 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Feature Compression for Efficient Activity Recognition Inference
Paper and Code
Apr 01, 2021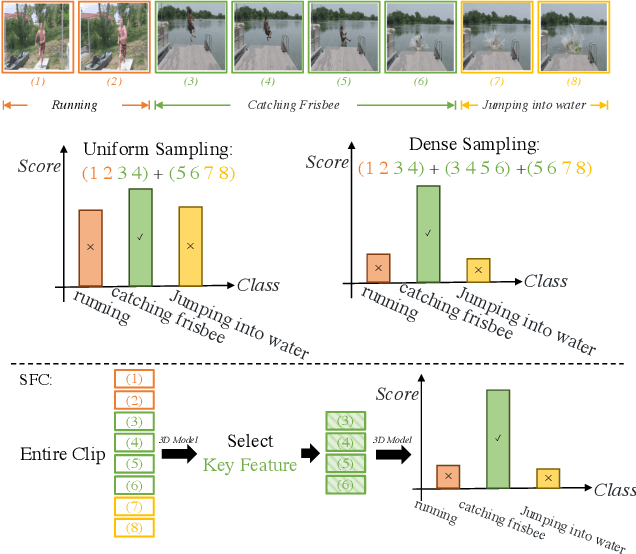

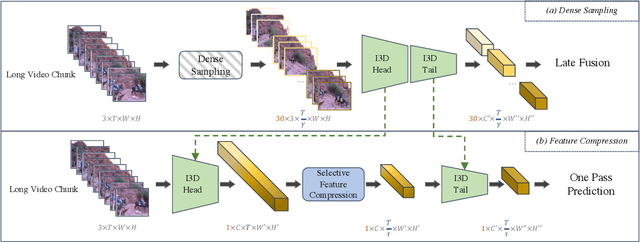

Most action recognition solutions rely on dense sampling to precisely cover the informative temporal clip. Extensively searching temporal region is expensive for a real-world application. In this work, we focus on improving the inference efficiency of current action recognition backbones on trimmed videos, and illustrate that one action model can also cover then informative region by dropping non-informative features. We present Selective Feature Compression (SFC), an action recognition inference strategy that greatly increase model inference efficiency without any accuracy compromise. Differently from previous works that compress kernel sizes and decrease the channel dimension, we propose to compress feature flow at spatio-temporal dimension without changing any backbone parameters. Our experiments on Kinetics-400, UCF101 and ActivityNet show that SFC is able to reduce inference speed by 6-7x and memory usage by 5-6x compared with the commonly used 30 crops dense sampling procedure, while also slightly improving Top1 Accuracy. We thoroughly quantitatively and qualitatively evaluate SFC and all its components and show how does SFC learn to attend to important video regions and to drop temporal features that are uninformative for the task of action recognition.