 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-based Meta Bayesian Optimization with Theoretical Guarantee
Mar 08, 2025Bayesian Optimization (BO) is a well-established method for addressing black-box optimization problems. In many real-world scenarios, optimization often involves multiple functions, emphasizing the importance of leveraging data and learned functions from prior tasks to enhance efficiency in the current task. To expedite convergence to the global optimum, recent studies have introduced meta-learning strategies, collectively referred to as meta-BO, to incorporate knowledge from historical tasks. However, in practical settings, the underlying functions are often heterogeneous, which can adversely affect optimization performance for the current task. Additionally, when the number of historical tasks is large, meta-BO methods face significant scalability challenges. In this work, we propose a scalable and robust meta-BO method designed to address key challenges in heterogeneous and large-scale meta-tasks. Our approach (1) effectively partitions transferred meta-functions into highly homogeneous clusters, (2) learns the geometry-based surrogate prototype that capture the structural patterns within each cluster, and (3) adaptively synthesizes meta-priors during the online phase using statistical distance-based weighting policies. Experimental results on real-world hyperparameter optimization (HPO) tasks, combined with theoretical guarantees, demonstrate the robustness and effectiveness of our method in overcoming these challenges.
A Combination of BERT and Transformer for Vietnamese Spelling Correction
May 04, 2024Recently, many studies have shown the efficiency of using Bidirectional Encoder Representations from Transformers (BERT) in various Natural Language Processing (NLP) tasks. Specifically, English spelling correction task that uses Encoder-Decoder architecture and takes advantage of BERT has achieved state-of-the-art result. However, to our knowledge, there is no implementation in Vietnamese yet. Therefore, in this study, a combination of Transformer architecture (state-of-the-art for Encoder-Decoder model) and BERT was proposed to deal with Vietnamese spelling correction. The experiment results have shown that our model outperforms other approaches as well as the Google Docs Spell Checking tool, achieves an 86.24 BLEU score on this task.
* 13 pages
Author Name Disambiguation by Using Deep Neural Network
Jul 29, 2017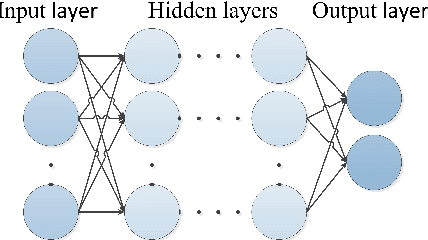
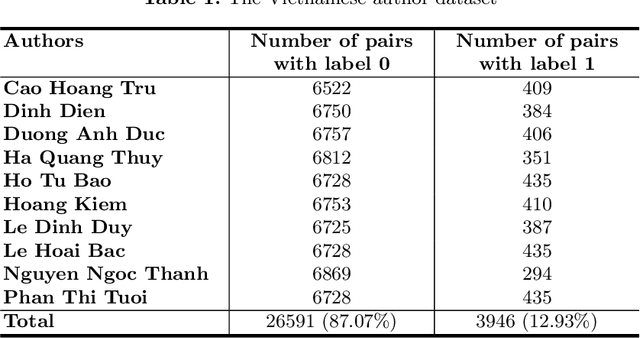
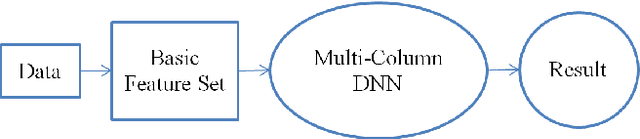
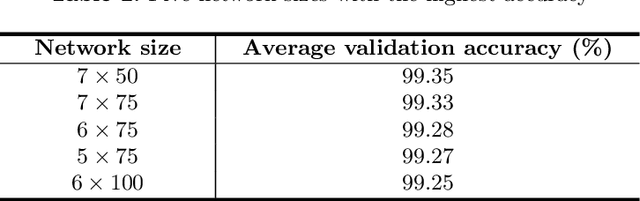
Author name ambiguity decreases the quality and reliability of information retrieved from digital libraries. Existing methods have tried to solve this problem by predefining a feature set based on expert's knowledge for a specific dataset. In this paper, we propose a new approach which uses deep neural network to learn features automatically from data. Additionally, we propose the general system architecture for author name disambiguation on any dataset. In this research, we evaluate the proposed method on a dataset containing Vietnamese author names. The results show that this method significantly outperforms other methods that use predefined feature set. The proposed method achieves 99.31% in terms of accuracy. Prediction error rate decreases from 1.83% to 0.69%, i.e., it decreases by 1.14%, or 62.3% relatively compared with other methods that use predefined feature set (Table 3).