 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Word Embeddings in the LLM Era
Feb 26, 2025Large Language Models (LLMs) have recently shown remarkable advancement in various NLP tasks. As such, a popular trend has emerged lately where NLP researchers extract word/sentence/document embeddings from these large decoder-only models and use them for various inference tasks with promising results. However, it is still unclear whether the performance improvement of LLM-induced embeddings is merely because of scale or whether underlying embeddings they produce significantly differ from classical encoding models like Word2Vec, GloVe, Sentence-BERT (SBERT) or Universal Sentence Encoder (USE). This is the central question we investigate in the paper by systematically comparing classical decontextualized and contextualized word embeddings with the same for LLM-induced embeddings. Our results show that LLMs cluster semantically related words more tightly and perform better on analogy tasks in decontextualized settings. However, in contextualized settings, classical models like SimCSE often outperform LLMs in sentence-level similarity assessment tasks, highlighting their continued relevance for fine-grained semantics.
Prompting LLMs to Compose Meta-Review Drafts from Peer-Review Narratives of Scholarly Manuscripts
Feb 23, 2024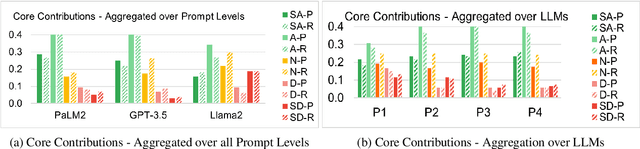



One of the most important yet onerous tasks in the academic peer-reviewing process is composing meta-reviews, which involves understanding the core contributions, strengths, and weaknesses of a scholarly manuscript based on peer-review narratives from multiple experts and then summarizing those multiple experts' perspectives into a concise holistic overview. Given the latest major developments in generative AI, especially Large Language Models (LLMs), it is very compelling to rigorously study the utility of LLMs in generating such meta-reviews in an academic peer-review setting. In this paper, we perform a case study with three popular LLMs, i.e., GPT-3.5, LLaMA2, and PaLM2, to automatically generate meta-reviews by prompting them with different types/levels of prompts based on the recently proposed TELeR taxonomy. Finally, we perform a detailed qualitative study of the meta-reviews generated by the LLMs and summarize our findings and recommendations for prompting LLMs for this complex task.
Word Embeddings Revisited: Do LLMs Offer Something New?
Feb 16, 2024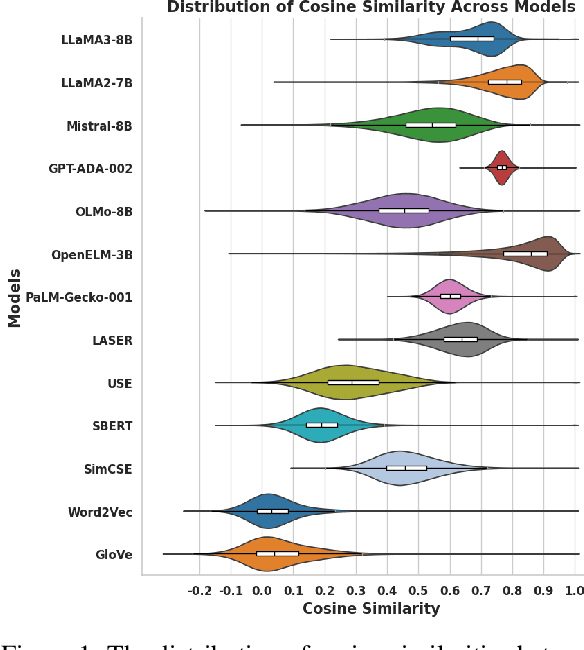
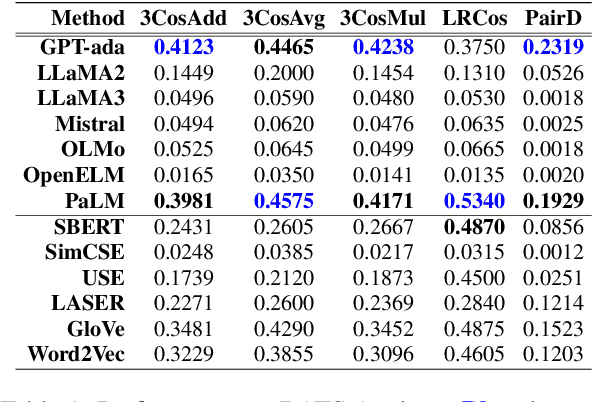
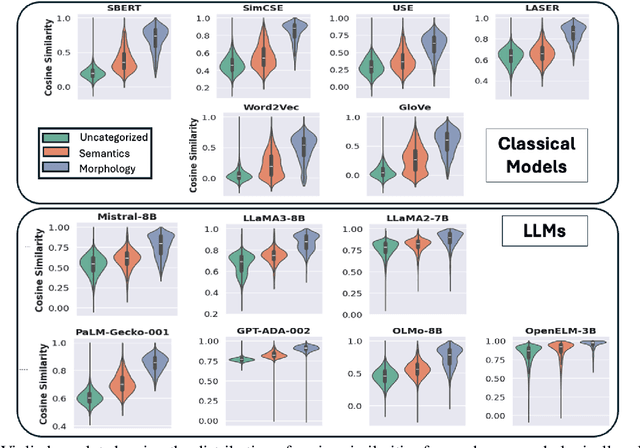
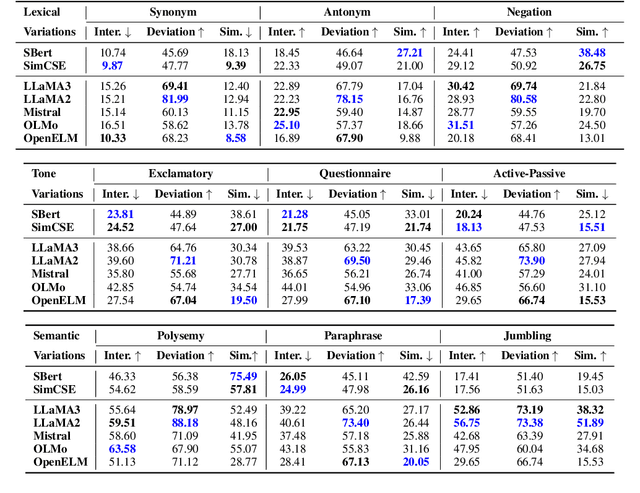
Learning meaningful word embeddings is key to training a robust language model. The recent rise of Large Language Models (LLMs) has provided us with many new word/sentence/document embedding models. Although LLMs have shown remarkable advancement in various NLP tasks, it is still unclear whether the performance improvement is merely because of scale or whether underlying embeddings they produce significantly differ from classical encoding models like Sentence-BERT (SBERT) or Universal Sentence Encoder (USE). This paper systematically investigates this issue by comparing classical word embedding techniques against LLM-based word embeddings in terms of their latent vector semantics. Our results show that LLMs tend to cluster semantically related words more tightly than classical models. LLMs also yield higher average accuracy on the Bigger Analogy Test Set (BATS) over classical methods. Finally, some LLMs tend to produce word embeddings similar to SBERT, a relatively lighter classical model.