 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for IT Automation Tasks: Are We There Yet?
May 26, 2025LLMs show promise in code generation, yet their effectiveness for IT automation tasks, particularly for tools like Ansible, remains understudied. Existing benchmarks rely primarily on synthetic tasks that fail to capture the needs of practitioners who use IT automation tools, such as Ansible. We present ITAB (IT Automation Task Benchmark), a benchmark of 126 diverse tasks (e.g., configuring servers, managing files) where each task accounts for state reconciliation: a property unique to IT automation tools. ITAB evaluates LLMs' ability to generate functional Ansible automation scripts via dynamic execution in controlled environments. We evaluate 14 open-source LLMs, none of which accomplish pass@10 at a rate beyond 12%. To explain these low scores, we analyze 1,411 execution failures across the evaluated LLMs and identify two main categories of prevalent semantic errors: failures in state reconciliation related reasoning (44.87% combined from variable (11.43%), host (11.84%), path(11.63%), and template (9.97%) issues) and deficiencies in module-specific execution knowledge (24.37% combined from Attribute and parameter (14.44%) and module (9.93%) errors). Our findings reveal key limitations in open-source LLMs' ability to track state changes and apply specialized module knowledge, indicating that reliable IT automation will require major advances in state reasoning and domain-specific execution understanding.
Introducing "Forecast Utterance" for Conversational Data Science
Sep 07, 2023Envision an intelligent agent capable of assisting users in conducting forecasting tasks through intuitive, natural conversations, without requiring in-depth knowledge of the underlying machine learning (ML) processes. A significant challenge for the agent in this endeavor is to accurately comprehend the user's prediction goals and, consequently, formulate precise ML tasks. In this paper, we take a pioneering step towards this ambitious goal by introducing a new concept called Forecast Utterance and then focus on the automatic and accurate interpretation of users' prediction goals from these utterances. Specifically, we frame the task as a slot-filling problem, where each slot corresponds to a specific aspect of the goal prediction task. We then employ two zero-shot methods for solving the slot-filling task, namely: 1) Entity Extraction (EE), and 2) Question-Answering (QA) techniques. Our experiments, conducted with three meticulously crafted data sets, validate the viability of our ambitious goal and demonstrate the effectiveness of both EE and QA techniques in interpreting Forecast Utterances.
ChatGPT as your Personal Data Scientist
May 23, 2023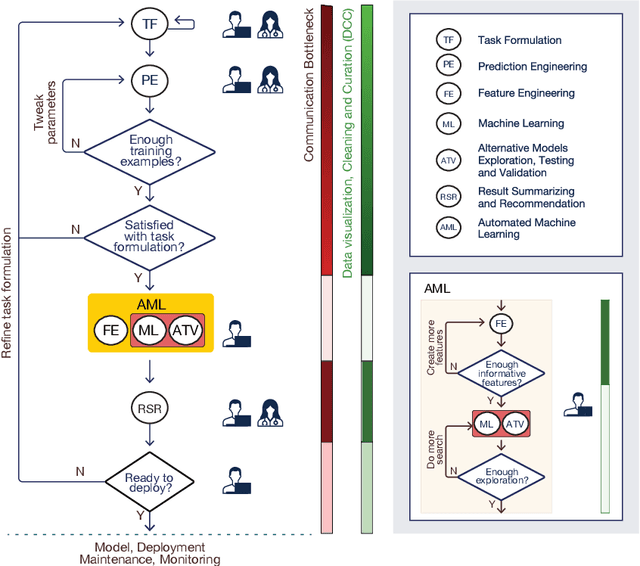

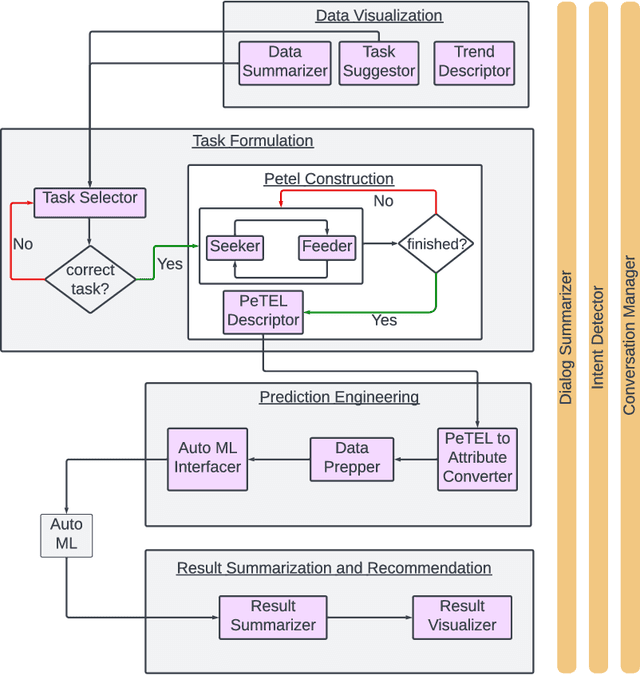

The rise of big data has amplified the need for efficient, user-friendly automated machine learning (AutoML) tools. However, the intricacy of understanding domain-specific data and defining prediction tasks necessitates human intervention making the process time-consuming while preventing full automation. Instead, envision an intelligent agent capable of assisting users in conducting AutoML tasks through intuitive, natural conversations without requiring in-depth knowledge of the underlying machine learning (ML) processes. This agent's key challenge is to accurately comprehend the user's prediction goals and, consequently, formulate precise ML tasks, adjust data sets and model parameters accordingly, and articulate results effectively. In this paper, we take a pioneering step towards this ambitious goal by introducing a ChatGPT-based conversational data-science framework to act as a "personal data scientist". Precisely, we utilize Large Language Models (ChatGPT) to build a natural interface between the users and the ML models (Scikit-Learn), which in turn, allows us to approach this ambitious problem with a realistic solution. Our model pivots around four dialogue states: Data Visualization, Task Formulation, Prediction Engineering, and Result Summary and Recommendation. Each state marks a unique conversation phase, impacting the overall user-system interaction. Multiple LLM instances, serving as "micro-agents", ensure a cohesive conversation flow, granting us granular control over the conversation's progression. In summary, we developed an end-to-end system that not only proves the viability of the novel concept of conversational data science but also underscores the potency of LLMs in solving complex tasks. Interestingly, its development spotlighted several critical weaknesses in the current LLMs (ChatGPT) and highlighted substantial opportunities for improvement.
Exploring Challenges of Deploying BERT-based NLP Models in Resource-Constrained Embedded Devices
Apr 23, 2023



BERT-based neural architectures have established themselves as popular state-of-the-art baselines for many downstream NLP tasks. However, these architectures are data-hungry and consume a lot of memory and energy, often hindering their deployment in many real-time, resource-constrained applications. Existing lighter versions of BERT (eg. DistilBERT and TinyBERT) often cannot perform well on complex NLP tasks. More importantly, from a designer's perspective, it is unclear what is the "right" BERT-based architecture to use for a given NLP task that can strike the optimal trade-off between the resources available and the minimum accuracy desired by the end user. System engineers have to spend a lot of time conducting trial-and-error experiments to find a suitable answer to this question. This paper presents an exploratory study of BERT-based models under different resource constraints and accuracy budgets to derive empirical observations about this resource/accuracy trade-offs. Our findings can help designers to make informed choices among alternative BERT-based architectures for embedded systems, thus saving significant development time and effort.