 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Split, not Hijack: Preventing Feature-Space Hijacking Attacks in Split Learning
Apr 14, 2024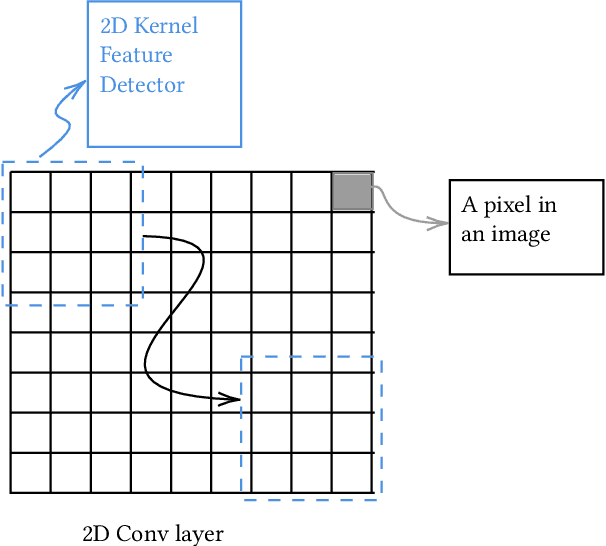
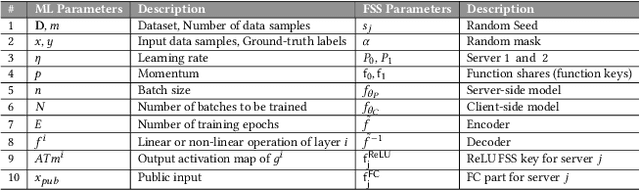
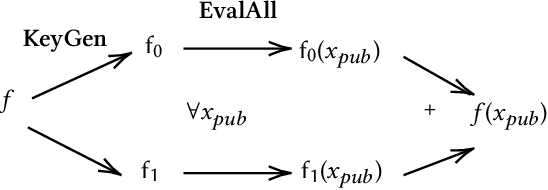
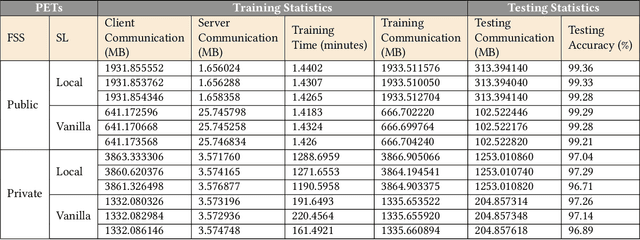
The popularity of Machine Learning (ML) makes the privacy of sensitive data more imperative than ever. Collaborative learning techniques like Split Learning (SL) aim to protect client data while enhancing ML processes. Though promising, SL has been proved to be vulnerable to a plethora of attacks, thus raising concerns about its effectiveness on data privacy. In this work, we introduce a hybrid approach combining SL and Function Secret Sharing (FSS) to ensure client data privacy. The client adds a random mask to the activation map before sending it to the servers. The servers cannot access the original function but instead work with shares generated using FSS. Consequently, during both forward and backward propagation, the servers cannot reconstruct the client's raw data from the activation map. Furthermore, through visual invertibility, we demonstrate that the server is incapable of reconstructing the raw image data from the activation map when using FSS. It enhances privacy by reducing privacy leakage compared to other SL-based approaches where the server can access client input information. Our approach also ensures security against feature space hijacking attack, protecting sensitive information from potential manipulation. Our protocols yield promising results, reducing communication overhead by over 2x and training time by over 7x compared to the same model with FSS, without any SL. Also, we show that our approach achieves >96% accuracy and remains equivalent to the plaintext models.
Wildest Dreams: Reproducible Research in Privacy-preserving Neural Network Training
Mar 06, 2024Machine Learning (ML), addresses a multitude of complex issues in multiple disciplines, including social sciences, finance, and medical research. ML models require substantial computing power and are only as powerful as the data utilized. Due to high computational cost of ML methods, data scientists frequently use Machine Learning-as-a-Service (MLaaS) to outsource computation to external servers. However, when working with private information, like financial data or health records, outsourcing the computation might result in privacy issues. Recent advances in Privacy-Preserving Techniques (PPTs) have enabled ML training and inference over protected data through the use of Privacy-Preserving Machine Learning (PPML). However, these techniques are still at a preliminary stage and their application in real-world situations is demanding. In order to comprehend discrepancy between theoretical research suggestions and actual applications, this work examines the past and present of PPML, focusing on Homomorphic Encryption (HE) and Secure Multi-party Computation (SMPC) applied to ML. This work primarily focuses on the ML model's training phase, where maintaining user data privacy is of utmost importance. We provide a solid theoretical background that eases the understanding of current approaches and their limitations. In addition, we present a SoK of the most recent PPML frameworks for model training and provide a comprehensive comparison in terms of the unique properties and performances on standard benchmarks. Also, we reproduce the results for some of the papers and examine at what level existing works in the field provide support for open science. We believe our work serves as a valuable contribution by raising awareness about the current gap between theoretical advancements and real-world applications in PPML, specifically regarding open-source availability, reproducibility, and usability.
GuardML: Efficient Privacy-Preserving Machine Learning Services Through Hybrid Homomorphic Encryption
Jan 26, 2024Machine Learning (ML) has emerged as one of data science's most transformative and influential domains. However, the widespread adoption of ML introduces privacy-related concerns owing to the increasing number of malicious attacks targeting ML models. To address these concerns, Privacy-Preserving Machine Learning (PPML) methods have been introduced to safeguard the privacy and security of ML models. One such approach is the use of Homomorphic Encryption (HE). However, the significant drawbacks and inefficiencies of traditional HE render it impractical for highly scalable scenarios. Fortunately, a modern cryptographic scheme, Hybrid Homomorphic Encryption (HHE), has recently emerged, combining the strengths of symmetric cryptography and HE to surmount these challenges. Our work seeks to introduce HHE to ML by designing a PPML scheme tailored for end devices. We leverage HHE as the fundamental building block to enable secure learning of classification outcomes over encrypted data, all while preserving the privacy of the input data and ML model. We demonstrate the real-world applicability of our construction by developing and evaluating an HHE-based PPML application for classifying heart disease based on sensitive ECG data. Notably, our evaluations revealed a slight reduction in accuracy compared to inference on plaintext data. Additionally, both the analyst and end devices experience minimal communication and computation costs, underscoring the practical viability of our approach. The successful integration of HHE into PPML provides a glimpse into a more secure and privacy-conscious future for machine learning on relatively constrained end devices.