 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Fiducial Marker Placement for Improved Visual Localization
Nov 02, 2022Adding fiducial markers to a scene is a well-known strategy for making visual localization algorithms more robust. Traditionally, these marker locations are selected by humans who are familiar with visual localization techniques. This paper explores the problem of automatic marker placement within a scene. Specifically, given a predetermined set of markers and a scene model, we compute optimized marker positions within the scene that can improve accuracy in visual localization. Our main contribution is a novel framework for modeling camera localizability that incorporates both natural scene features and artificial fiducial markers added to the scene. We present optimized marker placement (OMP), a greedy algorithm that is based on the camera localizability framework. We have also designed a simulation framework for testing marker placement algorithms on 3D models and images generated from synthetic scenes. We have evaluated OMP within this testbed and demonstrate an improvement in the localization rate by up to 20 percent on three different scenes.
Efficient Scene Compression for Visual-based Localization
Nov 27, 2020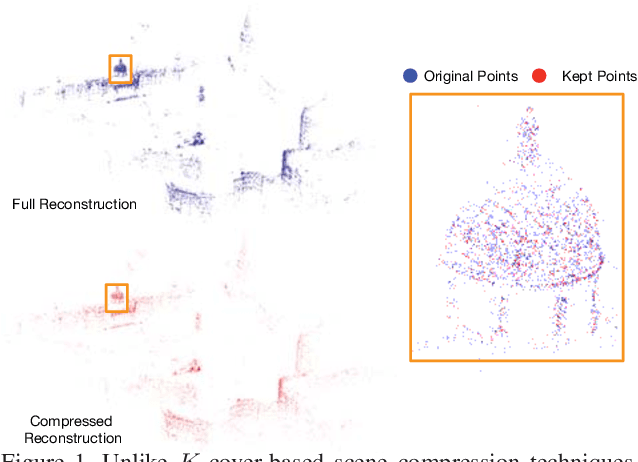
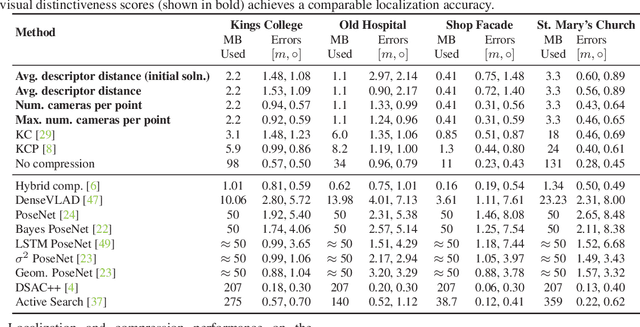
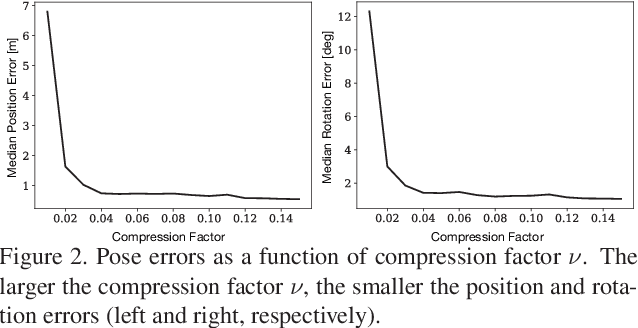

Estimating the pose of a camera with respect to a 3D reconstruction or scene representation is a crucial step for many mixed reality and robotics applications. Given the vast amount of available data nowadays, many applications constrain storage and/or bandwidth to work efficiently. To satisfy these constraints, many applications compress a scene representation by reducing its number of 3D points. While state-of-the-art methods use $K$-cover-based algorithms to compress a scene, they are slow and hard to tune. To enhance speed and facilitate parameter tuning, this work introduces a novel approach that compresses a scene representation by means of a constrained quadratic program (QP). Because this QP resembles a one-class support vector machine, we derive a variant of the sequential minimal optimization to solve it. Our approach uses the points corresponding to the support vectors as the subset of points to represent a scene. We also present an efficient initialization method that allows our method to converge quickly. Our experiments on publicly available datasets show that our approach compresses a scene representation quickly while delivering accurate pose estimates.
Generalized Pose-and-Scale Estimation using 4-Point Congruence Constraints
Nov 27, 2020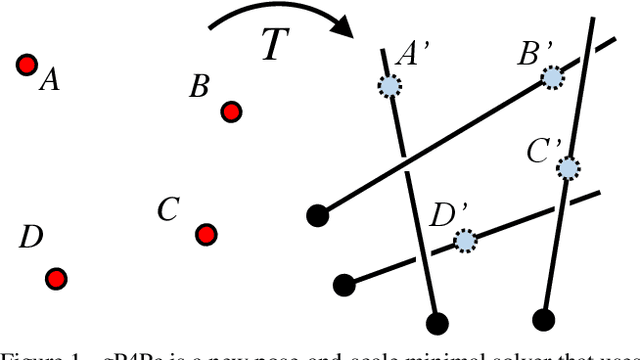
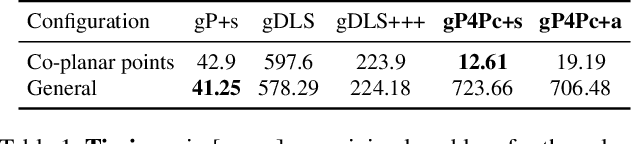
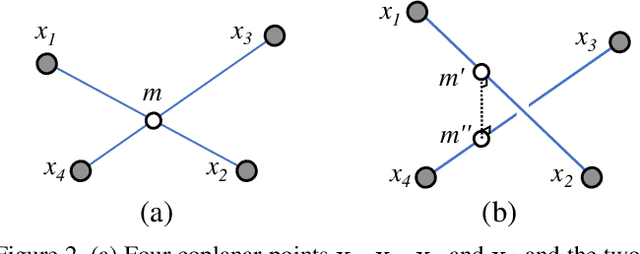

We present gP4Pc, a new method for computing the absolute pose of a generalized camera with unknown internal scale from four corresponding 3D point-and-ray pairs. Unlike most pose-and-scale methods, gP4Pc is based on constraints arising from the congruence of shapes defined by two sets of four points related by an unknown similarity transformation. By choosing a novel parametrization for the problem, we derive a system of four quadratic equations in four scalar variables. The variables represent the distances of 3D points along the rays from the camera centers. After solving this system via Groebner basis-based automatic polynomial solvers, we compute the similarity transformation using an efficient 3D point-point alignment method. We also propose a specialized variant of our solver for the case of coplanar points, which is computationally very efficient and about 3x faster than the fastest existing solver. Our experiments on real and synthetic datasets, demonstrate that gP4Pc is among the fastest methods in terms of total running time when used within a RANSAC framework, while achieving competitive numerical stability, accuracy, and robustness to noise.
HyperSTAR: Task-Aware Hyperparameters for Deep Networks
May 21, 2020
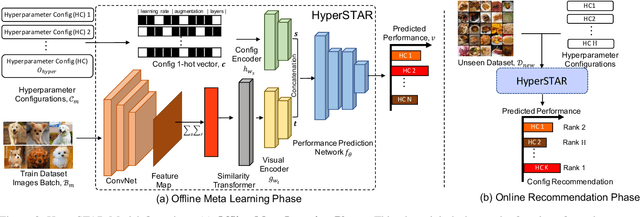

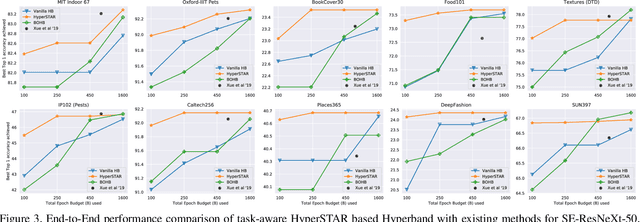
While deep neural networks excel in solving visual recognition tasks, they require significant effort to find hyperparameters that make them work optimally. Hyperparameter Optimization (HPO) approaches have automated the process of finding good hyperparameters but they do not adapt to a given task (task-agnostic), making them computationally inefficient. To reduce HPO time, we present HyperSTAR (System for Task Aware Hyperparameter Recommendation), a task-aware method to warm-start HPO for deep neural networks. HyperSTAR ranks and recommends hyperparameters by predicting their performance conditioned on a joint dataset-hyperparameter space. It learns a dataset (task) representation along with the performance predictor directly from raw images in an end-to-end fashion. The recommendations, when integrated with an existing HPO method, make it task-aware and significantly reduce the time to achieve optimal performance. We conduct extensive experiments on 10 publicly available large-scale image classification datasets over two different network architectures, validating that HyperSTAR evaluates 50% less configurations to achieve the best performance compared to existing methods. We further demonstrate that HyperSTAR makes Hyperband (HB) task-aware, achieving the optimal accuracy in just 25% of the budget required by both vanilla HB and Bayesian Optimized HB~(BOHB).
gDLS*: Generalized Pose-and-Scale Estimation Given Scale and Gravity Priors
Apr 05, 2020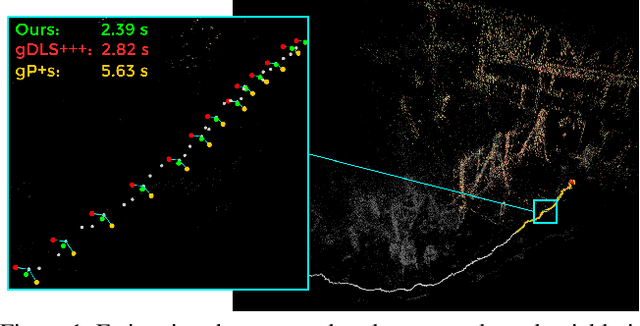
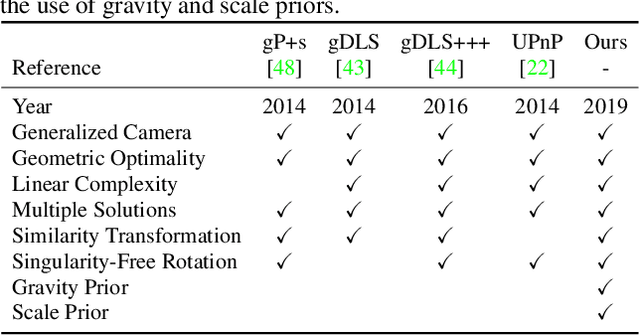
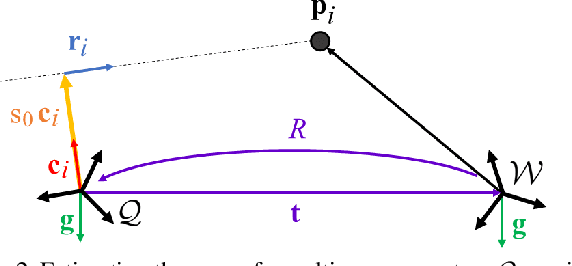
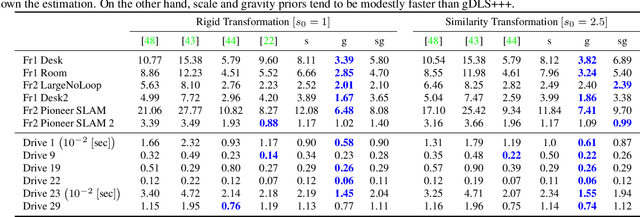
Many real-world applications in augmented reality (AR), 3D mapping, and robotics require both fast and accurate estimation of camera poses and scales from multiple images captured by multiple cameras or a single moving camera. Achieving high speed and maintaining high accuracy in a pose-and-scale estimator are often conflicting goals. To simultaneously achieve both, we exploit a priori knowledge about the solution space. We present gDLS*, a generalized-camera-model pose-and-scale estimator that utilizes rotation and scale priors. gDLS* allows an application to flexibly weigh the contribution of each prior, which is important since priors often come from noisy sensors. Compared to state-of-the-art generalized-pose-and-scale estimators (e.g., gDLS), our experiments on both synthetic and real data consistently demonstrate that gDLS* accelerates the estimation process and improves scale and pose accuracy.
Patch Correspondences for Interpreting Pixel-level CNNs
Sep 04, 2018
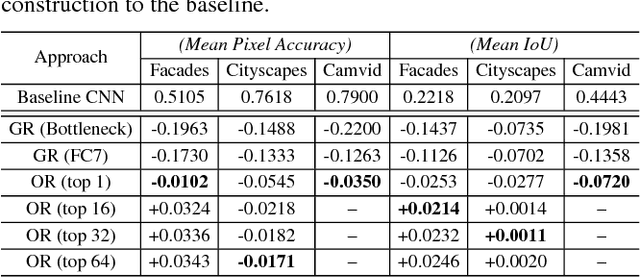
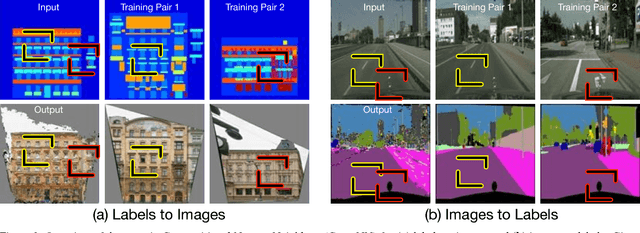
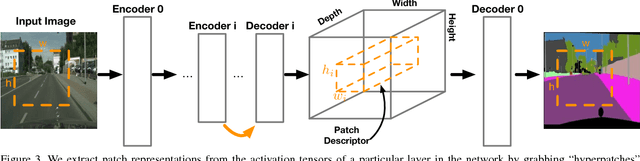
We present compositional nearest neighbors (CompNN), a simple approach to visually interpreting distributed representations learned by a convolutional neural network (CNN) for pixel-level tasks (e.g., image synthesis and segmentation). It does so by reconstructing both a CNN's input and output image by copy-pasting corresponding patches from the training set with similar feature embeddings. To do so efficiently, it makes of a patch-match-based algorithm that exploits the fact that the patch representations learned by a CNN for pixel level tasks vary smoothly. Finally, we show that CompNN can be used to establish semantic correspondences between two images and control properties of the output image by modifying the images contained in the training set. We present qualitative and quantitative experiments for semantic segmentation and image-to-image translation that demonstrate that CompNN is a good tool for interpreting the embeddings learned by pixel-level CNNs.
GraphMatch: Efficient Large-Scale Graph Construction for Structure from Motion
Oct 04, 2017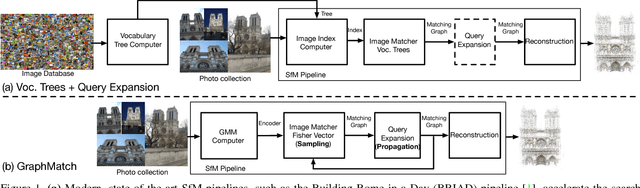

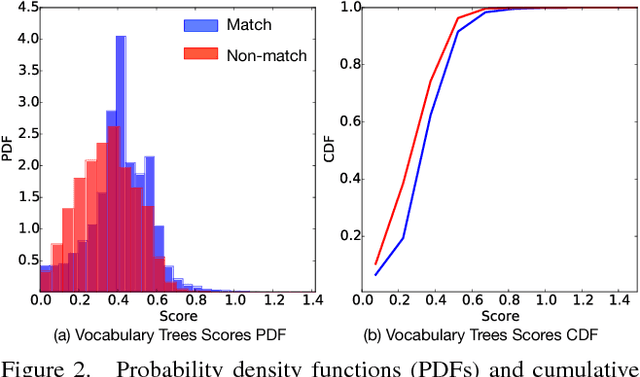
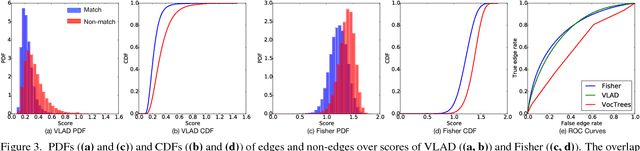
We present GraphMatch, an approximate yet efficient method for building the matching graph for large-scale structure-from-motion (SfM) pipelines. Unlike modern SfM pipelines that use vocabulary (Voc.) trees to quickly build the matching graph and avoid a costly brute-force search of matching image pairs, GraphMatch does not require an expensive offline pre-processing phase to construct a Voc. tree. Instead, GraphMatch leverages two priors that can predict which image pairs are likely to match, thereby making the matching process for SfM much more efficient. The first is a score computed from the distance between the Fisher vectors of any two images. The second prior is based on the graph distance between vertices in the underlying matching graph. GraphMatch combines these two priors into an iterative "sample-and-propagate" scheme similar to the PatchMatch algorithm. Its sampling stage uses Fisher similarity priors to guide the search for matching image pairs, while its propagation stage explores neighbors of matched pairs to find new ones with a high image similarity score. Our experiments show that GraphMatch finds the most image pairs as compared to competing, approximate methods while at the same time being the most efficient.
ANSAC: Adaptive Non-minimal Sample and Consensus
Sep 27, 2017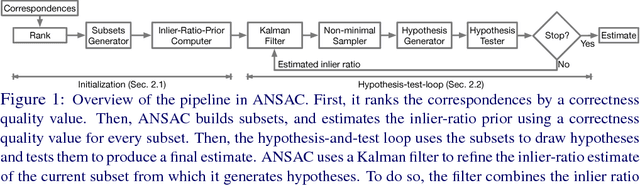



While RANSAC-based methods are robust to incorrect image correspondences (outliers), their hypothesis generators are not robust to correct image correspondences (inliers) with positional error (noise). This slows down their convergence because hypotheses drawn from a minimal set of noisy inliers can deviate significantly from the optimal model. This work addresses this problem by introducing ANSAC, a RANSAC-based estimator that accounts for noise by adaptively using more than the minimal number of correspondences required to generate a hypothesis. ANSAC estimates the inlier ratio (the fraction of correct correspondences) of several ranked subsets of candidate correspondences and generates hypotheses from them. Its hypothesis-generation mechanism prioritizes the use of subsets with high inlier ratio to generate high-quality hypotheses. ANSAC uses an early termination criterion that keeps track of the inlier ratio history and terminates when it has not changed significantly for a period of time. The experiments show that ANSAC finds good homography and fundamental matrix estimates in a few iterations, consistently outperforming state-of-the-art methods.
Large Scale SfM with the Distributed Camera Model
Dec 01, 2016

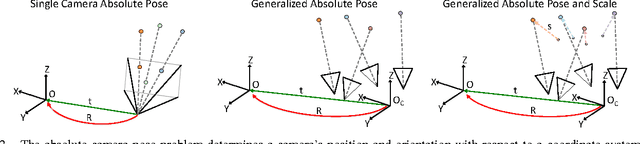

We introduce the distributed camera model, a novel model for Structure-from-Motion (SfM). This model describes image observations in terms of light rays with ray origins and directions rather than pixels. As such, the proposed model is capable of describing a single camera or multiple cameras simultaneously as the collection of all light rays observed. We show how the distributed camera model is a generalization of the standard camera model and describe a general formulation and solution to the absolute camera pose problem that works for standard or distributed cameras. The proposed method computes a solution that is up to 8 times more efficient and robust to rotation singularities in comparison with gDLS. Finally, this method is used in an novel large-scale incremental SfM pipeline where distributed cameras are accurately and robustly merged together. This pipeline is a direct generalization of traditional incremental SfM; however, instead of incrementally adding one camera at a time to grow the reconstruction the reconstruction is grown by adding a distributed camera. Our pipeline produces highly accurate reconstructions efficiently by avoiding the need for many bundle adjustment iterations and is capable of computing a 3D model of Rome from over 15,000 images in just 22 minutes.
One-Class Slab Support Vector Machine
Aug 02, 2016
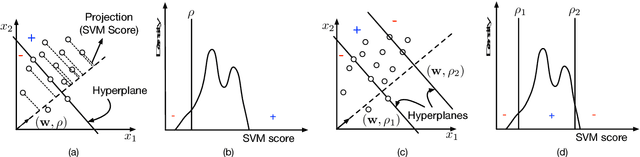
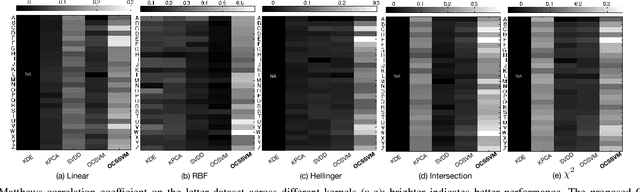

This work introduces the one-class slab SVM (OCSSVM), a one-class classifier that aims at improving the performance of the one-class SVM. The proposed strategy reduces the false positive rate and increases the accuracy of detecting instances from novel classes. To this end, it uses two parallel hyperplanes to learn the normal region of the decision scores of the target class. OCSSVM extends one-class SVM since it can scale and learn non-linear decision functions via kernel methods. The experiments on two publicly available datasets show that OCSSVM can consistently outperform the one-class SVM and perform comparable to or better than other state-of-the-art one-class classifiers.