 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Scene Landmark Detection for Camera Localization
Jan 31, 2024



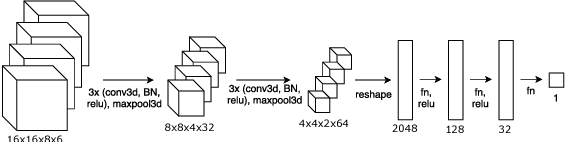
Camera localization methods based on retrieval, local feature matching, and 3D structure-based pose estimation are accurate but require high storage, are slow, and are not privacy-preserving. A method based on scene landmark detection (SLD) was recently proposed to address these limitations. It involves training a convolutional neural network (CNN) to detect a few predetermined, salient, scene-specific 3D points or landmarks and computing camera pose from the associated 2D-3D correspondences. Although SLD outperformed existing learning-based approaches, it was notably less accurate than 3D structure-based methods. In this paper, we show that the accuracy gap was due to insufficient model capacity and noisy labels during training. To mitigate the capacity issue, we propose to split the landmarks into subgroups and train a separate network for each subgroup. To generate better training labels, we propose using dense reconstructions to estimate visibility of scene landmarks. Finally, we present a compact architecture to improve memory efficiency. Accuracy wise, our approach is on par with state of the art structure based methods on the INDOOR-6 dataset but runs significantly faster and uses less storage. Code and models can be found at https://github.com/microsoft/SceneLandmarkLocalization.
Optimizing Fiducial Marker Placement for Improved Visual Localization
Nov 02, 2022Adding fiducial markers to a scene is a well-known strategy for making visual localization algorithms more robust. Traditionally, these marker locations are selected by humans who are familiar with visual localization techniques. This paper explores the problem of automatic marker placement within a scene. Specifically, given a predetermined set of markers and a scene model, we compute optimized marker positions within the scene that can improve accuracy in visual localization. Our main contribution is a novel framework for modeling camera localizability that incorporates both natural scene features and artificial fiducial markers added to the scene. We present optimized marker placement (OMP), a greedy algorithm that is based on the camera localizability framework. We have also designed a simulation framework for testing marker placement algorithms on 3D models and images generated from synthetic scenes. We have evaluated OMP within this testbed and demonstrate an improvement in the localization rate by up to 20 percent on three different scenes.
Privacy-Preserving Visual Feature Descriptors through Adversarial Affine Subspace Embedding
Jun 11, 2020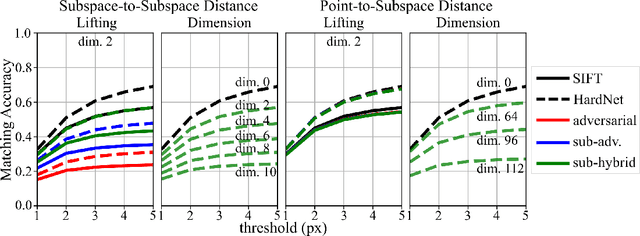

Many computer vision systems require users to upload image features to the cloud for processing and storage. Such features can be exploited to recover sensitive information about the scene or subjects, e.g., by reconstructing the appearance of the original image. To address this privacy concern, we propose a new privacy-preserving feature representation. The core idea of our work is to drop constraints from each feature descriptor by embedding it within an affine subspace containing the original feature as well as one or more adversarial feature samples. Feature matching on the privacy-preserving representation is enabled based on the notion of subspace-to-subspace distance. We experimentally demonstrate the effectiveness of our method and its high practical relevance for applications such as crowd-sourced 3D scene reconstruction and face authentication. Compared to the original features, our approach has only marginal impact on performance but makes it significantly more difficult for an adversary to recover private information.
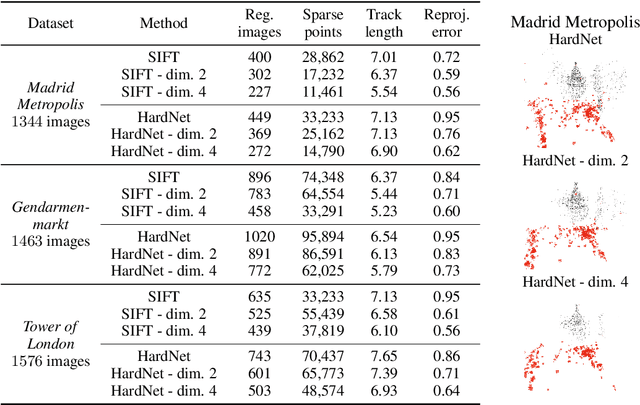
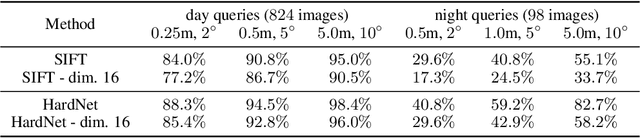
Revealing Scenes by Inverting Structure from Motion Reconstructions
Apr 05, 2019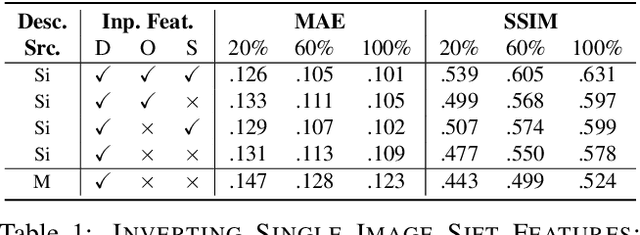
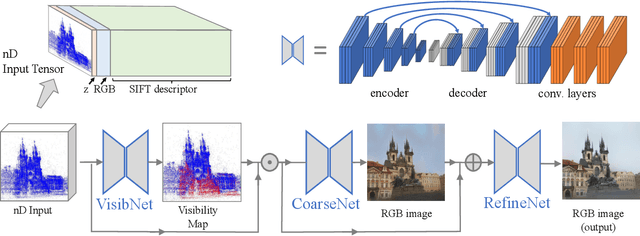
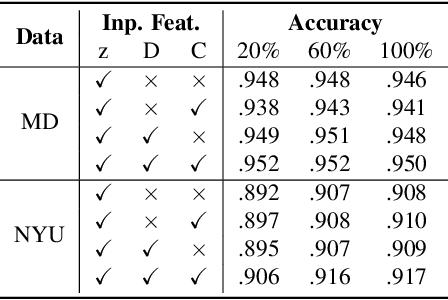

Many 3D vision systems localize cameras within a scene using 3D point clouds. Such point clouds are often obtained using structure from motion (SfM), after which the images are discarded to preserve privacy. In this paper, we show, for the first time, that such point clouds retain enough information to reveal scene appearance and compromise privacy. We present a privacy attack that reconstructs color images of the scene from the point cloud. Our method is based on a cascaded U-Net that takes as input, a 2D multichannel image of the points rendered from a specific viewpoint containing point depth and optionally color and SIFT descriptors and outputs a color image of the scene from that viewpoint. Unlike previous feature inversion methods, we deal with highly sparse and irregular 2D point distributions and inputs where many point attributes are missing, namely keypoint orientation and scale, the descriptor image source and the 3D point visibility. We evaluate our attack algorithm on public datasets and analyze the significance of the point cloud attributes. Finally, we show that novel views can also be generated thereby enabling compelling virtual tours of the underlying scene.
Privacy Preserving Image-Based Localization
Mar 13, 2019
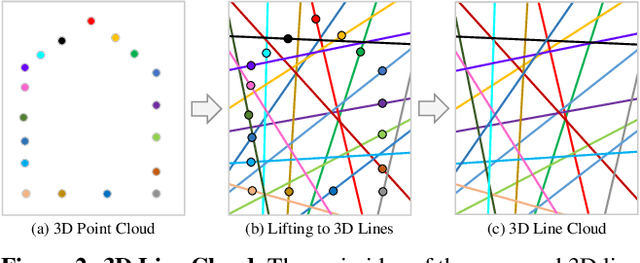
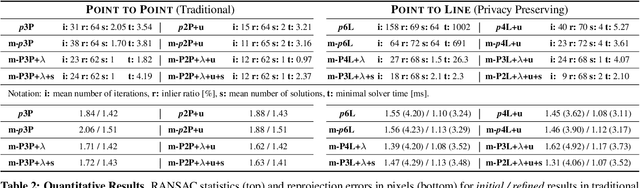
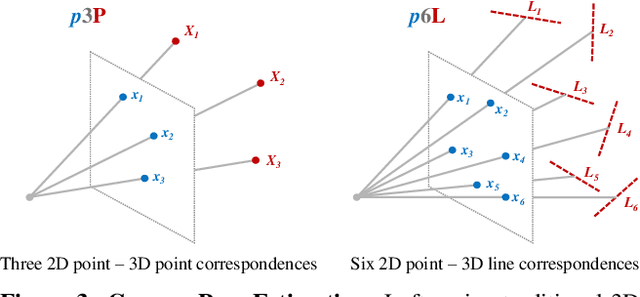
Image-based localization is a core component of many augmented/mixed reality (AR/MR) and autonomous robotic systems. Current localization systems rely on the persistent storage of 3D point clouds of the scene to enable camera pose estimation, but such data reveals potentially sensitive scene information. This gives rise to significant privacy risks, especially as for many applications 3D mapping is a background process that the user might not be fully aware of. We pose the following question: How can we avoid disclosing confidential information about the captured 3D scene, and yet allow reliable camera pose estimation? This paper proposes the first solution to what we call privacy preserving image-based localization. The key idea of our approach is to lift the map representation from a 3D point cloud to a 3D line cloud. This novel representation obfuscates the underlying scene geometry while providing sufficient geometric constraints to enable robust and accurate 6-DOF camera pose estimation. Extensive experiments on several datasets and localization scenarios underline the high practical relevance of our proposed approach.
Photorealistic Image Synthesis for Object Instance Detection
Feb 09, 2019
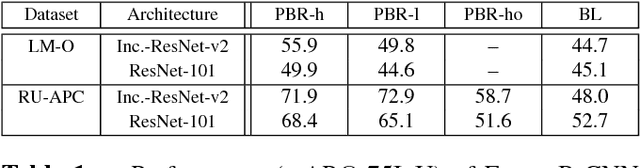


We present an approach to synthesize highly photorealistic images of 3D object models, which we use to train a convolutional neural network for detecting the objects in real images. The proposed approach has three key ingredients: (1) 3D object models are rendered in 3D models of complete scenes with realistic materials and lighting, (2) plausible geometric configuration of objects and cameras in a scene is generated using physics simulations, and (3) high photorealism of the synthesized images achieved by physically based rendering. When trained on images synthesized by the proposed approach, the Faster R-CNN object detector achieves a 24% absolute improvement of mAP@.75IoU on Rutgers APC and 11% on LineMod-Occluded datasets, compared to a baseline where the training images are synthesized by rendering object models on top of random photographs. This work is a step towards being able to effectively train object detectors without capturing or annotating any real images. A dataset of 600K synthetic images with ground truth annotations for various computer vision tasks will be released on the project website: thodan.github.io/objectsynth.
Learning to Align Images using Weak Geometric Supervision
Aug 04, 2018
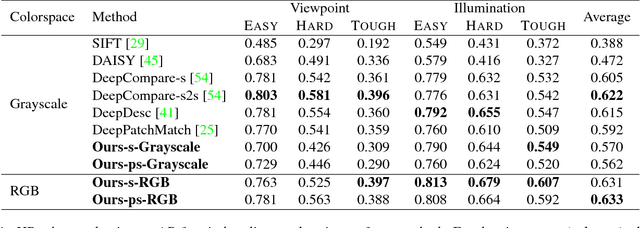
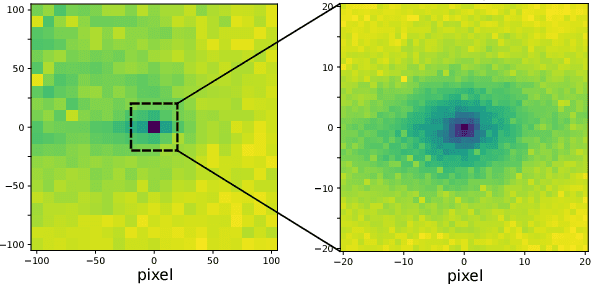
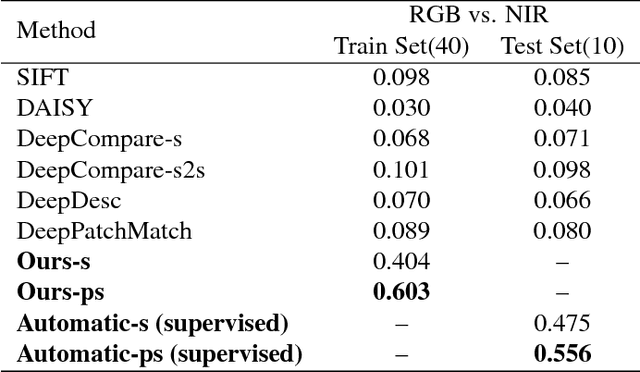
Image alignment tasks require accurate pixel correspondences, which are usually recovered by matching local feature descriptors. Such descriptors are often derived using supervised learning on existing datasets with ground truth correspondences. However, the cost of creating such datasets is usually prohibitive. In this paper, we propose a new approach to align two images related by an unknown 2D homography where the local descriptor is learned from scratch from the images and the homography is estimated simultaneously. Our key insight is that a siamese convolutional neural network can be trained jointly while iteratively updating the homography parameters by optimizing a single loss function. Our method is currently weakly supervised because the input images need to be roughly aligned. We have used this method to align images of different modalities such as RGB and near-infra-red (NIR) without using any prior labeled data. Images automatically aligned by our method were then used to train descriptors that generalize to new images. We also evaluated our method on RGB images. On the HPatches benchmark, our method achieves comparable accuracy to deep local descriptors that were trained offline in a supervised setting.
Learn-to-Score: Efficient 3D Scene Exploration by Predicting View Utility
Jul 31, 2018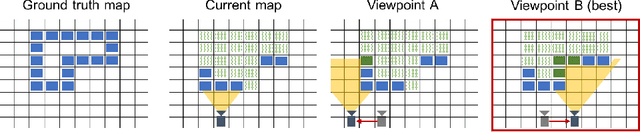
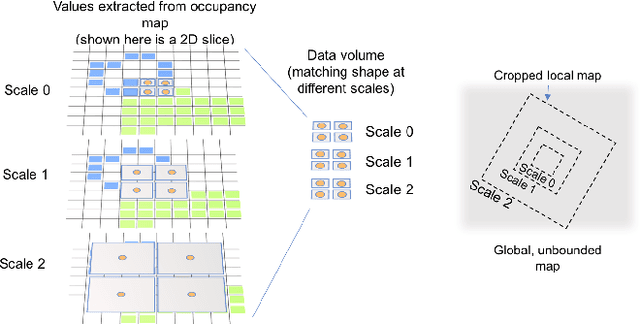
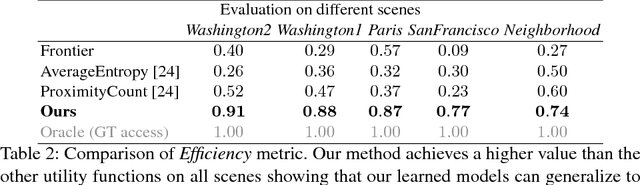
Camera equipped drones are nowadays being used to explore large scenes and reconstruct detailed 3D maps. When free space in the scene is approximately known, an offline planner can generate optimal plans to efficiently explore the scene. However, for exploring unknown scenes, the planner must predict and maximize usefulness of where to go on the fly. Traditionally, this has been achieved using handcrafted utility functions. We propose to learn a better utility function that predicts the usefulness of future viewpoints. Our learned utility function is based on a 3D convolutional neural network. This network takes as input a novel volumetric scene representation that implicitly captures previously visited viewpoints and generalizes to new scenes. We evaluate our method on several large 3D models of urban scenes using simulated depth cameras. We show that our method outperforms existing utility measures in terms of reconstruction performance and is robust to sensor noise.
Real-Time Seamless Single Shot 6D Object Pose Prediction
Apr 18, 2018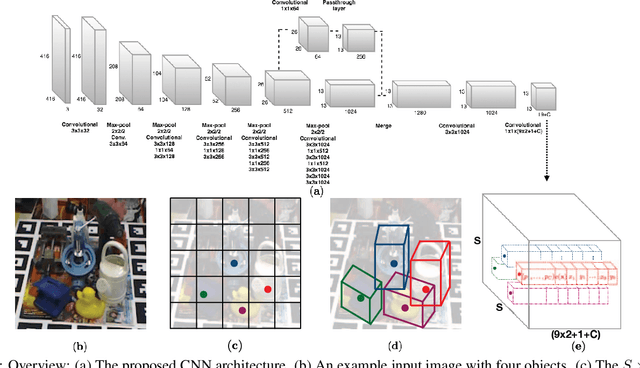
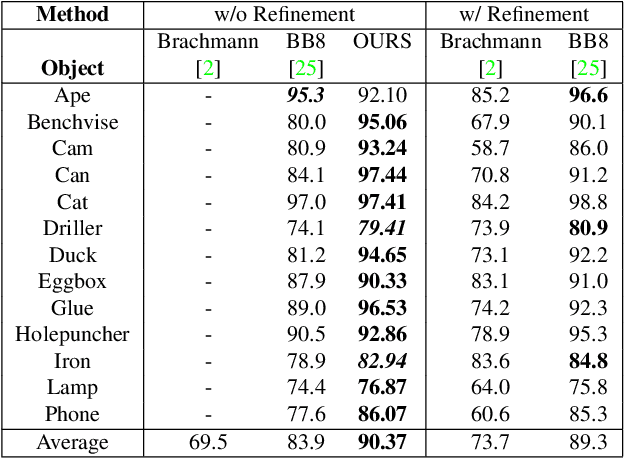
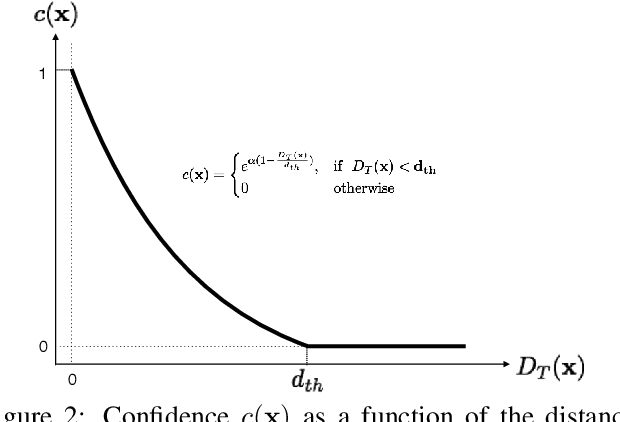
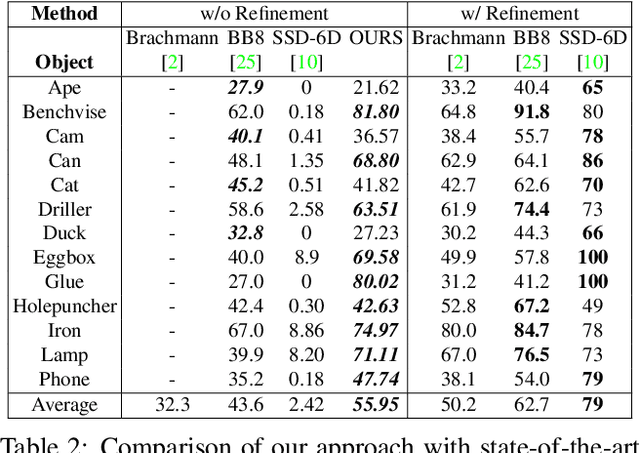
We propose a single-shot approach for simultaneously detecting an object in an RGB image and predicting its 6D pose without requiring multiple stages or having to examine multiple hypotheses. Unlike a recently proposed single-shot technique for this task (Kehl et al., ICCV'17) that only predicts an approximate 6D pose that must then be refined, ours is accurate enough not to require additional post-processing. As a result, it is much faster - 50 fps on a Titan X (Pascal) GPU - and more suitable for real-time processing. The key component of our method is a new CNN architecture inspired by the YOLO network design that directly predicts the 2D image locations of the projected vertices of the object's 3D bounding box. The object's 6D pose is then estimated using a PnP algorithm. For single object and multiple object pose estimation on the LINEMOD and OCCLUSION datasets, our approach substantially outperforms other recent CNN-based approaches when they are all used without post-processing. During post-processing, a pose refinement step can be used to boost the accuracy of the existing methods, but at 10 fps or less, they are much slower than our method.
Semi-Global Stereo Matching with Surface Orientation Priors
Dec 03, 2017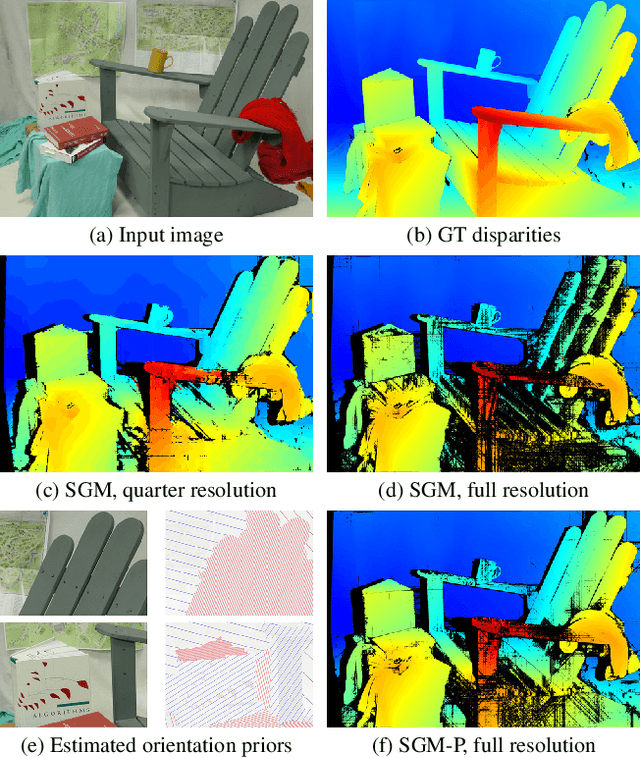

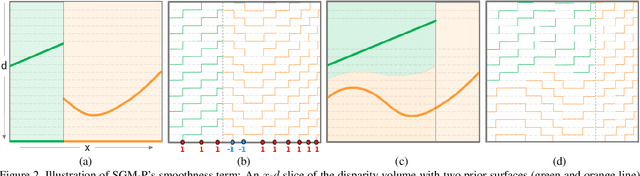
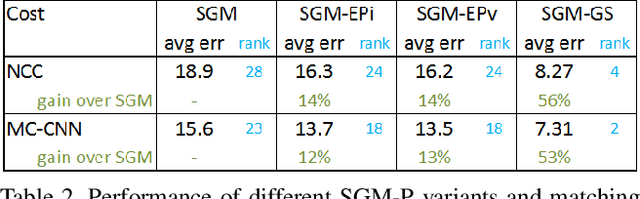
Semi-Global Matching (SGM) is a widely-used efficient stereo matching technique. It works well for textured scenes, but fails on untextured slanted surfaces due to its fronto-parallel smoothness assumption. To remedy this problem, we propose a simple extension, termed SGM-P, to utilize precomputed surface orientation priors. Such priors favor different surface slants in different 2D image regions or 3D scene regions and can be derived in various ways. In this paper we evaluate plane orientation priors derived from stereo matching at a coarser resolution and show that such priors can yield significant performance gains for difficult weakly-textured scenes. We also explore surface normal priors derived from Manhattan-world assumptions, and we analyze the potential performance gains using oracle priors derived from ground-truth data. SGM-P only adds a minor computational overhead to SGM and is an attractive alternative to more complex methods employing higher-order smoothness terms.