 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Legal Summarization: Challenges and Future Directions
Jan 29, 2025


This article provides a systematic up-to-date survey of automatic summarization techniques, datasets, models, and evaluation methods in the legal domain. Through specific source selection criteria, we thoroughly review over 120 papers spanning the modern `transformer' era of natural language processing (NLP), thus filling a gap in existing systematic surveys on the matter. We present existing research along several axes and discuss trends, challenges, and opportunities for future research.
Benchmarking LLMs on the Semantic Overlap Summarization Task
Feb 26, 2024



Semantic Overlap Summarization (SOS) is a constrained multi-document summarization task, where the constraint is to capture the common/overlapping information between two alternative narratives. While recent advancements in Large Language Models (LLMs) have achieved superior performance in numerous summarization tasks, a benchmarking study of the SOS task using LLMs is yet to be performed. As LLMs' responses are sensitive to slight variations in prompt design, a major challenge in conducting such a benchmarking study is to systematically explore a variety of prompts before drawing a reliable conclusion. Fortunately, very recently, the TELeR taxonomy has been proposed which can be used to design and explore various prompts for LLMs. Using this TELeR taxonomy and 15 popular LLMs, this paper comprehensively evaluates LLMs on the SOS Task, assessing their ability to summarize overlapping information from multiple alternative narratives. For evaluation, we report well-established metrics like ROUGE, BERTscore, and SEM-F1$ on two different datasets of alternative narratives. We conclude the paper by analyzing the strengths and limitations of various LLMs in terms of their capabilities in capturing overlapping information The code and datasets used to conduct this study are available at https://anonymous.4open.science/r/llm_eval-E16D.
Prompting LLMs to Compose Meta-Review Drafts from Peer-Review Narratives of Scholarly Manuscripts
Feb 23, 2024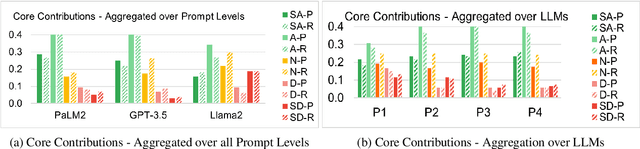



One of the most important yet onerous tasks in the academic peer-reviewing process is composing meta-reviews, which involves understanding the core contributions, strengths, and weaknesses of a scholarly manuscript based on peer-review narratives from multiple experts and then summarizing those multiple experts' perspectives into a concise holistic overview. Given the latest major developments in generative AI, especially Large Language Models (LLMs), it is very compelling to rigorously study the utility of LLMs in generating such meta-reviews in an academic peer-review setting. In this paper, we perform a case study with three popular LLMs, i.e., GPT-3.5, LLaMA2, and PaLM2, to automatically generate meta-reviews by prompting them with different types/levels of prompts based on the recently proposed TELeR taxonomy. Finally, we perform a detailed qualitative study of the meta-reviews generated by the LLMs and summarize our findings and recommendations for prompting LLMs for this complex task.
FaNS: a Facet-based Narrative Similarity Metric
Sep 09, 2023
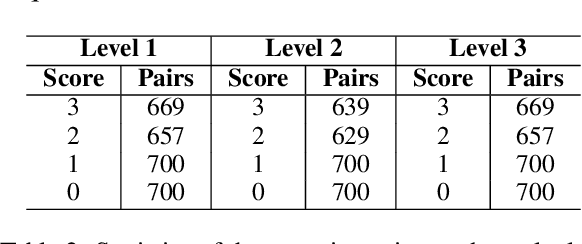

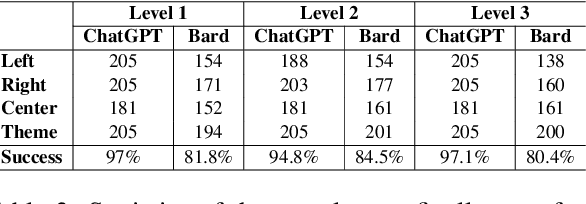
Similar Narrative Retrieval is a crucial task since narratives are essential for explaining and understanding events, and multiple related narratives often help to create a holistic view of the event of interest. To accurately identify semantically similar narratives, this paper proposes a novel narrative similarity metric called Facet-based Narrative Similarity (FaNS), based on the classic 5W1H facets (Who, What, When, Where, Why, and How), which are extracted by leveraging the state-of-the-art Large Language Models (LLMs). Unlike existing similarity metrics that only focus on overall lexical/semantic match, FaNS provides a more granular matching along six different facets independently and then combines them. To evaluate FaNS, we created a comprehensive dataset by collecting narratives from AllSides, a third-party news portal. Experimental results demonstrate that the FaNS metric exhibits a higher correlation (37\% higher) than traditional text similarity metrics that directly measure the lexical/semantic match between narratives, demonstrating its effectiveness in comparing the finer details between a pair of narratives.
Redundancy Aware Multi-Reference Based Gainwise Evaluation of Extractive Summarization
Aug 04, 2023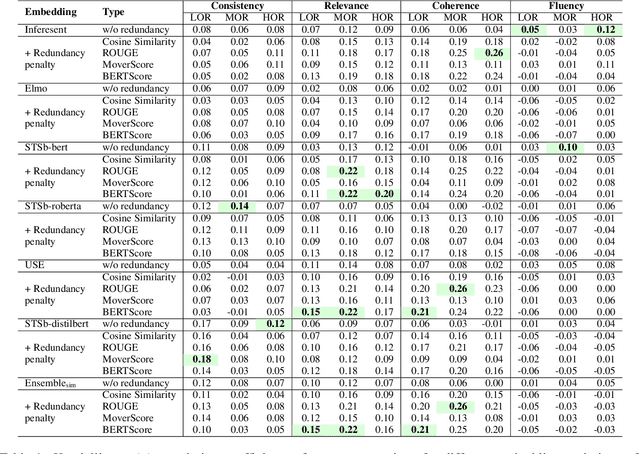
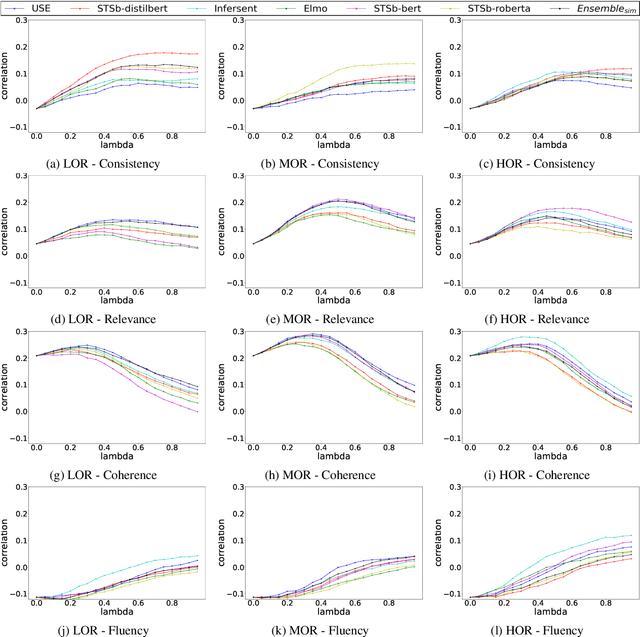

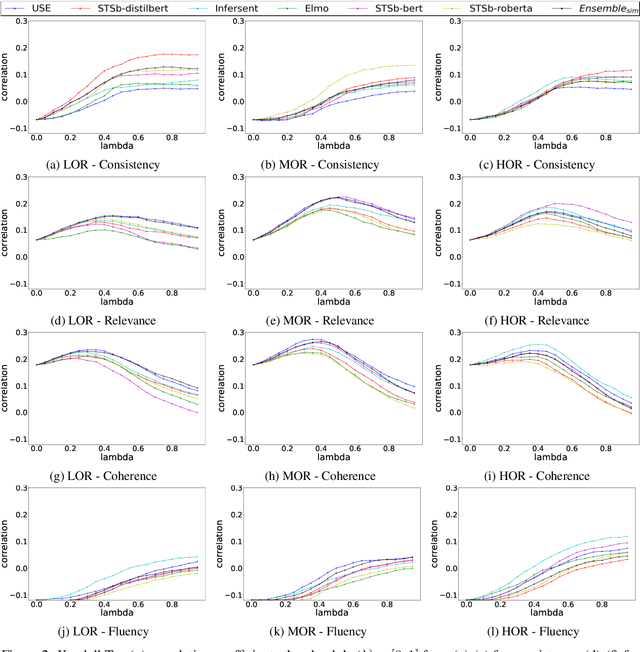
While very popular for evaluating extractive summarization task, the ROUGE metric has long been criticized for its lack of semantic awareness and its ignorance about the ranking quality of the summarizer. Thanks to previous research that has addressed these issues by proposing a gain-based automated metric called Sem-nCG, which is both rank and semantic aware. However, Sem-nCG does not consider the amount of redundancy present in a model-generated summary and currently does not support evaluation with multiple reference summaries. Unfortunately, addressing both these limitations simultaneously is not trivial. Therefore, in this paper, we propose a redundancy-aware Sem-nCG metric and demonstrate how this new metric can be used to evaluate model summaries against multiple references. We also explore different ways of incorporating redundancy into the original metric through extensive experiments. Experimental results demonstrate that the new redundancy-aware metric exhibits a higher correlation with human judgments than the original Sem-nCG metric for both single and multiple reference scenarios.
On Evaluation of Bangla Word Analogies
Apr 10, 2023



This paper presents a high-quality dataset for evaluating the quality of Bangla word embeddings, which is a fundamental task in the field of Natural Language Processing (NLP). Despite being the 7th most-spoken language in the world, Bangla is a low-resource language and popular NLP models fail to perform well. Developing a reliable evaluation test set for Bangla word embeddings are crucial for benchmarking and guiding future research. We provide a Mikolov-style word analogy evaluation set specifically for Bangla, with a sample size of 16678, as well as a translated and curated version of the Mikolov dataset, which contains 10594 samples for cross-lingual research. Our experiments with different state-of-the-art embedding models reveal that Bangla has its own unique characteristics, and current embeddings for Bangla still struggle to achieve high accuracy on both datasets. We suggest that future research should focus on training models with larger datasets and considering the unique morphological characteristics of Bangla. This study represents the first step towards building a reliable NLP system for the Bangla language1.
Multi-Narrative Semantic Overlap Task: Evaluation and Benchmark
Jan 14, 2022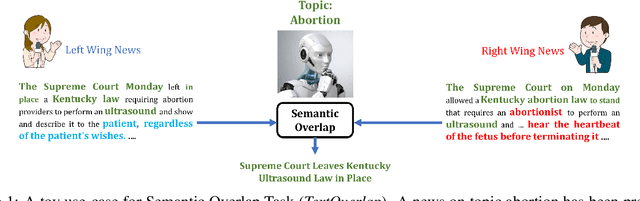

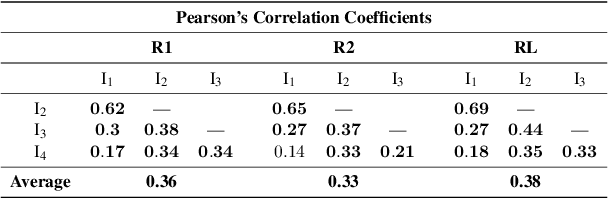

In this paper, we introduce an important yet relatively unexplored NLP task called Multi-Narrative Semantic Overlap (MNSO), which entails generating a Semantic Overlap of multiple alternate narratives. As no benchmark dataset is readily available for this task, we created one by crawling 2,925 narrative pairs from the web and then, went through the tedious process of manually creating 411 different ground-truth semantic overlaps by engaging human annotators. As a way to evaluate this novel task, we first conducted a systematic study by borrowing the popular ROUGE metric from text-summarization literature and discovered that ROUGE is not suitable for our task. Subsequently, we conducted further human annotations/validations to create 200 document-level and 1,518 sentence-level ground-truth labels which helped us formulate a new precision-recall style evaluation metric, called SEM-F1 (semantic F1). Experimental results show that the proposed SEM-F1 metric yields higher correlation with human judgement as well as higher inter-rater-agreement compared to ROUGE metric.