 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClutter-Resistant Vision-Language-Action Models through Object-Centric and Geometry Grounding
Dec 27, 2025Recent Vision-Language-Action (VLA) models have made impressive progress toward general-purpose robotic manipulation by post-training large Vision-Language Models (VLMs) for action prediction. Yet most VLAs entangle perception and control in a monolithic pipeline optimized purely for action, which can erode language-conditioned grounding. In our real-world tabletop tests, policies over-grasp when the target is absent, are distracted by clutter, and overfit to background appearance. To address these issues, we propose OBEYED-VLA (OBject-centric and gEometrY groundED VLA), a framework that explicitly disentangles perceptual grounding from action reasoning. Instead of operating directly on raw RGB, OBEYED-VLA augments VLAs with a perception module that grounds multi-view inputs into task-conditioned, object-centric, and geometry-aware observations. This module includes a VLM-based object-centric grounding stage that selects task-relevant object regions across camera views, along with a complementary geometric grounding stage that emphasizes the 3D structure of these objects over their appearance. The resulting grounded views are then fed to a pretrained VLA policy, which we fine-tune exclusively on single-object demonstrations collected without environmental clutter or non-target objects. On a real-world UR10e tabletop setup, OBEYED-VLA substantially improves robustness over strong VLA baselines across four challenging regimes and multiple difficulty levels: distractor objects, absent-target rejection, background appearance changes, and cluttered manipulation of unseen objects. Ablation studies confirm that both semantic grounding and geometry-aware grounding are critical to these gains. Overall, the results indicate that making perception an explicit, object-centric component is an effective way to strengthen and generalize VLA-based robotic manipulation.
CADKnitter: Compositional CAD Generation from Text and Geometry Guidance
Dec 12, 2025Crafting computer-aided design (CAD) models has long been a painstaking and time-intensive task, demanding both precision and expertise from designers. With the emergence of 3D generation, this task has undergone a transformative impact, shifting not only from visual fidelity to functional utility but also enabling editable CAD designs. Prior works have achieved early success in single-part CAD generation, which is not well-suited for real-world applications, as multiple parts need to be assembled under semantic and geometric constraints. In this paper, we propose CADKnitter, a compositional CAD generation framework with a geometry-guided diffusion sampling strategy. CADKnitter is able to generate a complementary CAD part that follows both the geometric constraints of the given CAD model and the semantic constraints of the desired design text prompt. We also curate a dataset, so-called KnitCAD, containing over 310,000 samples of CAD models, along with textual prompts and assembly metadata that provide semantic and geometric constraints. Intensive experiments demonstrate that our proposed method outperforms other state-of-the-art baselines by a clear margin.
Rethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
GroupKAN: Rethinking Nonlinearity with Grouped Spline-based KAN Modeling for Efficient Medical Image Segmentation
Nov 07, 2025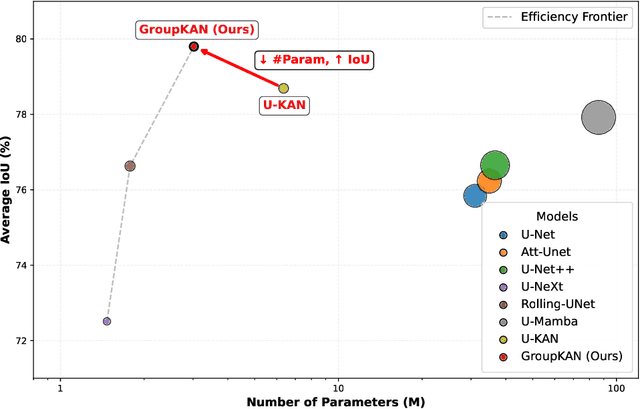
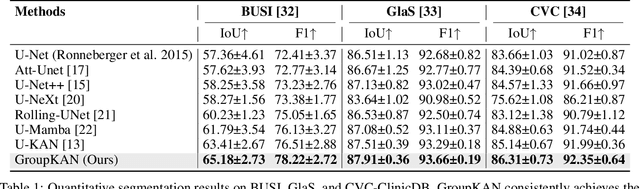
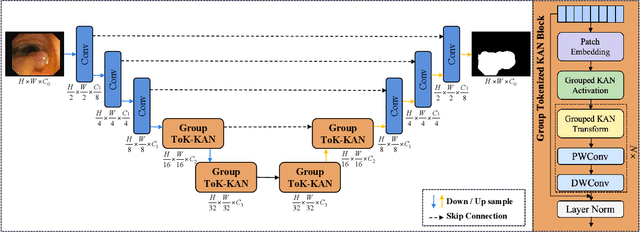
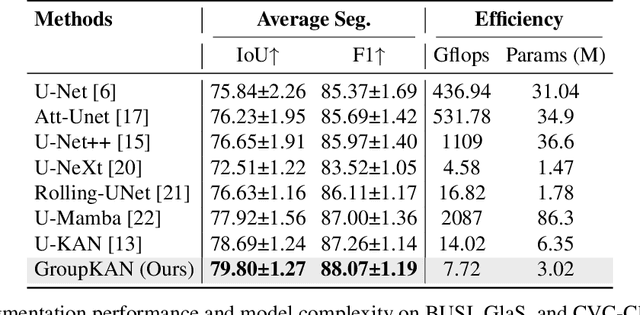
Medical image segmentation requires models that are accurate, lightweight, and interpretable. Convolutional architectures lack adaptive nonlinearity and transparent decision-making, whereas Transformer architectures are hindered by quadratic complexity and opaque attention mechanisms. U-KAN addresses these challenges using Kolmogorov-Arnold Networks, achieving higher accuracy than both convolutional and attention-based methods, fewer parameters than Transformer variants, and improved interpretability compared to conventional approaches. However, its O(C^2) complexity due to full-channel transformations limits its scalability as the number of channels increases. To overcome this, we introduce GroupKAN, a lightweight segmentation network that incorporates two novel, structured functional modules: (1) Grouped KAN Transform, which partitions channels into G groups for multivariate spline mappings, reducing complexity to O(C^2/G), and (2) Grouped KAN Activation, which applies shared spline-based mappings within each channel group for efficient, token-wise nonlinearity. Evaluated on three medical benchmarks (BUSI, GlaS, and CVC), GroupKAN achieves an average IoU of 79.80 percent, surpassing U-KAN by +1.11 percent while requiring only 47.6 percent of the parameters (3.02M vs 6.35M), and shows improved interpretability.
Hybrid Gripper Finger Enabling In-Grasp Friction Modulation Using Inflatable Silicone Pockets
Oct 31, 2025Grasping objects with diverse mechanical properties, such as heavy, slippery, or fragile items, remains a significant challenge in robotics. Conventional grippers often rely on applying high normal forces, which can cause damage to objects. To address this limitation, we present a hybrid gripper finger that combines a rigid structural shell with a soft, inflatable silicone pocket. The gripper finger can actively modulate its surface friction by controlling the internal air pressure of the silicone pocket. Results from fundamental experiments indicate that increasing the internal pressure results in a proportional increase in the effective coefficient of friction. This enables the gripper to stably lift heavy and slippery objects without increasing the gripping force and to handle fragile or deformable objects, such as eggs, fruits, and paper cups, with minimal damage by increasing friction rather than applying excessive force. The experimental results demonstrate that the hybrid gripper finger with adaptable friction provides a robust and safer alternative to relying solely on high normal forces, thereby enhancing the gripper flexibility in handling delicate, fragile, and diverse objects.
MobiDock: Design and Control of A Modular Self Reconfigurable Bimanual Mobile Manipulator via Robotic Docking
Oct 31, 2025Multi-robot systems, particularly mobile manipulators, face challenges in control coordination and dynamic stability when working together. To address this issue, this study proposes MobiDock, a modular self-reconfigurable mobile manipulator system that allows two independent robots to physically connect and form a unified mobile bimanual platform. This process helps transform a complex multi-robot control problem into the management of a simpler, single system. The system utilizes an autonomous docking strategy based on computer vision with AprilTag markers and a new threaded screw-lock mechanism. Experimental results show that the docked configuration demonstrates better performance in dynamic stability and operational efficiency compared to two independently cooperating robots. Specifically, the unified system has lower Root Mean Square (RMS) Acceleration and Jerk values, higher angular precision, and completes tasks significantly faster. These findings confirm that physical reconfiguration is a powerful design principle that simplifies cooperative control, improving stability and performance for complex tasks in real-world environments.
Learning Human Motion with Temporally Conditional Mamba
Oct 14, 2025Learning human motion based on a time-dependent input signal presents a challenging yet impactful task with various applications. The goal of this task is to generate or estimate human movement that consistently reflects the temporal patterns of conditioning inputs. Existing methods typically rely on cross-attention mechanisms to fuse the condition with motion. However, this approach primarily captures global interactions and struggles to maintain step-by-step temporal alignment. To address this limitation, we introduce Temporally Conditional Mamba, a new mamba-based model for human motion generation. Our approach integrates conditional information into the recurrent dynamics of the Mamba block, enabling better temporally aligned motion. To validate the effectiveness of our method, we evaluate it on a variety of human motion tasks. Extensive experiments demonstrate that our model significantly improves temporal alignment, motion realism, and condition consistency over state-of-the-art approaches. Our project page is available at https://zquang2202.github.io/TCM.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
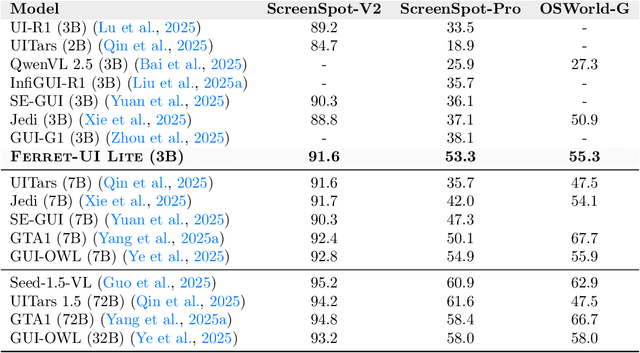
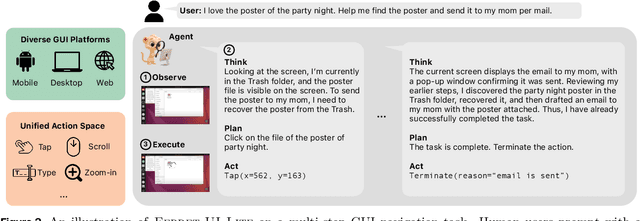
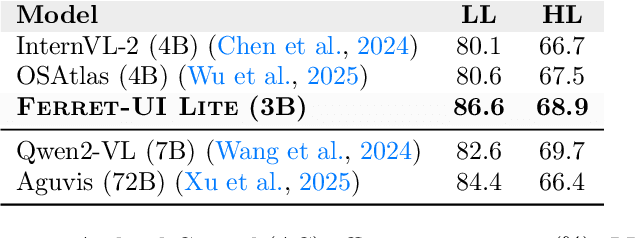
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
OVITA: Open-Vocabulary Interpretable Trajectory Adaptations
Aug 24, 2025Adapting trajectories to dynamic situations and user preferences is crucial for robot operation in unstructured environments with non-expert users. Natural language enables users to express these adjustments in an interactive manner. We introduce OVITA, an interpretable, open-vocabulary, language-driven framework designed for adapting robot trajectories in dynamic and novel situations based on human instructions. OVITA leverages multiple pre-trained Large Language Models (LLMs) to integrate user commands into trajectories generated by motion planners or those learned through demonstrations. OVITA employs code as an adaptation policy generated by an LLM, enabling users to adjust individual waypoints, thus providing flexible control. Another LLM, which acts as a code explainer, removes the need for expert users, enabling intuitive interactions. The efficacy and significance of the proposed OVITA framework is demonstrated through extensive simulations and real-world environments with diverse tasks involving spatiotemporal variations on heterogeneous robotic platforms such as a KUKA IIWA robot manipulator, Clearpath Jackal ground robot, and CrazyFlie drone.