 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhySe-RPO: Physics and Semantics Guided Relative Policy Optimization for Diffusion-Based Surgical Smoke Removal
Mar 25, 2026Surgical smoke severely degrades intraoperative video quality, obscuring anatomical structures and limiting surgical perception. Existing learning-based desmoking approaches rely on scarce paired supervision and deterministic restoration pipelines, making it difficult to perform exploration or reinforcement-driven refinement under real surgical conditions. We propose PhySe-RPO, a diffusion restoration framework optimized through Physics- and Semantics-Guided Relative Policy Optimization. The core idea is to transform deterministic restoration into a stochastic policy, enabling trajectory-level exploration and critic-free updates via group-relative optimization. A physics-guided reward imposes illumination and color consistency, while a visual-concept semantic reward learned from CLIP-based surgical concepts promotes smoke-free and anatomically coherent restoration. Together with a reference-free perceptual constraint, PhySe-RPO produces results that are physically consistent, semantically faithful, and clinically interpretable across synthetic and real robotic surgical datasets, providing a principled route to robust diffusion-based restoration under limited paired supervision.
LaT: Latent Translation with Cycle-Consistency for Video-Text Retrieval
Jul 11, 2022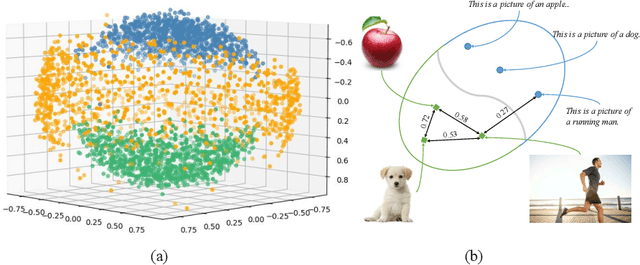
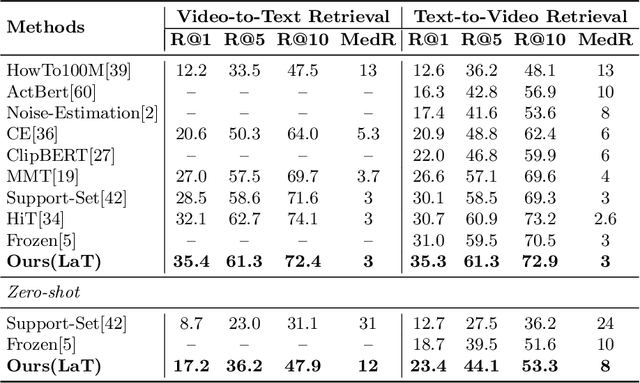
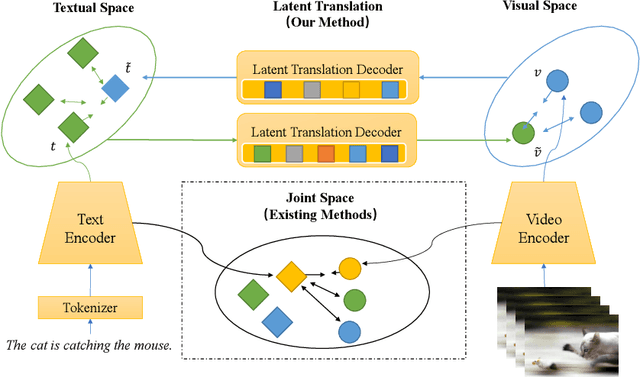
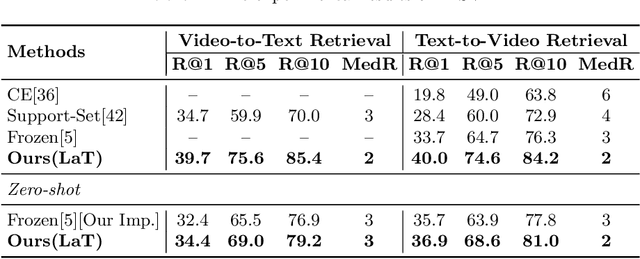
Video-text retrieval is a class of cross-modal representation learning problems, where the goal is to select the video which corresponds to the text query between a given text query and a pool of candidate videos. The contrastive paradigm of vision-language pretraining has shown promising success with large-scale datasets and unified transformer architecture, and demonstrated the power of a joint latent space. Despite this, the intrinsic divergence between the visual domain and textual domain is still far from being eliminated, and projecting different modalities into a joint latent space might result in the distorting of the information inside the single modality. To overcome the above issue, we present a novel mechanism for learning the translation relationship from a source modality space $\mathcal{S}$ to a target modality space $\mathcal{T}$ without the need for a joint latent space, which bridges the gap between visual and textual domains. Furthermore, to keep cycle consistency between translations, we adopt a cycle loss involving both forward translations from $\mathcal{S}$ to the predicted target space $\mathcal{T'}$, and backward translations from $\mathcal{T'}$ back to $\mathcal{S}$. Extensive experiments conducted on MSR-VTT, MSVD, and DiDeMo datasets demonstrate the superiority and effectiveness of our LaT approach compared with vanilla state-of-the-art methods.
Unsupervised Action Segmentation with Self-supervised Feature Learning and Co-occurrence Parsing
Jun 02, 2021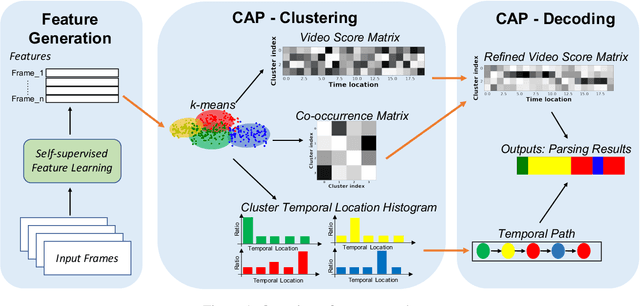
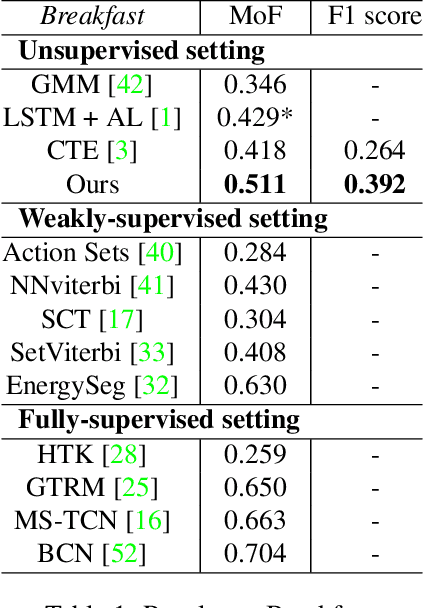
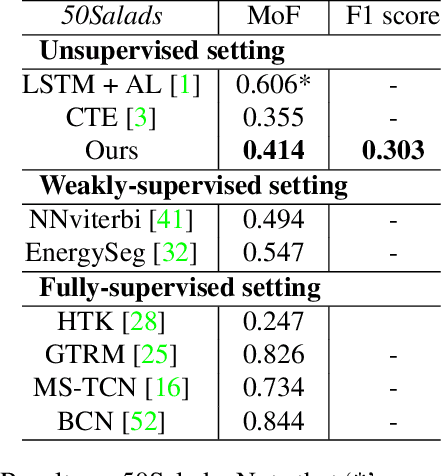
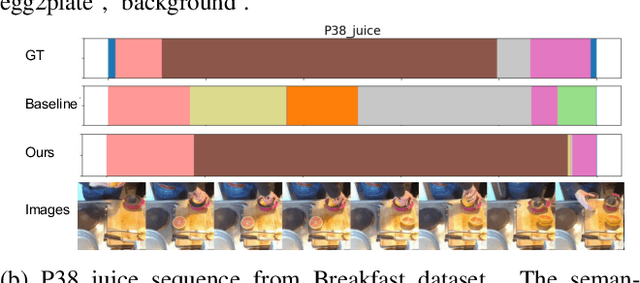
Temporal action segmentation is a task to classify each frame in the video with an action label. However, it is quite expensive to annotate every frame in a large corpus of videos to construct a comprehensive supervised training dataset. Thus in this work we explore a self-supervised method that operates on a corpus of unlabeled videos and predicts a likely set of temporal segments across the videos. To do this we leverage self-supervised video classification approaches to perform unsupervised feature extraction. On top of these features we develop CAP, a novel co-occurrence action parsing algorithm that can not only capture the correlation among sub-actions underlying the structure of activities, but also estimate the temporal trajectory of the sub-actions in an accurate and general way. We evaluate on both classic datasets (Breakfast, 50Salads) and emerging fine-grained action datasets (FineGym) with more complex activity structures and similar sub-actions. Results show that our method achieves state-of-the-art performance on all three datasets with up to 22\% improvement, and can even outperform some weakly-supervised approaches, demonstrating its effectiveness and generalizability.
VidTr: Video Transformer Without Convolutions
Apr 23, 2021
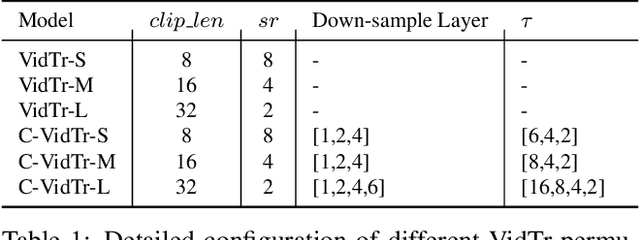
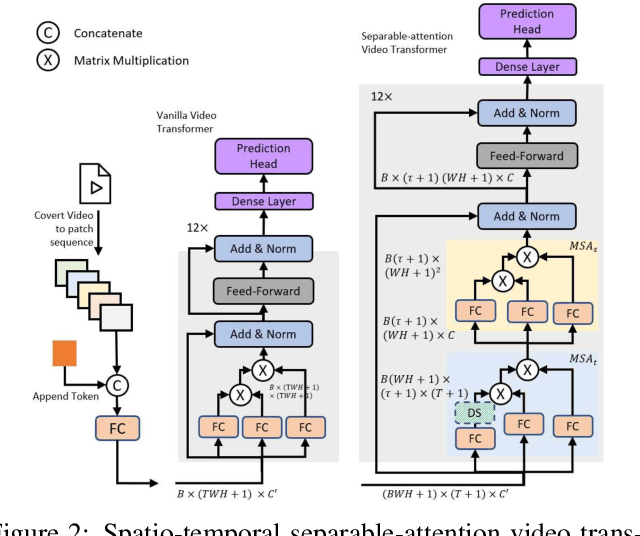
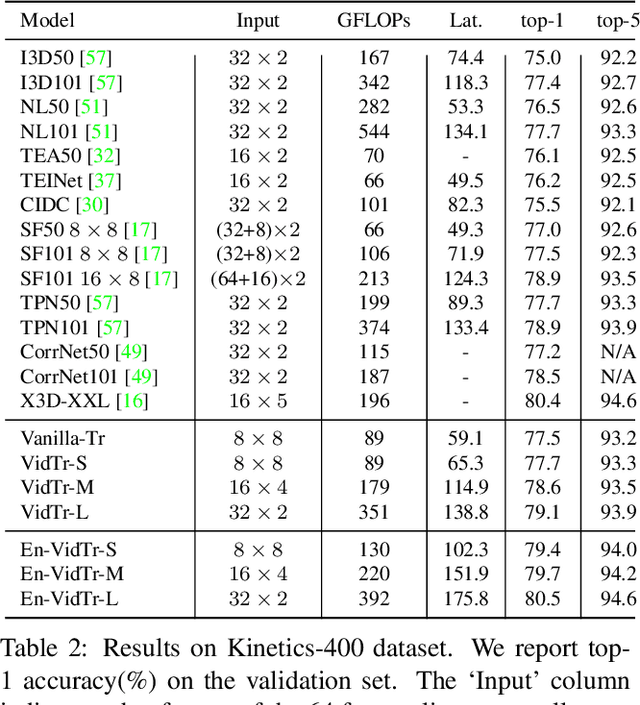
We introduce Video Transformer (VidTr) with separable-attention for video classification. Comparing with commonly used 3D networks, VidTr is able to aggregate spatio-temporal information via stacked attentions and provide better performance with higher efficiency. We first introduce the vanilla video transformer and show that transformer module is able to perform spatio-temporal modeling from raw pixels, but with heavy memory usage. We then present VidTr which reduces the memory cost by 3.3$\times$ while keeping the same performance. To further compact the model, we propose the standard deviation based topK pooling attention, which reduces the computation by dropping non-informative features. VidTr achieves state-of-the-art performance on five commonly used dataset with lower computational requirement, showing both the efficiency and effectiveness of our design. Finally, error analysis and visualization show that VidTr is especially good at predicting actions that require long-term temporal reasoning. The code and pre-trained weights will be released.
TubeR: Tube-Transformer for Action Detection
Apr 09, 2021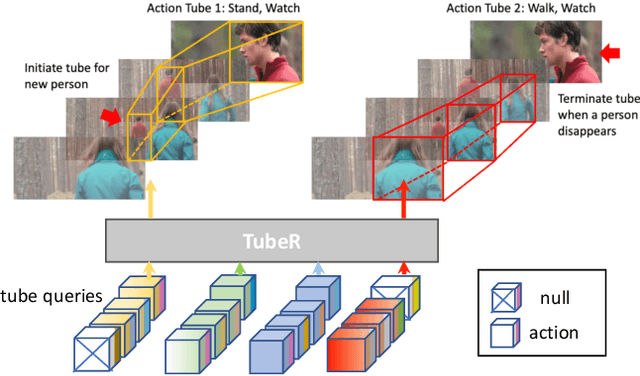
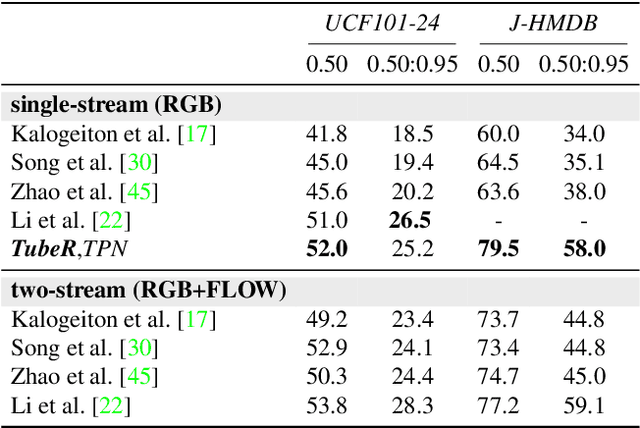
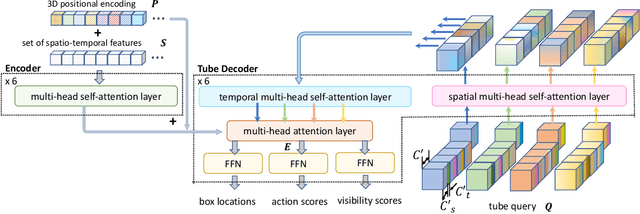

In this paper, we propose TubeR: the first transformer based network for end-to-end action detection, with an encoder and decoder optimized for modeling action tubes with variable lengths and aspect ratios. TubeR does not rely on hand-designed tube structures, automatically links predicted action boxes over time and learns a set of tube queries related to actions. By learning action tube embeddings, TubeR predicts more precise action tubes with flexible spatial and temporal extents. Our experiments demonstrate TubeR achieves state-of-the-art among single-stream methods on UCF101-24 and J-HMDB. TubeR outperforms existing one-model methods on AVA and is even competitive with the two-model methods. Moreover, we observe TubeR has the potential on tracking actors with different actions, which will foster future research in long-range video understanding.
Selective Feature Compression for Efficient Activity Recognition Inference
Apr 01, 2021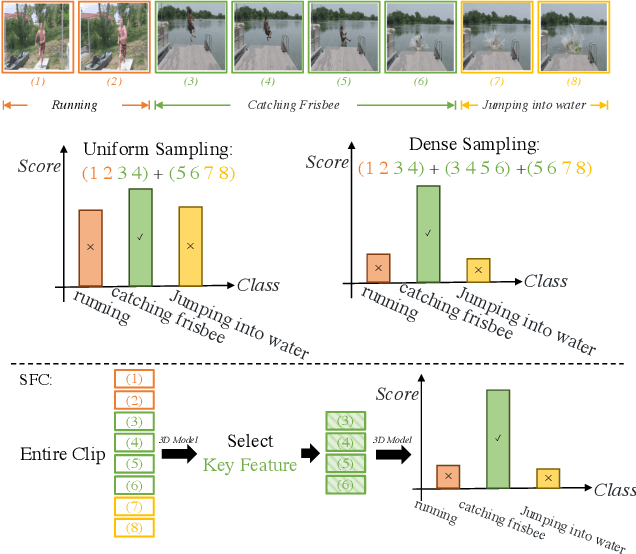

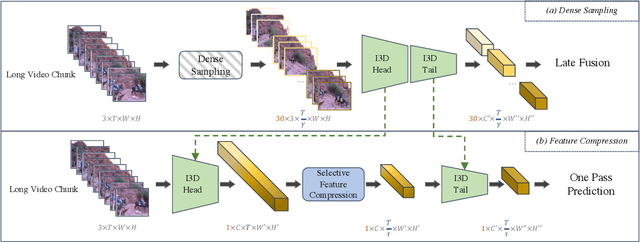

Most action recognition solutions rely on dense sampling to precisely cover the informative temporal clip. Extensively searching temporal region is expensive for a real-world application. In this work, we focus on improving the inference efficiency of current action recognition backbones on trimmed videos, and illustrate that one action model can also cover then informative region by dropping non-informative features. We present Selective Feature Compression (SFC), an action recognition inference strategy that greatly increase model inference efficiency without any accuracy compromise. Differently from previous works that compress kernel sizes and decrease the channel dimension, we propose to compress feature flow at spatio-temporal dimension without changing any backbone parameters. Our experiments on Kinetics-400, UCF101 and ActivityNet show that SFC is able to reduce inference speed by 6-7x and memory usage by 5-6x compared with the commonly used 30 crops dense sampling procedure, while also slightly improving Top1 Accuracy. We thoroughly quantitatively and qualitatively evaluate SFC and all its components and show how does SFC learn to attend to important video regions and to drop temporal features that are uninformative for the task of action recognition.
NUTA: Non-uniform Temporal Aggregation for Action Recognition
Dec 15, 2020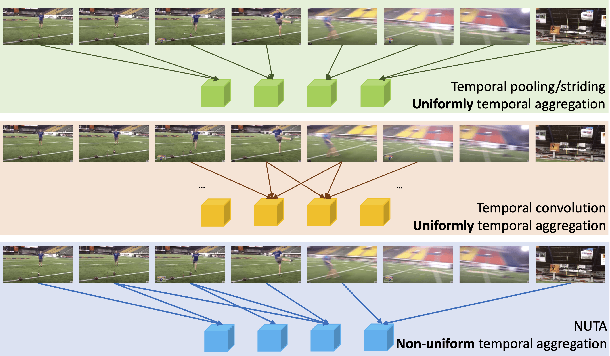
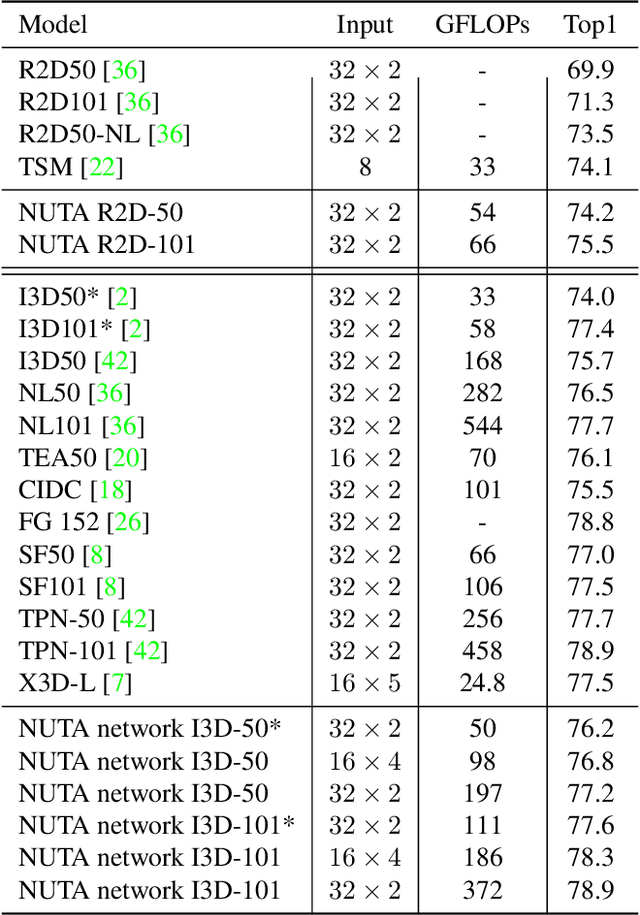
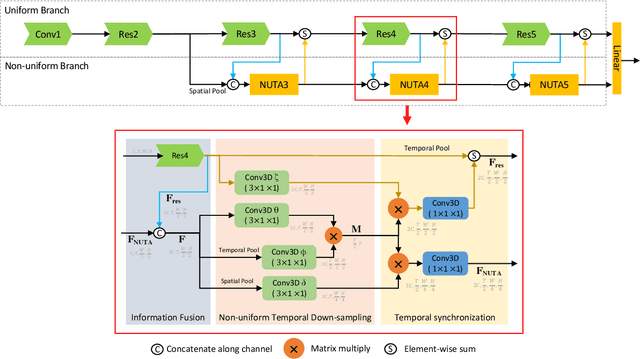
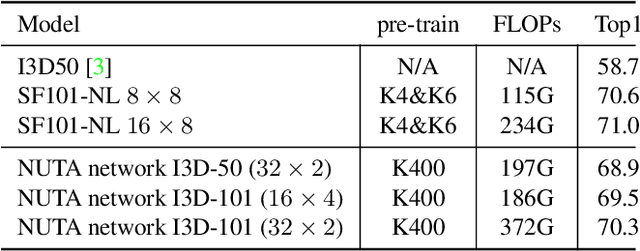
In the world of action recognition research, one primary focus has been on how to construct and train networks to model the spatial-temporal volume of an input video. These methods typically uniformly sample a segment of an input clip (along the temporal dimension). However, not all parts of a video are equally important to determine the action in the clip. In this work, we focus instead on learning where to extract features, so as to focus on the most informative parts of the video. We propose a method called the non-uniform temporal aggregation (NUTA), which aggregates features only from informative temporal segments. We also introduce a synchronization method that allows our NUTA features to be temporally aligned with traditional uniformly sampled video features, so that both local and clip-level features can be combined. Our model has achieved state-of-the-art performance on four widely used large-scale action-recognition datasets (Kinetics400, Kinetics700, Something-something V2 and Charades). In addition, we have created a visualization to illustrate how the proposed NUTA method selects only the most relevant parts of a video clip.
A Comprehensive Study of Deep Video Action Recognition
Dec 11, 2020
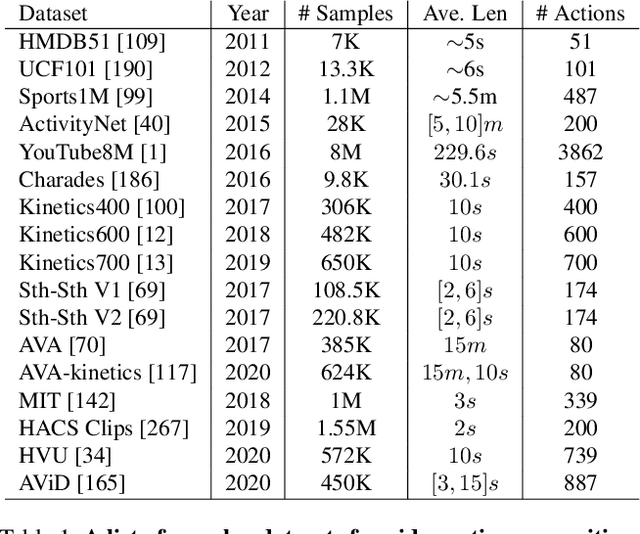
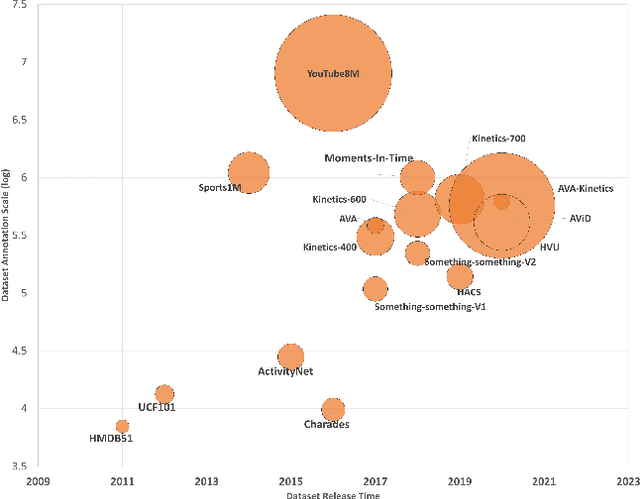
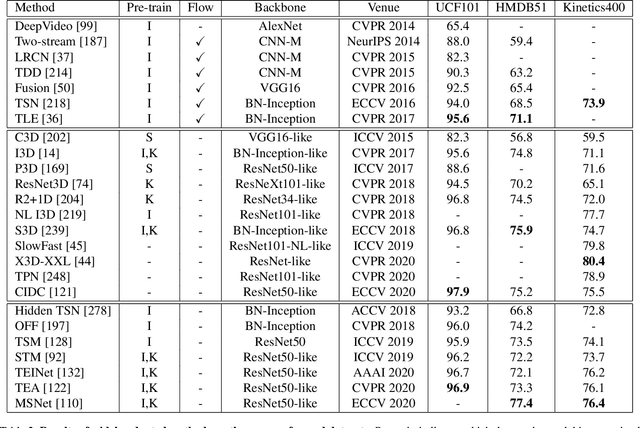
Video action recognition is one of the representative tasks for video understanding. Over the last decade, we have witnessed great advancements in video action recognition thanks to the emergence of deep learning. But we also encountered new challenges, including modeling long-range temporal information in videos, high computation costs, and incomparable results due to datasets and evaluation protocol variances. In this paper, we provide a comprehensive survey of over 200 existing papers on deep learning for video action recognition. We first introduce the 17 video action recognition datasets that influenced the design of models. Then we present video action recognition models in chronological order: starting with early attempts at adapting deep learning, then to the two-stream networks, followed by the adoption of 3D convolutional kernels, and finally to the recent compute-efficient models. In addition, we benchmark popular methods on several representative datasets and release code for reproducibility. In the end, we discuss open problems and shed light on opportunities for video action recognition to facilitate new research ideas.
Triplet Online Instance Matching Loss for Person Re-identification
Feb 24, 2020


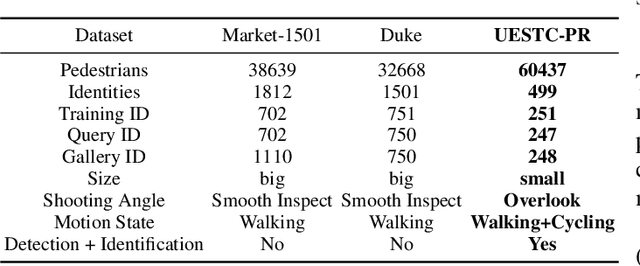
Mining the shared features of same identity in different scene, and the unique features of different identity in same scene, are most significant challenges in the field of person re-identification (ReID). Online Instance Matching (OIM) loss function and Triplet loss function are main methods for person ReID. Unfortunately, both of them have drawbacks. OIM loss treats all samples equally and puts no emphasis on hard samples. Triplet loss processes batch construction in a complicated and fussy way and converges slowly. For these problems, we propose a Triplet Online Instance Matching (TOIM) loss function, which lays emphasis on the hard samples and improves the accuracy of person ReID effectively. It combines the advantages of OIM loss and Triplet loss and simplifies the process of batch construction, which leads to a more rapid convergence. It can be trained on-line when handle the joint detection and identification task. To validate our loss function, we collect and annotate a large-scale benchmark dataset (UESTC-PR) based on images taken from surveillance cameras, which contains 499 identities and 60,437 images. We evaluated our proposed loss function on Duke, Marker-1501 and UESTC-PR using ResNet-50, and the result shows that our proposed loss function outperforms the baseline methods by a maximum of 21.7%, including Softmax loss, OIM loss and Triplet loss.
Patch Correspondences for Interpreting Pixel-level CNNs
Sep 04, 2018
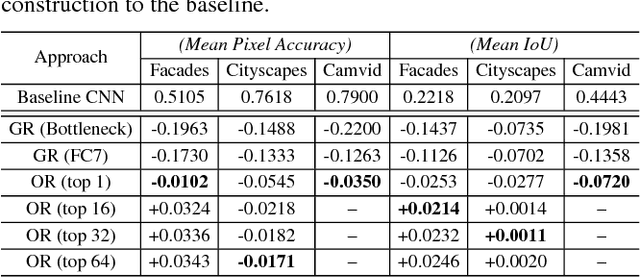
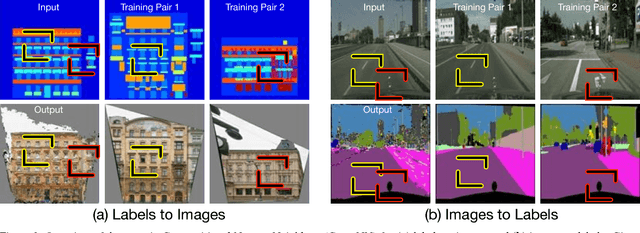
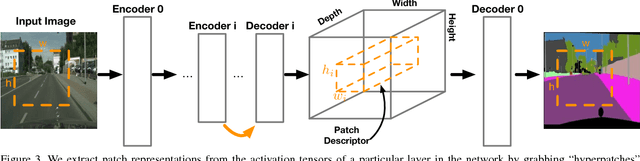
We present compositional nearest neighbors (CompNN), a simple approach to visually interpreting distributed representations learned by a convolutional neural network (CNN) for pixel-level tasks (e.g., image synthesis and segmentation). It does so by reconstructing both a CNN's input and output image by copy-pasting corresponding patches from the training set with similar feature embeddings. To do so efficiently, it makes of a patch-match-based algorithm that exploits the fact that the patch representations learned by a CNN for pixel level tasks vary smoothly. Finally, we show that CompNN can be used to establish semantic correspondences between two images and control properties of the output image by modifying the images contained in the training set. We present qualitative and quantitative experiments for semantic segmentation and image-to-image translation that demonstrate that CompNN is a good tool for interpreting the embeddings learned by pixel-level CNNs.