 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial Identification using Multi-Modal Intrinsic Radiation and Radiography
Mar 27, 2026We investigate multi-modal material identification for special nuclear material (SNM) configurations using a combination of X-ray radiography, high-resolution γ-ray spectroscopy, and neutron multiplicity measurements. We consider a Beryllium Reflected Plutonium sphere (BeRP) ball surrounded by one or two concentric shielding shells of unknown composition whose radii are assumed known from radiography. High-purity germanium (HPGe) spectra are reduced to net counts in selected Pu-239 photo-peaks, while neutron multiplicity information is summarized by Feynman variances Y2 and Y3 computed from factorial moments of the neutron counting statistics. Using synthetic data generated with the Gamma Detector Response and Analysis Software (GADRAS) for a range of shielding materials and thicknesses, we cast the material identification problem as a supervised multi-class classification task over all admissible shell-material combinations. We demonstrate that a random forest classifier trained on combined gamma and neutron features achieves almost perfect identification accuracy for single-shell cases, and substantial performance gains for more challenging double-shell configurations relative to gamma-only classification. Alternative statistical and machine-learning formulations for this multi-class problem are examined along with examination of the impact of model-mismatch between the forward model and the test cases as given by variations in the statistical noise. Opportunities for extending the approach to more complex geometries and experimental data are also discussed.
Neural Autoregressive Flows for Markov Boundary Learning
Mar 21, 2026Recovering Markov boundary -- the minimal set of variables that maximizes predictive performance for a response variable -- is crucial in many applications. While recent advances improve upon traditional constraint-based techniques by scoring local causal structures, they still rely on nonparametric estimators and heuristic searches, lacking theoretical guarantees for reliability. This paper investigates a framework for efficient Markov boundary discovery by integrating conditional entropy from information theory as a scoring criterion. We design a novel masked autoregressive network to capture complex dependencies. A parallelizable greedy search strategy in polynomial time is proposed, supported by analytical evidence. We also discuss how initializing a graph with learned Markov boundaries accelerates the convergence of causal discovery. Comprehensive evaluations on real-world and synthetic datasets demonstrate the scalability and superior performance of our method in both Markov boundary discovery and causal discovery tasks.
NOIR: Privacy-Preserving Generation of Code with Open-Source LLMs
Jan 22, 2026Although boosting software development performance, large language model (LLM)-powered code generation introduces intellectual property and data security risks rooted in the fact that a service provider (cloud) observes a client's prompts and generated code, which can be proprietary in commercial systems. To mitigate this problem, we propose NOIR, the first framework to protect the client's prompts and generated code from the cloud. NOIR uses an encoder and a decoder at the client to encode and send the prompts' embeddings to the cloud to get enriched embeddings from the LLM, which are then decoded to generate the code locally at the client. Since the cloud can use the embeddings to infer the prompt and the generated code, NOIR introduces a new mechanism to achieve indistinguishability, a local differential privacy protection at the token embedding level, in the vocabulary used in the prompts and code, and a data-independent and randomized tokenizer on the client side. These components effectively defend against reconstruction and frequency analysis attacks by an honest-but-curious cloud. Extensive analysis and results using open-source LLMs show that NOIR significantly outperforms existing baselines on benchmarks, including the Evalplus (MBPP and HumanEval, Pass@1 of 76.7 and 77.4), and BigCodeBench (Pass@1 of 38.7, only a 1.77% drop from the original LLM) under strong privacy against attacks.
Sparse Partial Optimal Transport via Quadratic Regularization
Aug 11, 2025Partial Optimal Transport (POT) has recently emerged as a central tool in various Machine Learning (ML) applications. It lifts the stringent assumption of the conventional Optimal Transport (OT) that input measures are of equal masses, which is often not guaranteed in real-world datasets, and thus offers greater flexibility by permitting transport between unbalanced input measures. Nevertheless, existing major solvers for POT commonly rely on entropic regularization for acceleration and thus return dense transport plans, hindering the adoption of POT in various applications that favor sparsity. In this paper, as an alternative approach to the entropic POT formulation in the literature, we propose a novel formulation of POT with quadratic regularization, hence termed quadratic regularized POT (QPOT), which induces sparsity to the transport plan and consequently facilitates the adoption of POT in many applications with sparsity requirements. Extensive experiments on synthetic and CIFAR-10 datasets, as well as real-world applications such as color transfer and domain adaptations, consistently demonstrate the improved sparsity and favorable performance of our proposed QPOT formulation.
* 12 pages, 8 figures
A Landmark-Aided Navigation Approach Using Side-Scan Sonar
Mar 10, 2025Cost-effective localization methods for Autonomous Underwater Vehicle (AUV) navigation are key for ocean monitoring and data collection at high resolution in time and space. Algorithmic solutions suitable for real-time processing that handle nonlinear measurement models and different forms of measurement uncertainty will accelerate the development of field-ready technology. This paper details a Bayesian estimation method for landmark-aided navigation using a Side-scan Sonar (SSS) sensor. The method bounds navigation filter error in the GPS-denied undersea environment and captures the highly nonlinear nature of slant range measurements while remaining computationally tractable. Combining a novel measurement model with the chosen statistical framework facilitates the efficient use of SSS data and, in the future, could be used in real time. The proposed filter has two primary steps: a prediction step using an unscented transform and an update step utilizing particles. The update step performs probabilistic association of sonar detections with known landmarks. We evaluate algorithm performance and tractability using synthetic data and real data collected field experiments. Field experiments were performed using two different marine robotic platforms with two different SSS and at two different sites. Finally, we discuss the computational requirements of the proposed method and how it extends to real-time applications.
Clustering-based Meta Bayesian Optimization with Theoretical Guarantee
Mar 08, 2025Bayesian Optimization (BO) is a well-established method for addressing black-box optimization problems. In many real-world scenarios, optimization often involves multiple functions, emphasizing the importance of leveraging data and learned functions from prior tasks to enhance efficiency in the current task. To expedite convergence to the global optimum, recent studies have introduced meta-learning strategies, collectively referred to as meta-BO, to incorporate knowledge from historical tasks. However, in practical settings, the underlying functions are often heterogeneous, which can adversely affect optimization performance for the current task. Additionally, when the number of historical tasks is large, meta-BO methods face significant scalability challenges. In this work, we propose a scalable and robust meta-BO method designed to address key challenges in heterogeneous and large-scale meta-tasks. Our approach (1) effectively partitions transferred meta-functions into highly homogeneous clusters, (2) learns the geometry-based surrogate prototype that capture the structural patterns within each cluster, and (3) adaptively synthesizes meta-priors during the online phase using statistical distance-based weighting policies. Experimental results on real-world hyperparameter optimization (HPO) tasks, combined with theoretical guarantees, demonstrate the robustness and effectiveness of our method in overcoming these challenges.
Sampling Foundational Transformer: A Theoretical Perspective
Aug 11, 2024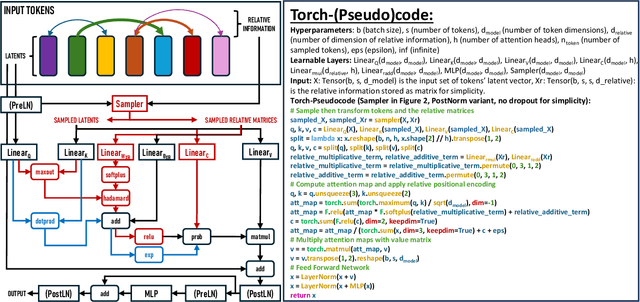
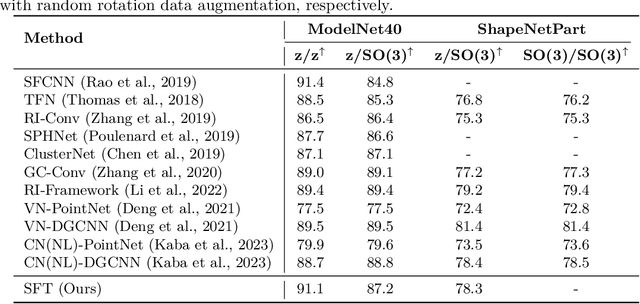
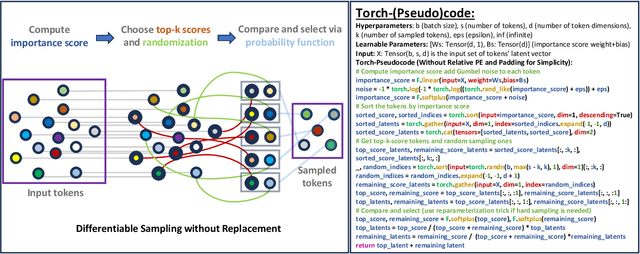
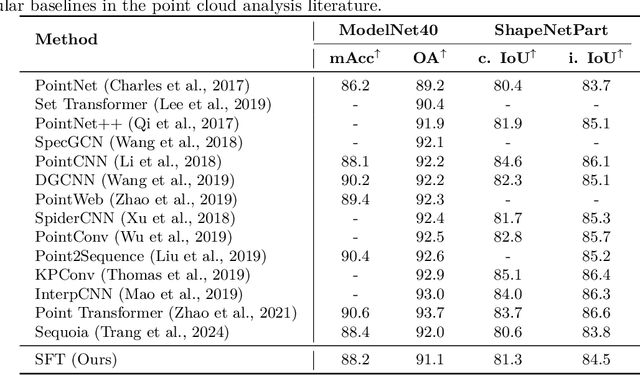
The versatility of self-attention mechanism earned transformers great success in almost all data modalities, with limitations on the quadratic complexity and difficulty of training. To apply transformers across different data modalities, practitioners have to make specific clever data-modality-dependent constructions. In this paper, we propose Sampling Foundational Transformer (SFT) that can work on multiple data modalities (e.g., point cloud, graph, and sequence) and constraints (e.g., rotational-invariant). The existence of such model is important as contemporary foundational modeling requires operability on multiple data sources. For efficiency on large number of tokens, our model relies on our context aware sampling-without-replacement mechanism for both linear asymptotic computational complexity and real inference time gain. For efficiency, we rely on our newly discovered pseudoconvex formulation of transformer layer to increase model's convergence rate. As a model working on multiple data modalities, SFT has achieved competitive results on many benchmarks, while being faster in inference, compared to other very specialized models.
SAMSA: Efficient Transformer for Many Data Modalities
Aug 10, 2024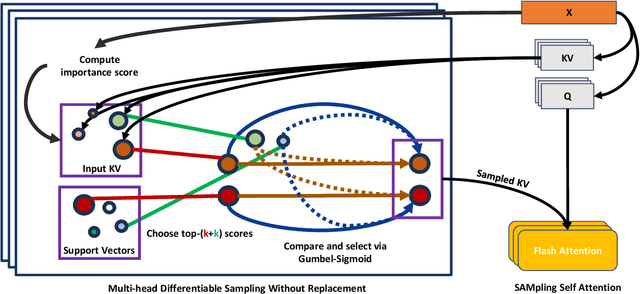
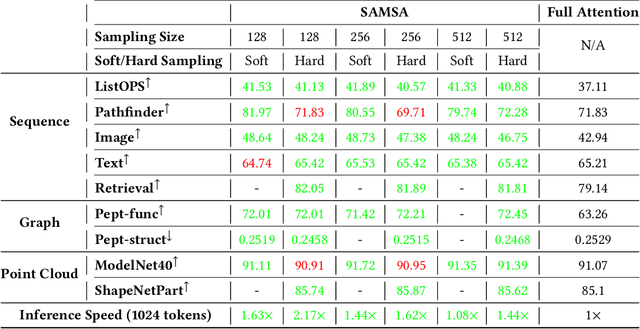
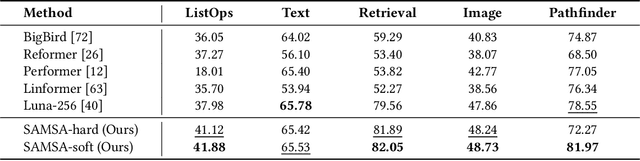
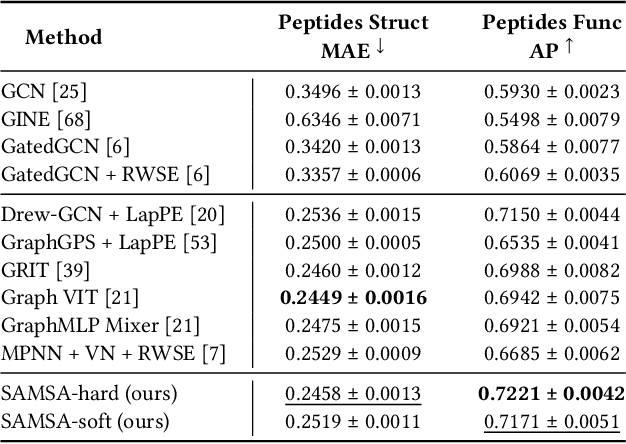
The versatility of self-attention mechanism earned transformers great success in almost all data modalities, with limitations on the quadratic complexity and difficulty of training. Efficient transformers, on the other hand, often rely on clever data-modality-dependent construction to get over the quadratic complexity of transformers. This greatly hinders their applications on different data modalities, which is one of the pillars of contemporary foundational modeling. In this paper, we lay the groundwork for efficient foundational modeling by proposing SAMSA - SAMpling-Self-Attention, a context-aware linear complexity self-attention mechanism that works well on multiple data modalities. Our mechanism is based on a differentiable sampling without replacement method we discovered. This enables the self-attention module to attend to the most important token set, where the importance is defined by data. Moreover, as differentiability is not needed in inference, the sparse formulation of our method costs little time overhead, further lowering computational costs. In short, SAMSA achieved competitive or even SOTA results on many benchmarks, while being faster in inference, compared to other very specialized models. Against full self-attention, real inference time significantly decreases while performance ranges from negligible degradation to outperformance. We release our source code in the repository: https://github.com/HySonLab/SAMSA
Wildest Dreams: Reproducible Research in Privacy-preserving Neural Network Training
Mar 06, 2024Machine Learning (ML), addresses a multitude of complex issues in multiple disciplines, including social sciences, finance, and medical research. ML models require substantial computing power and are only as powerful as the data utilized. Due to high computational cost of ML methods, data scientists frequently use Machine Learning-as-a-Service (MLaaS) to outsource computation to external servers. However, when working with private information, like financial data or health records, outsourcing the computation might result in privacy issues. Recent advances in Privacy-Preserving Techniques (PPTs) have enabled ML training and inference over protected data through the use of Privacy-Preserving Machine Learning (PPML). However, these techniques are still at a preliminary stage and their application in real-world situations is demanding. In order to comprehend discrepancy between theoretical research suggestions and actual applications, this work examines the past and present of PPML, focusing on Homomorphic Encryption (HE) and Secure Multi-party Computation (SMPC) applied to ML. This work primarily focuses on the ML model's training phase, where maintaining user data privacy is of utmost importance. We provide a solid theoretical background that eases the understanding of current approaches and their limitations. In addition, we present a SoK of the most recent PPML frameworks for model training and provide a comprehensive comparison in terms of the unique properties and performances on standard benchmarks. Also, we reproduce the results for some of the papers and examine at what level existing works in the field provide support for open science. We believe our work serves as a valuable contribution by raising awareness about the current gap between theoretical advancements and real-world applications in PPML, specifically regarding open-source availability, reproducibility, and usability.
GuardML: Efficient Privacy-Preserving Machine Learning Services Through Hybrid Homomorphic Encryption
Jan 26, 2024Machine Learning (ML) has emerged as one of data science's most transformative and influential domains. However, the widespread adoption of ML introduces privacy-related concerns owing to the increasing number of malicious attacks targeting ML models. To address these concerns, Privacy-Preserving Machine Learning (PPML) methods have been introduced to safeguard the privacy and security of ML models. One such approach is the use of Homomorphic Encryption (HE). However, the significant drawbacks and inefficiencies of traditional HE render it impractical for highly scalable scenarios. Fortunately, a modern cryptographic scheme, Hybrid Homomorphic Encryption (HHE), has recently emerged, combining the strengths of symmetric cryptography and HE to surmount these challenges. Our work seeks to introduce HHE to ML by designing a PPML scheme tailored for end devices. We leverage HHE as the fundamental building block to enable secure learning of classification outcomes over encrypted data, all while preserving the privacy of the input data and ML model. We demonstrate the real-world applicability of our construction by developing and evaluating an HHE-based PPML application for classifying heart disease based on sensitive ECG data. Notably, our evaluations revealed a slight reduction in accuracy compared to inference on plaintext data. Additionally, both the analyst and end devices experience minimal communication and computation costs, underscoring the practical viability of our approach. The successful integration of HHE into PPML provides a glimpse into a more secure and privacy-conscious future for machine learning on relatively constrained end devices.