 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Narrative Semantic Overlap Task: Evaluation and Benchmark
Paper and Code
Jan 14, 2022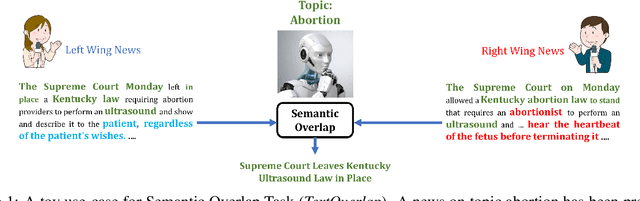

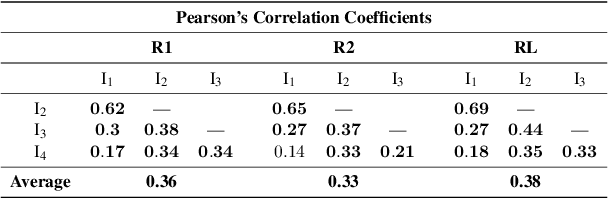

In this paper, we introduce an important yet relatively unexplored NLP task called Multi-Narrative Semantic Overlap (MNSO), which entails generating a Semantic Overlap of multiple alternate narratives. As no benchmark dataset is readily available for this task, we created one by crawling 2,925 narrative pairs from the web and then, went through the tedious process of manually creating 411 different ground-truth semantic overlaps by engaging human annotators. As a way to evaluate this novel task, we first conducted a systematic study by borrowing the popular ROUGE metric from text-summarization literature and discovered that ROUGE is not suitable for our task. Subsequently, we conducted further human annotations/validations to create 200 document-level and 1,518 sentence-level ground-truth labels which helped us formulate a new precision-recall style evaluation metric, called SEM-F1 (semantic F1). Experimental results show that the proposed SEM-F1 metric yields higher correlation with human judgement as well as higher inter-rater-agreement compared to ROUGE metric.