 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Scene Landmark Detection for Camera Localization
Jan 31, 2024



Camera localization methods based on retrieval, local feature matching, and 3D structure-based pose estimation are accurate but require high storage, are slow, and are not privacy-preserving. A method based on scene landmark detection (SLD) was recently proposed to address these limitations. It involves training a convolutional neural network (CNN) to detect a few predetermined, salient, scene-specific 3D points or landmarks and computing camera pose from the associated 2D-3D correspondences. Although SLD outperformed existing learning-based approaches, it was notably less accurate than 3D structure-based methods. In this paper, we show that the accuracy gap was due to insufficient model capacity and noisy labels during training. To mitigate the capacity issue, we propose to split the landmarks into subgroups and train a separate network for each subgroup. To generate better training labels, we propose using dense reconstructions to estimate visibility of scene landmarks. Finally, we present a compact architecture to improve memory efficiency. Accuracy wise, our approach is on par with state of the art structure based methods on the INDOOR-6 dataset but runs significantly faster and uses less storage. Code and models can be found at https://github.com/microsoft/SceneLandmarkLocalization.
Egocentric Scene Understanding via Multimodal Spatial Rectifier
Jul 14, 2022
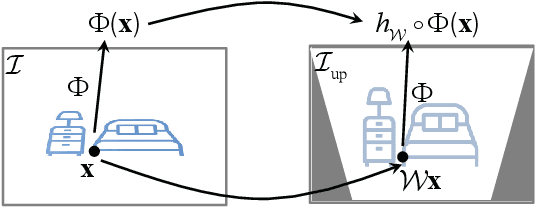


In this paper, we study a problem of egocentric scene understanding, i.e., predicting depths and surface normals from an egocentric image. Egocentric scene understanding poses unprecedented challenges: (1) due to large head movements, the images are taken from non-canonical viewpoints (i.e., tilted images) where existing models of geometry prediction do not apply; (2) dynamic foreground objects including hands constitute a large proportion of visual scenes. These challenges limit the performance of the existing models learned from large indoor datasets, such as ScanNet and NYUv2, which comprise predominantly upright images of static scenes. We present a multimodal spatial rectifier that stabilizes the egocentric images to a set of reference directions, which allows learning a coherent visual representation. Unlike unimodal spatial rectifier that often produces excessive perspective warp for egocentric images, the multimodal spatial rectifier learns from multiple directions that can minimize the impact of the perspective warp. To learn visual representations of the dynamic foreground objects, we present a new dataset called EDINA (Egocentric Depth on everyday INdoor Activities) that comprises more than 500K synchronized RGBD frames and gravity directions. Equipped with the multimodal spatial rectifier and the EDINA dataset, our proposed method on single-view depth and surface normal estimation significantly outperforms the baselines not only on our EDINA dataset, but also on other popular egocentric datasets, such as First Person Hand Action (FPHA) and EPIC-KITCHENS.
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021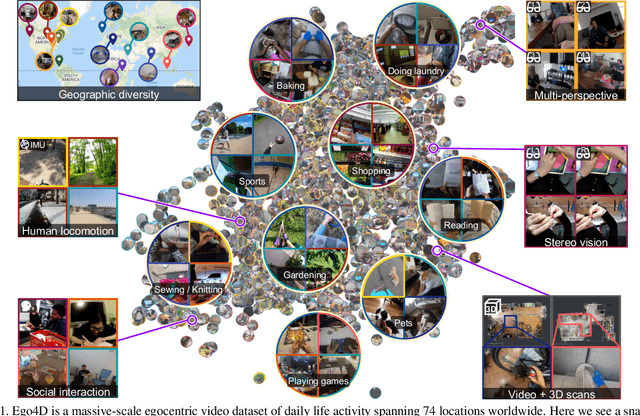
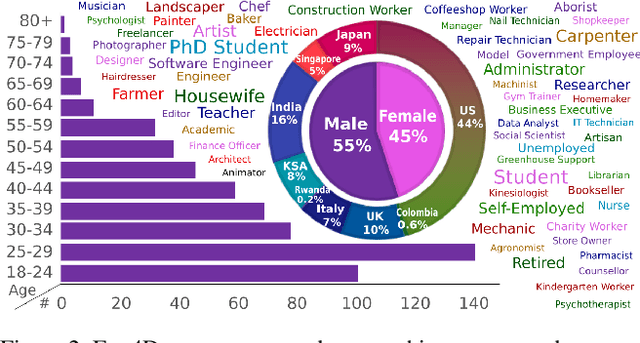

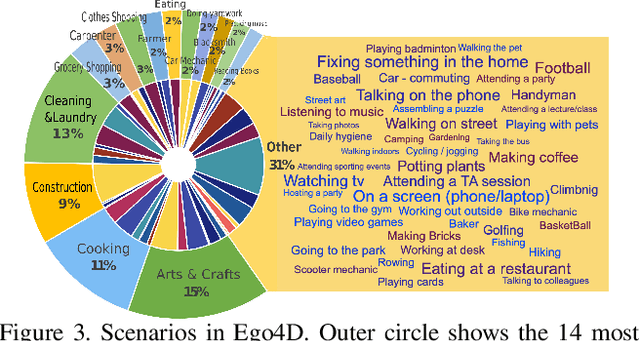
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Deep Multi-view Depth Estimation with Predicted Uncertainty
Nov 19, 2020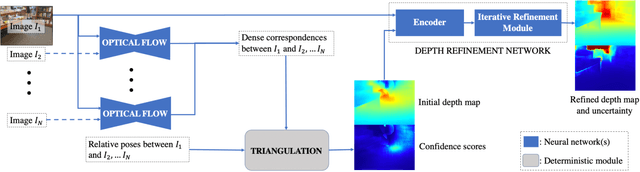
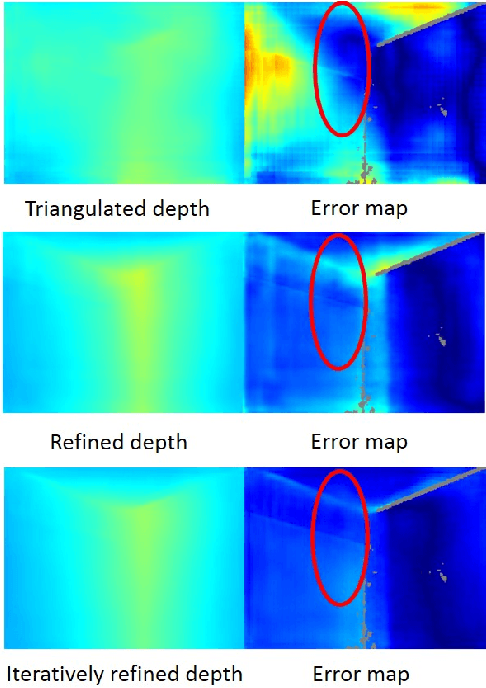

In this paper, we address the problem of estimating dense depth from a sequence of images using deep neural networks. Specifically, we employ a dense-optical-flow network to compute correspondences and then triangulate the point cloud to obtain an initial depth map. Parts of the point cloud, however, may be less accurate than others due to lack of common observations or small baseline-to-depth ratio. To further increase the triangulation accuracy, we introduce a depth-refinement network (DRN) that optimizes the initial depth map based on the image's contextual cues. In particular, the DRN contains an iterative refinement module (IRM) that improves the depth accuracy over iterations by refining the deep features. Lastly, the DRN also predicts the uncertainty in the refined depths, which is desirable in applications such as measurement selection for scene reconstruction. We show experimentally that our algorithm outperforms state-of-the-art approaches in terms of depth accuracy, and verify that our predicted uncertainty is highly correlated to the actual depth error.
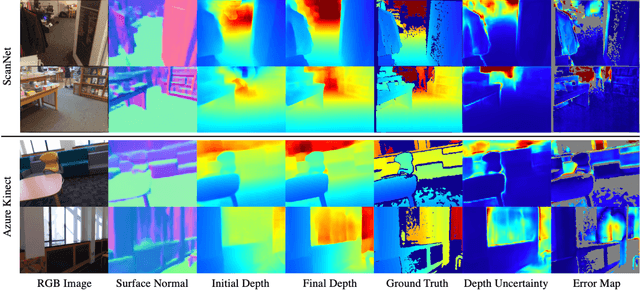
Deep Depth Estimation from Visual-Inertial SLAM
Aug 14, 2020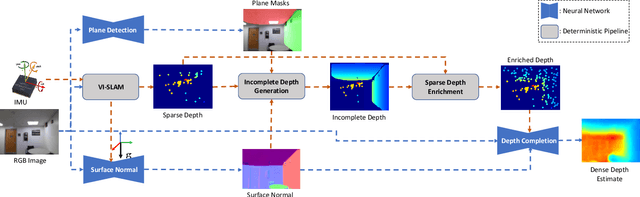
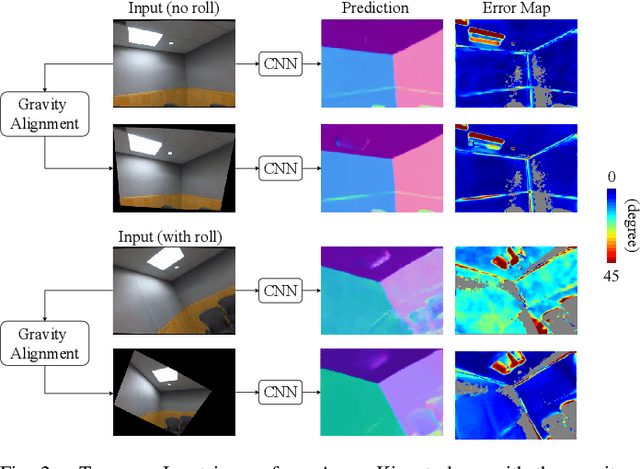

This paper addresses the problem of learning to complete a scene's depth from sparse depth points and images of indoor scenes. Specifically, we study the case in which the sparse depth is computed from a visual-inertial simultaneous localization and mapping (VI-SLAM) system. The resulting point cloud has low density, it is noisy, and has non-uniform spatial distribution, as compared to the input from active depth sensors, e.g., LiDAR or Kinect. Since the VI-SLAM produces point clouds only over textured areas, we compensate for the missing depth of the low-texture surfaces by leveraging their planar structures and their surface normals which is an important intermediate representation. The pre-trained surface normal network, however, suffers from large performance degradation when there is a significant difference in the viewing direction (especially the roll angle) of the test image as compared to the trained ones. To address this limitation, we use the available gravity estimate from the VI-SLAM to warp the input image to the orientation prevailing in the training dataset. This results in a significant performance gain for the surface normal estimate, and thus the dense depth estimates. Finally, we show that our method outperforms other state-of-the-art approaches both on training (ScanNet and NYUv2) and testing (collected with Azure Kinect) datasets.
Surface Normal Estimation of Tilted Images via Spatial Rectifier
Jul 17, 2020
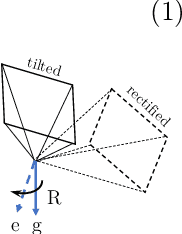
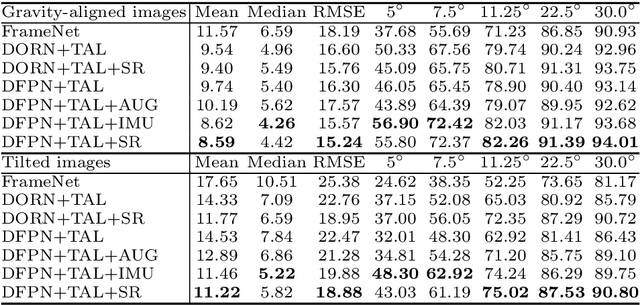
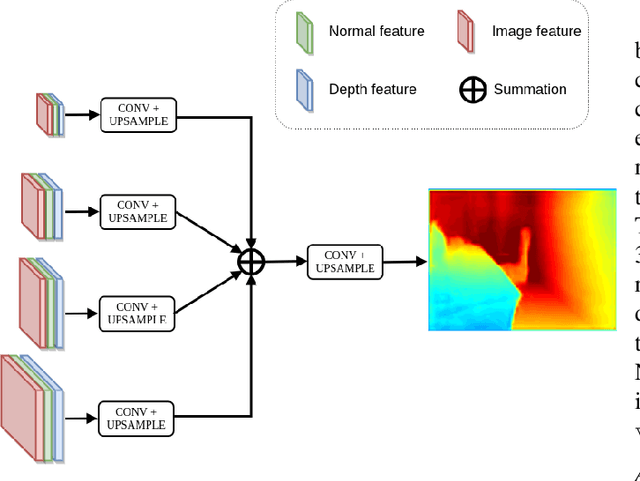
In this paper, we present a spatial rectifier to estimate surface normals of tilted images. Tilted images are of particular interest as more visual data are captured by arbitrarily oriented sensors such as body-/robot-mounted cameras. Existing approaches exhibit bounded performance on predicting surface normals because they were trained using gravity-aligned images. Our two main hypotheses are: (1) visual scene layout is indicative of the gravity direction; and (2) not all surfaces are equally represented by a learned estimator due to the structured distribution of the training data, thus, there exists a transformation for each tilted image that is more responsive to the learned estimator than others. We design a spatial rectifier that is learned to transform the surface normal distribution of a tilted image to the rectified one that matches the gravity-aligned training data distribution. Along with the spatial rectifier, we propose a novel truncated angular loss that offers a stronger gradient at smaller angular errors and robustness to outliers. The resulting estimator outperforms the state-of-the-art methods including data augmentation baselines not only on ScanNet and NYUv2 but also on a new dataset called Tilt-RGBD that includes considerable roll and pitch camera motion.
Author Name Disambiguation by Using Deep Neural Network
Jul 29, 2017
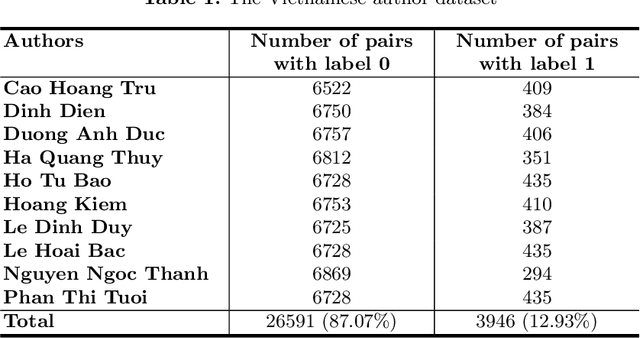
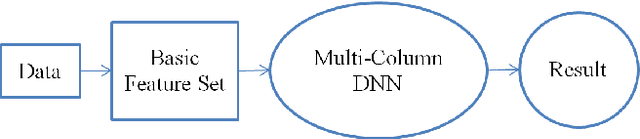
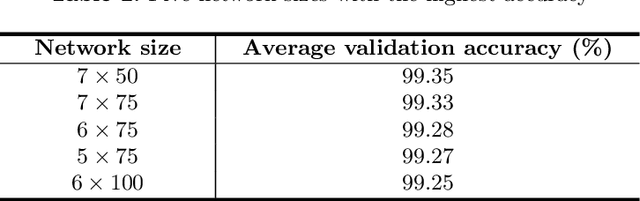
Author name ambiguity decreases the quality and reliability of information retrieved from digital libraries. Existing methods have tried to solve this problem by predefining a feature set based on expert's knowledge for a specific dataset. In this paper, we propose a new approach which uses deep neural network to learn features automatically from data. Additionally, we propose the general system architecture for author name disambiguation on any dataset. In this research, we evaluate the proposed method on a dataset containing Vietnamese author names. The results show that this method significantly outperforms other methods that use predefined feature set. The proposed method achieves 99.31% in terms of accuracy. Prediction error rate decreases from 1.83% to 0.69%, i.e., it decreases by 1.14%, or 62.3% relatively compared with other methods that use predefined feature set (Table 3).