 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLMs on the Semantic Overlap Summarization Task
Feb 26, 2024



Semantic Overlap Summarization (SOS) is a constrained multi-document summarization task, where the constraint is to capture the common/overlapping information between two alternative narratives. While recent advancements in Large Language Models (LLMs) have achieved superior performance in numerous summarization tasks, a benchmarking study of the SOS task using LLMs is yet to be performed. As LLMs' responses are sensitive to slight variations in prompt design, a major challenge in conducting such a benchmarking study is to systematically explore a variety of prompts before drawing a reliable conclusion. Fortunately, very recently, the TELeR taxonomy has been proposed which can be used to design and explore various prompts for LLMs. Using this TELeR taxonomy and 15 popular LLMs, this paper comprehensively evaluates LLMs on the SOS Task, assessing their ability to summarize overlapping information from multiple alternative narratives. For evaluation, we report well-established metrics like ROUGE, BERTscore, and SEM-F1$ on two different datasets of alternative narratives. We conclude the paper by analyzing the strengths and limitations of various LLMs in terms of their capabilities in capturing overlapping information The code and datasets used to conduct this study are available at https://anonymous.4open.science/r/llm_eval-E16D.
LLMs as On-demand Customizable Service
Jan 29, 2024Large Language Models (LLMs) have demonstrated remarkable language understanding and generation capabilities. However, training, deploying, and accessing these models pose notable challenges, including resource-intensive demands, extended training durations, and scalability issues. To address these issues, we introduce a concept of hierarchical, distributed LLM architecture that aims at enhancing the accessibility and deployability of LLMs across heterogeneous computing platforms, including general-purpose computers (e.g., laptops) and IoT-style devices (e.g., embedded systems). By introducing a "layered" approach, the proposed architecture enables on-demand accessibility to LLMs as a customizable service. This approach also ensures optimal trade-offs between the available computational resources and the user's application needs. We envision that the concept of hierarchical LLM will empower extensive, crowd-sourced user bases to harness the capabilities of LLMs, thereby fostering advancements in AI technology in general.
The Daunting Dilemma with Sentence Encoders: Success on Standard Benchmarks, Failure in Capturing Basic Semantic Properties
Sep 07, 2023
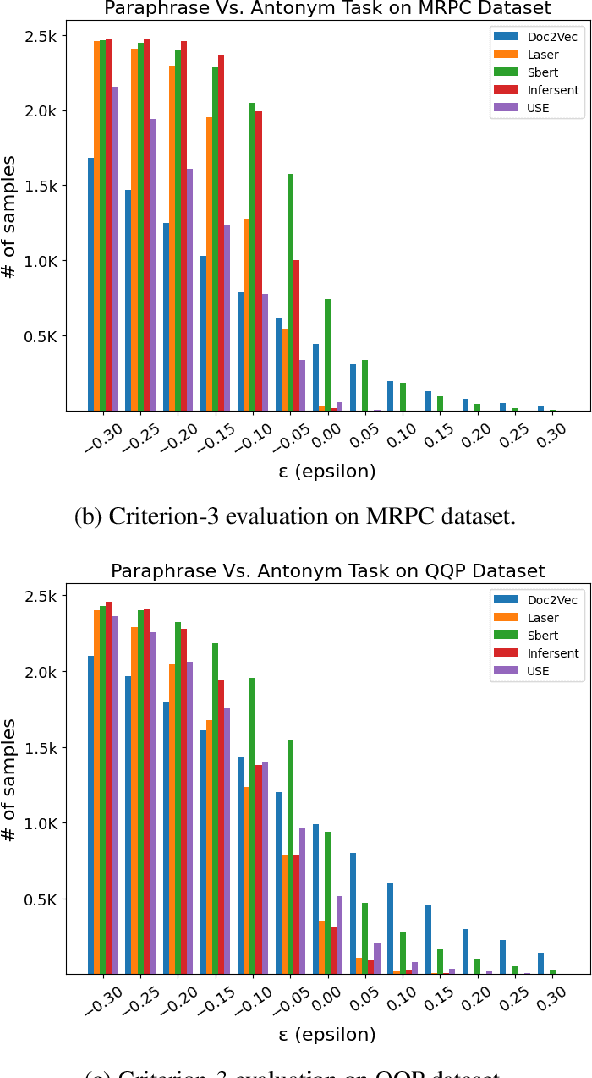

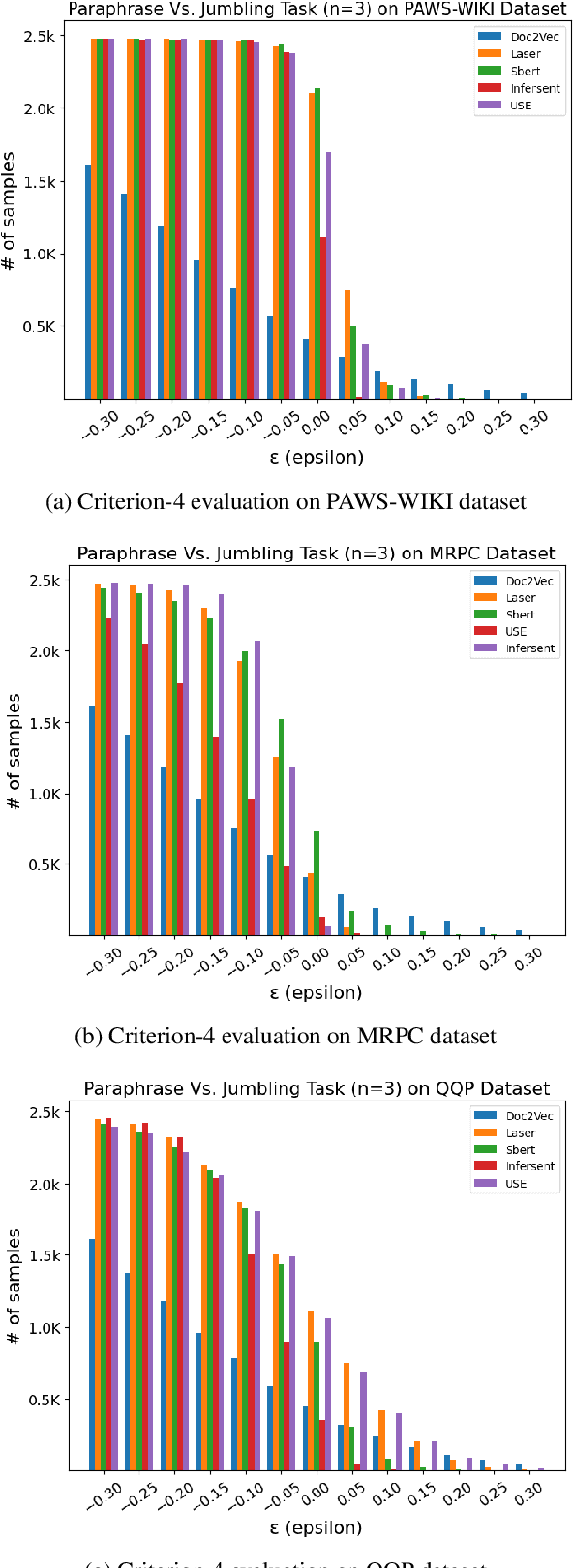
In this paper, we adopted a retrospective approach to examine and compare five existing popular sentence encoders, i.e., Sentence-BERT, Universal Sentence Encoder (USE), LASER, InferSent, and Doc2vec, in terms of their performance on downstream tasks versus their capability to capture basic semantic properties. Initially, we evaluated all five sentence encoders on the popular SentEval benchmark and found that multiple sentence encoders perform quite well on a variety of popular downstream tasks. However, being unable to find a single winner in all cases, we designed further experiments to gain a deeper understanding of their behavior. Specifically, we proposed four semantic evaluation criteria, i.e., Paraphrasing, Synonym Replacement, Antonym Replacement, and Sentence Jumbling, and evaluated the same five sentence encoders using these criteria. We found that the Sentence-Bert and USE models pass the paraphrasing criterion, with SBERT being the superior between the two. LASER dominates in the case of the synonym replacement criterion. Interestingly, all the sentence encoders failed the antonym replacement and jumbling criteria. These results suggest that although these popular sentence encoders perform quite well on the SentEval benchmark, they still struggle to capture some basic semantic properties, thus, posing a daunting dilemma in NLP research.
Introducing "Forecast Utterance" for Conversational Data Science
Sep 07, 2023Envision an intelligent agent capable of assisting users in conducting forecasting tasks through intuitive, natural conversations, without requiring in-depth knowledge of the underlying machine learning (ML) processes. A significant challenge for the agent in this endeavor is to accurately comprehend the user's prediction goals and, consequently, formulate precise ML tasks. In this paper, we take a pioneering step towards this ambitious goal by introducing a new concept called Forecast Utterance and then focus on the automatic and accurate interpretation of users' prediction goals from these utterances. Specifically, we frame the task as a slot-filling problem, where each slot corresponds to a specific aspect of the goal prediction task. We then employ two zero-shot methods for solving the slot-filling task, namely: 1) Entity Extraction (EE), and 2) Question-Answering (QA) techniques. Our experiments, conducted with three meticulously crafted data sets, validate the viability of our ambitious goal and demonstrate the effectiveness of both EE and QA techniques in interpreting Forecast Utterances.