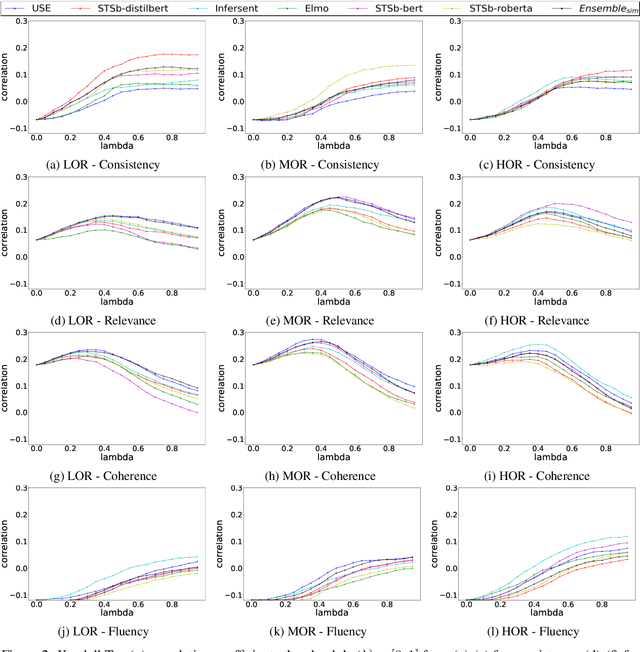
While very popular for evaluating extractive summarization task, the ROUGE metric has long been criticized for its lack of semantic awareness and its ignorance about the ranking quality of the summarizer. Thanks to previous research that has addressed these issues by proposing a gain-based automated metric called Sem-nCG, which is both rank and semantic aware. However, Sem-nCG does not consider the amount of redundancy present in a model-generated summary and currently does not support evaluation with multiple reference summaries. Unfortunately, addressing both these limitations simultaneously is not trivial. Therefore, in this paper, we propose a redundancy-aware Sem-nCG metric and demonstrate how this new metric can be used to evaluate model summaries against multiple references. We also explore different ways of incorporating redundancy into the original metric through extensive experiments. Experimental results demonstrate that the new redundancy-aware metric exhibits a higher correlation with human judgments than the original Sem-nCG metric for both single and multiple reference scenarios.
ChatGPT as your Personal Data Scientist
May 23, 2023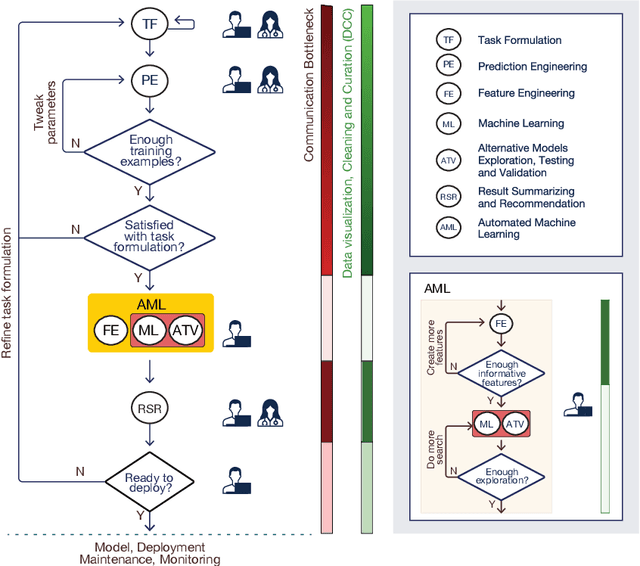

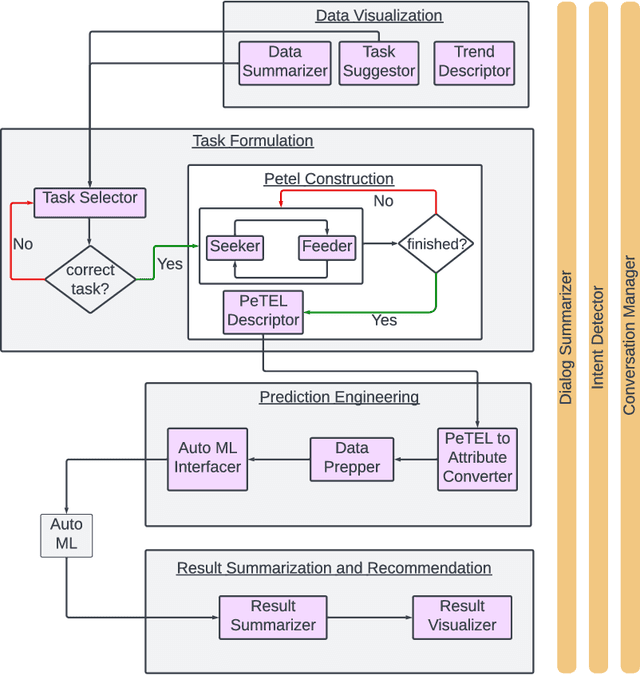

The rise of big data has amplified the need for efficient, user-friendly automated machine learning (AutoML) tools. However, the intricacy of understanding domain-specific data and defining prediction tasks necessitates human intervention making the process time-consuming while preventing full automation. Instead, envision an intelligent agent capable of assisting users in conducting AutoML tasks through intuitive, natural conversations without requiring in-depth knowledge of the underlying machine learning (ML) processes. This agent's key challenge is to accurately comprehend the user's prediction goals and, consequently, formulate precise ML tasks, adjust data sets and model parameters accordingly, and articulate results effectively. In this paper, we take a pioneering step towards this ambitious goal by introducing a ChatGPT-based conversational data-science framework to act as a "personal data scientist". Precisely, we utilize Large Language Models (ChatGPT) to build a natural interface between the users and the ML models (Scikit-Learn), which in turn, allows us to approach this ambitious problem with a realistic solution. Our model pivots around four dialogue states: Data Visualization, Task Formulation, Prediction Engineering, and Result Summary and Recommendation. Each state marks a unique conversation phase, impacting the overall user-system interaction. Multiple LLM instances, serving as "micro-agents", ensure a cohesive conversation flow, granting us granular control over the conversation's progression. In summary, we developed an end-to-end system that not only proves the viability of the novel concept of conversational data science but also underscores the potency of LLMs in solving complex tasks. Interestingly, its development spotlighted several critical weaknesses in the current LLMs (ChatGPT) and highlighted substantial opportunities for improvement.
TELeR: A General Taxonomy of LLM Prompts for Benchmarking Complex Tasks
May 19, 2023
While LLMs have shown great success in understanding and generating text in traditional conversational settings, their potential for performing ill-defined complex tasks is largely under-studied. Indeed, we are yet to conduct comprehensive benchmarking studies with multiple LLMs that are exclusively focused on a complex task. However, conducting such benchmarking studies is challenging because of the large variations in LLMs' performance when different prompt types/styles are used and different degrees of detail are provided in the prompts. To address this issue, the paper proposes a general taxonomy that can be used to design prompts with specific properties in order to perform a wide range of complex tasks. This taxonomy will allow future benchmarking studies to report the specific categories of prompts used as part of the study, enabling meaningful comparisons across different studies. Also, by establishing a common standard through this taxonomy, researchers will be able to draw more accurate conclusions about LLMs' performance on a specific complex task.
Exploring Challenges of Deploying BERT-based NLP Models in Resource-Constrained Embedded Devices
Apr 23, 2023



BERT-based neural architectures have established themselves as popular state-of-the-art baselines for many downstream NLP tasks. However, these architectures are data-hungry and consume a lot of memory and energy, often hindering their deployment in many real-time, resource-constrained applications. Existing lighter versions of BERT (eg. DistilBERT and TinyBERT) often cannot perform well on complex NLP tasks. More importantly, from a designer's perspective, it is unclear what is the "right" BERT-based architecture to use for a given NLP task that can strike the optimal trade-off between the resources available and the minimum accuracy desired by the end user. System engineers have to spend a lot of time conducting trial-and-error experiments to find a suitable answer to this question. This paper presents an exploratory study of BERT-based models under different resource constraints and accuracy budgets to derive empirical observations about this resource/accuracy trade-offs. Our findings can help designers to make informed choices among alternative BERT-based architectures for embedded systems, thus saving significant development time and effort.
Zero-Shot Multi-Label Topic Inference with Sentence Encoders
Apr 14, 2023



Sentence encoders have indeed been shown to achieve superior performances for many downstream text-mining tasks and, thus, claimed to be fairly general. Inspired by this, we performed a detailed study on how to leverage these sentence encoders for the "zero-shot topic inference" task, where the topics are defined/provided by the users in real-time. Extensive experiments on seven different datasets demonstrate that Sentence-BERT demonstrates superior generality compared to other encoders, while Universal Sentence Encoder can be preferred when efficiency is a top priority.
On Evaluation of Bangla Word Analogies
Apr 10, 2023



This paper presents a high-quality dataset for evaluating the quality of Bangla word embeddings, which is a fundamental task in the field of Natural Language Processing (NLP). Despite being the 7th most-spoken language in the world, Bangla is a low-resource language and popular NLP models fail to perform well. Developing a reliable evaluation test set for Bangla word embeddings are crucial for benchmarking and guiding future research. We provide a Mikolov-style word analogy evaluation set specifically for Bangla, with a sample size of 16678, as well as a translated and curated version of the Mikolov dataset, which contains 10594 samples for cross-lingual research. Our experiments with different state-of-the-art embedding models reveal that Bangla has its own unique characteristics, and current embeddings for Bangla still struggle to achieve high accuracy on both datasets. We suggest that future research should focus on training models with larger datasets and considering the unique morphological characteristics of Bangla. This study represents the first step towards building a reliable NLP system for the Bangla language1.