 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSet-Theoretic Compositionality of Sentence Embeddings
Feb 28, 2025Sentence encoders play a pivotal role in various NLP tasks; hence, an accurate evaluation of their compositional properties is paramount. However, existing evaluation methods predominantly focus on goal task-specific performance. This leaves a significant gap in understanding how well sentence embeddings demonstrate fundamental compositional properties in a task-independent context. Leveraging classical set theory, we address this gap by proposing six criteria based on three core "set-like" compositions/operations: \textit{TextOverlap}, \textit{TextDifference}, and \textit{TextUnion}. We systematically evaluate $7$ classical and $9$ Large Language Model (LLM)-based sentence encoders to assess their alignment with these criteria. Our findings show that SBERT consistently demonstrates set-like compositional properties, surpassing even the latest LLMs. Additionally, we introduce a new dataset of ~$192$K samples designed to facilitate future benchmarking efforts on set-like compositionality of sentence embeddings.
Benchmarking LLMs on the Semantic Overlap Summarization Task
Feb 26, 2024



Semantic Overlap Summarization (SOS) is a constrained multi-document summarization task, where the constraint is to capture the common/overlapping information between two alternative narratives. While recent advancements in Large Language Models (LLMs) have achieved superior performance in numerous summarization tasks, a benchmarking study of the SOS task using LLMs is yet to be performed. As LLMs' responses are sensitive to slight variations in prompt design, a major challenge in conducting such a benchmarking study is to systematically explore a variety of prompts before drawing a reliable conclusion. Fortunately, very recently, the TELeR taxonomy has been proposed which can be used to design and explore various prompts for LLMs. Using this TELeR taxonomy and 15 popular LLMs, this paper comprehensively evaluates LLMs on the SOS Task, assessing their ability to summarize overlapping information from multiple alternative narratives. For evaluation, we report well-established metrics like ROUGE, BERTscore, and SEM-F1$ on two different datasets of alternative narratives. We conclude the paper by analyzing the strengths and limitations of various LLMs in terms of their capabilities in capturing overlapping information The code and datasets used to conduct this study are available at https://anonymous.4open.science/r/llm_eval-E16D.
Prompting LLMs to Compose Meta-Review Drafts from Peer-Review Narratives of Scholarly Manuscripts
Feb 23, 2024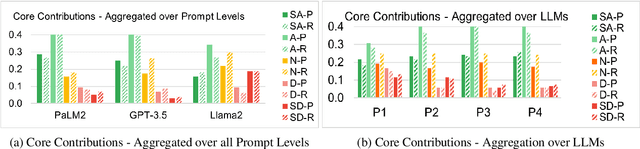



One of the most important yet onerous tasks in the academic peer-reviewing process is composing meta-reviews, which involves understanding the core contributions, strengths, and weaknesses of a scholarly manuscript based on peer-review narratives from multiple experts and then summarizing those multiple experts' perspectives into a concise holistic overview. Given the latest major developments in generative AI, especially Large Language Models (LLMs), it is very compelling to rigorously study the utility of LLMs in generating such meta-reviews in an academic peer-review setting. In this paper, we perform a case study with three popular LLMs, i.e., GPT-3.5, LLaMA2, and PaLM2, to automatically generate meta-reviews by prompting them with different types/levels of prompts based on the recently proposed TELeR taxonomy. Finally, we perform a detailed qualitative study of the meta-reviews generated by the LLMs and summarize our findings and recommendations for prompting LLMs for this complex task.
The Daunting Dilemma with Sentence Encoders: Success on Standard Benchmarks, Failure in Capturing Basic Semantic Properties
Sep 07, 2023
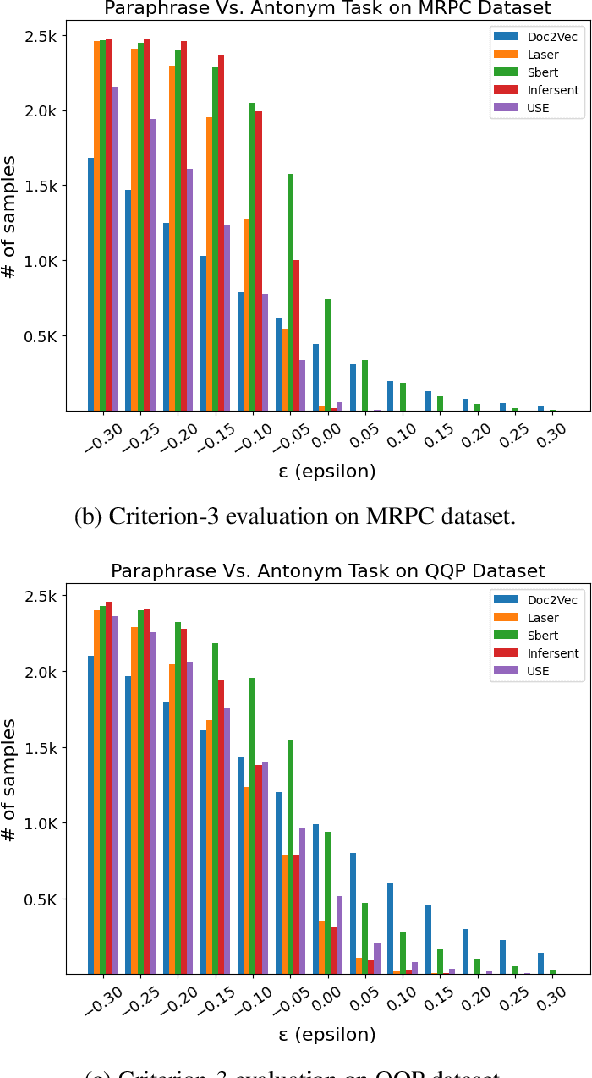

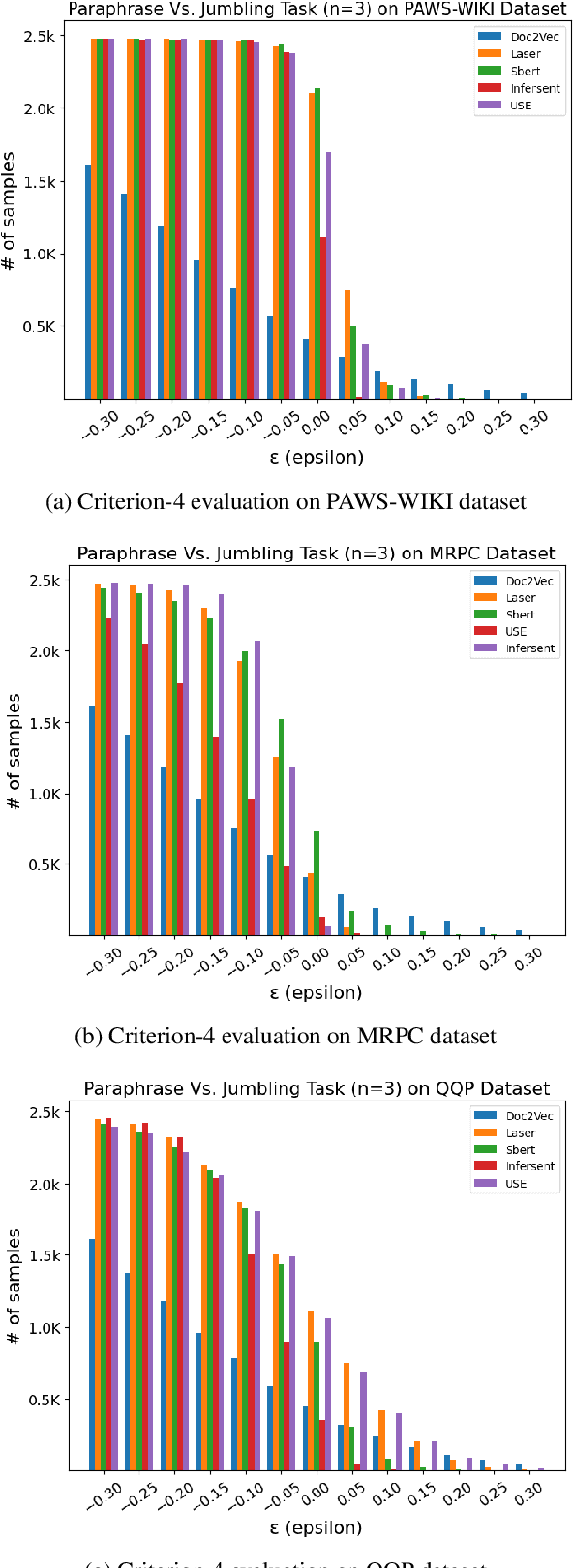
In this paper, we adopted a retrospective approach to examine and compare five existing popular sentence encoders, i.e., Sentence-BERT, Universal Sentence Encoder (USE), LASER, InferSent, and Doc2vec, in terms of their performance on downstream tasks versus their capability to capture basic semantic properties. Initially, we evaluated all five sentence encoders on the popular SentEval benchmark and found that multiple sentence encoders perform quite well on a variety of popular downstream tasks. However, being unable to find a single winner in all cases, we designed further experiments to gain a deeper understanding of their behavior. Specifically, we proposed four semantic evaluation criteria, i.e., Paraphrasing, Synonym Replacement, Antonym Replacement, and Sentence Jumbling, and evaluated the same five sentence encoders using these criteria. We found that the Sentence-Bert and USE models pass the paraphrasing criterion, with SBERT being the superior between the two. LASER dominates in the case of the synonym replacement criterion. Interestingly, all the sentence encoders failed the antonym replacement and jumbling criteria. These results suggest that although these popular sentence encoders perform quite well on the SentEval benchmark, they still struggle to capture some basic semantic properties, thus, posing a daunting dilemma in NLP research.
Multi-Narrative Semantic Overlap Task: Evaluation and Benchmark
Jan 14, 2022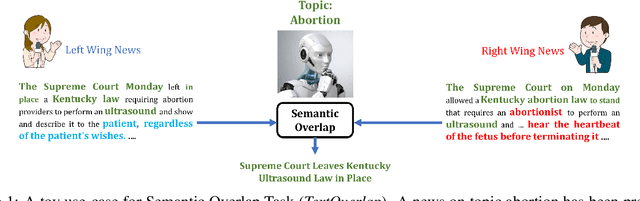

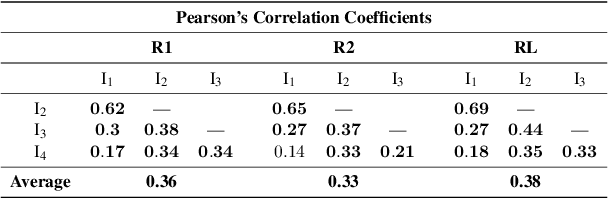

In this paper, we introduce an important yet relatively unexplored NLP task called Multi-Narrative Semantic Overlap (MNSO), which entails generating a Semantic Overlap of multiple alternate narratives. As no benchmark dataset is readily available for this task, we created one by crawling 2,925 narrative pairs from the web and then, went through the tedious process of manually creating 411 different ground-truth semantic overlaps by engaging human annotators. As a way to evaluate this novel task, we first conducted a systematic study by borrowing the popular ROUGE metric from text-summarization literature and discovered that ROUGE is not suitable for our task. Subsequently, we conducted further human annotations/validations to create 200 document-level and 1,518 sentence-level ground-truth labels which helped us formulate a new precision-recall style evaluation metric, called SEM-F1 (semantic F1). Experimental results show that the proposed SEM-F1 metric yields higher correlation with human judgement as well as higher inter-rater-agreement compared to ROUGE metric.
SAM: The Sensitivity of Attribution Methods to Hyperparameters
Apr 13, 2020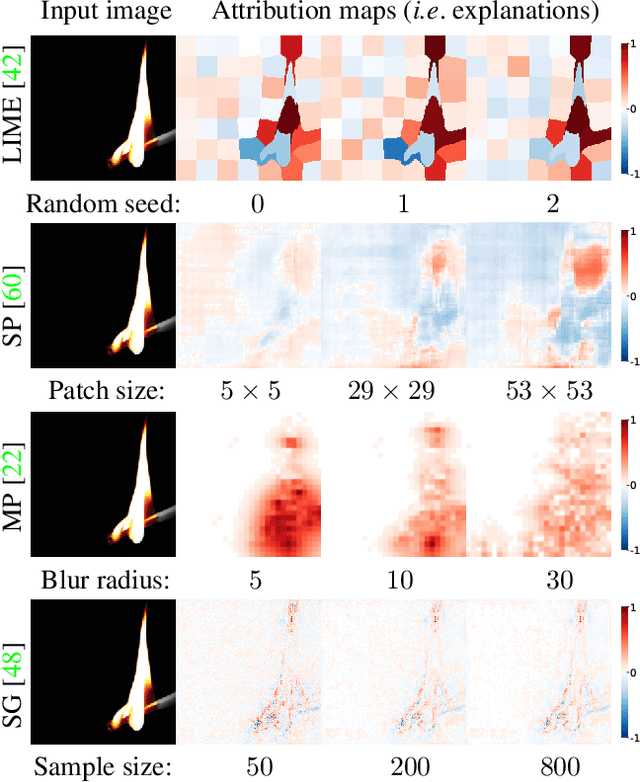
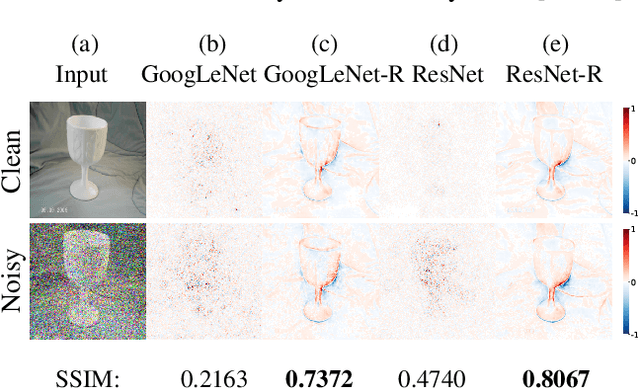
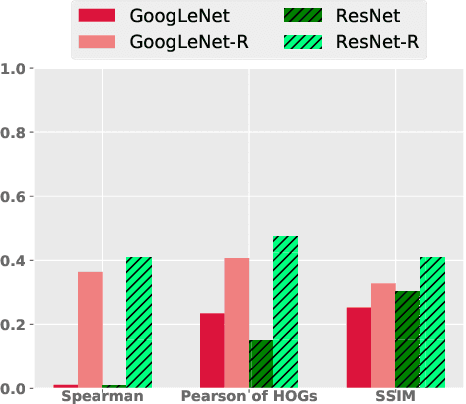

Attribution methods can provide powerful insights into the reasons for a classifier's decision. We argue that a key desideratum of an explanation method is its robustness to input hyperparameters which are often randomly set or empirically tuned. High sensitivity to arbitrary hyperparameter choices does not only impede reproducibility but also questions the correctness of an explanation and impairs the trust of end-users. In this paper, we provide a thorough empirical study on the sensitivity of existing attribution methods. We found an alarming trend that many methods are highly sensitive to changes in their common hyperparameters e.g. even changing a random seed can yield a different explanation! Interestingly, such sensitivity is not reflected in the average explanation accuracy scores over the dataset as commonly reported in the literature. In addition, explanations generated for robust classifiers (i.e. which are trained to be invariant to pixel-wise perturbations) are surprisingly more robust than those generated for regular classifiers.