 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEIM: Multi-partition Embedding Interaction Beyond Block Term Format for Efficient and Expressive Link Prediction
Oct 04, 2022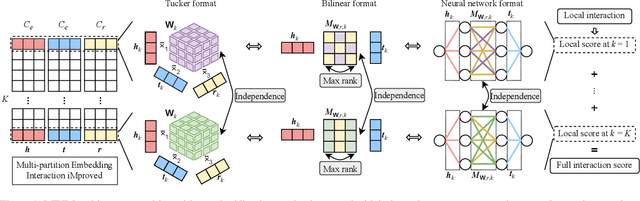

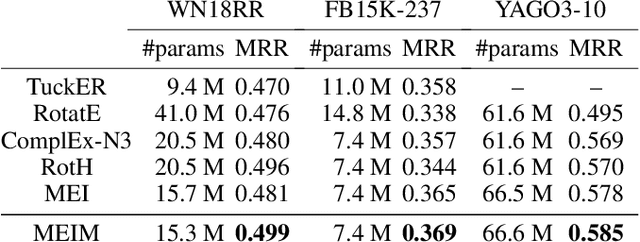
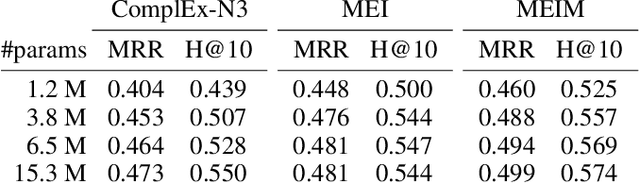
Knowledge graph embedding aims to predict the missing relations between entities in knowledge graphs. Tensor-decomposition-based models, such as ComplEx, provide a good trade-off between efficiency and expressiveness, that is crucial because of the large size of real world knowledge graphs. The recent multi-partition embedding interaction (MEI) model subsumes these models by using the block term tensor format and provides a systematic solution for the trade-off. However, MEI has several drawbacks, some of which carried from its subsumed tensor-decomposition-based models. In this paper, we address these drawbacks and introduce the Multi-partition Embedding Interaction iMproved beyond block term format (MEIM) model, with independent core tensor for ensemble effects and soft orthogonality for max-rank mapping, in addition to multi-partition embedding. MEIM improves expressiveness while still being highly efficient, helping it to outperform strong baselines and achieve state-of-the-art results on difficult link prediction benchmarks using fairly small embedding sizes. The source code is released at https://github.com/tranhungnghiep/MEIM-KGE.
* Accepted at the International Joint Conference on Artificial Intelligence (IJCAI), 2022; add appendix with extra experiments
Multi-Partition Embedding Interaction with Block Term Format for Knowledge Graph Completion
Jun 29, 2020



Knowledge graph completion is an important task that aims to predict the missing relational link between entities. Knowledge graph embedding methods perform this task by representing entities and relations as embedding vectors and modeling their interactions to compute the matching score of each triple. Previous work has usually treated each embedding as a whole and has modeled the interactions between these whole embeddings, potentially making the model excessively expensive or requiring specially designed interaction mechanisms. In this work, we propose the multi-partition embedding interaction (MEI) model with block term format to systematically address this problem. MEI divides each embedding into a multi-partition vector to efficiently restrict the interactions. Each local interaction is modeled with the Tucker tensor format and the full interaction is modeled with the block term tensor format, enabling MEI to control the trade-off between expressiveness and computational cost, learn the interaction mechanisms from data automatically, and achieve state-of-the-art performance on the link prediction task. In addition, we theoretically study the parameter efficiency problem and derive a simple empirically verified criterion for optimal parameter trade-off. We also apply the framework of MEI to provide a new generalized explanation for several specially designed interaction mechanisms in previous models.
* ECAI 2020. Including state-of-the-art results for very small models in appendix
Exploring Scholarly Data by Semantic Query on Knowledge Graph Embedding Space
Sep 17, 2019
The trends of open science have enabled several open scholarly datasets which include millions of papers and authors. Managing, exploring, and utilizing such large and complicated datasets effectively are challenging. In recent years, the knowledge graph has emerged as a universal data format for representing knowledge about heterogeneous entities and their relationships. The knowledge graph can be modeled by knowledge graph embedding methods, which represent entities and relations as embedding vectors in semantic space, then model the interactions between these embedding vectors. However, the semantic structures in the knowledge graph embedding space are not well-studied, thus knowledge graph embedding methods are usually only used for knowledge graph completion but not data representation and analysis. In this paper, we propose to analyze these semantic structures based on the well-studied word embedding space and use them to support data exploration. We also define the semantic queries, which are algebraic operations between the embedding vectors in the knowledge graph embedding space, to solve queries such as similarity and analogy between the entities on the original datasets. We then design a general framework for data exploration by semantic queries and discuss the solution to some traditional scholarly data exploration tasks. We also propose some new interesting tasks that can be solved based on the uncanny semantic structures of the embedding space.
Analyzing Knowledge Graph Embedding Methods from a Multi-Embedding Interaction Perspective
Mar 27, 2019



Knowledge graph is a popular format for representing knowledge, with many applications to semantic search engines, question-answering systems, and recommender systems. Real-world knowledge graphs are usually incomplete, so knowledge graph embedding methods, such as Canonical decomposition/Parallel factorization (CP), DistMult, and ComplEx, have been proposed to address this issue. These methods represent entities and relations as embedding vectors in semantic space and predict the links between them. The embedding vectors themselves contain rich semantic information and can be used in other applications such as data analysis. However, mechanisms in these models and the embedding vectors themselves vary greatly, making it difficult to understand and compare them. Given this lack of understanding, we risk using them ineffectively or incorrectly, particularly for complicated models, such as CP, with two role-based embedding vectors, or the state-of-the-art ComplEx model, with complex-valued embedding vectors. In this paper, we propose a multi-embedding interaction mechanism as a new approach to uniting and generalizing these models. We derive them theoretically via this mechanism and provide empirical analyses and comparisons between them. We also propose a new multi-embedding model based on quaternion algebra and show that it achieves promising results using popular benchmarks.
Author Name Disambiguation by Using Deep Neural Network
Jul 29, 2017
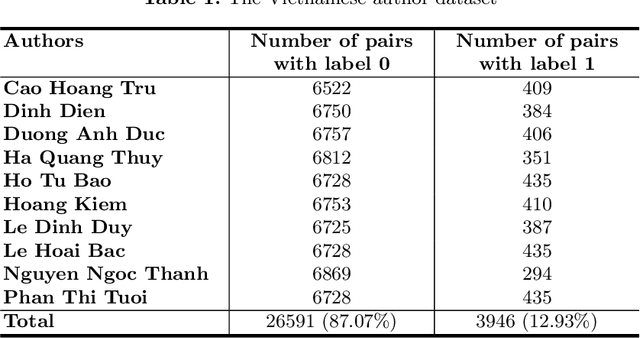
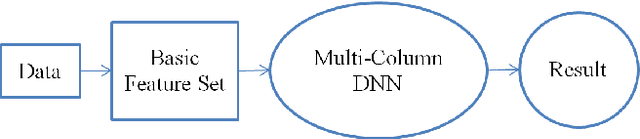
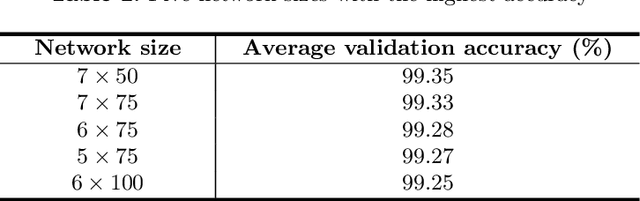
Author name ambiguity decreases the quality and reliability of information retrieved from digital libraries. Existing methods have tried to solve this problem by predefining a feature set based on expert's knowledge for a specific dataset. In this paper, we propose a new approach which uses deep neural network to learn features automatically from data. Additionally, we propose the general system architecture for author name disambiguation on any dataset. In this research, we evaluate the proposed method on a dataset containing Vietnamese author names. The results show that this method significantly outperforms other methods that use predefined feature set. The proposed method achieves 99.31% in terms of accuracy. Prediction error rate decreases from 1.83% to 0.69%, i.e., it decreases by 1.14%, or 62.3% relatively compared with other methods that use predefined feature set (Table 3).
SciRecSys: A Recommendation System for Scientific Publication by Discovering Keyword Relationships
Feb 27, 2015



In this work, we propose a new approach for discovering various relationships among keywords over the scientific publications based on a Markov Chain model. It is an important problem since keywords are the basic elements for representing abstract objects such as documents, user profiles, topics and many things else. Our model is very effective since it combines four important factors in scientific publications: content, publicity, impact and randomness. Particularly, a recommendation system (called SciRecSys) has been presented to support users to efficiently find out relevant articles.