 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos
Mar 23, 2021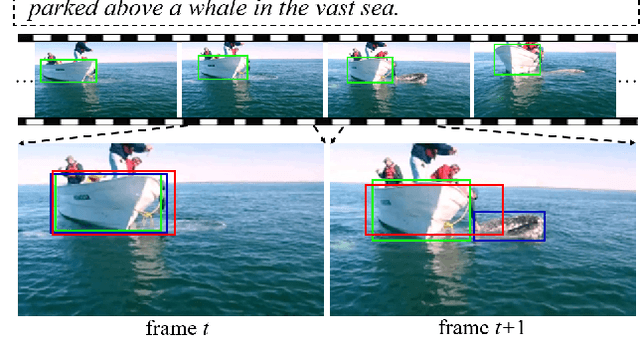
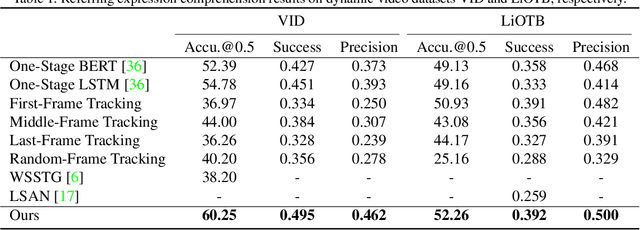
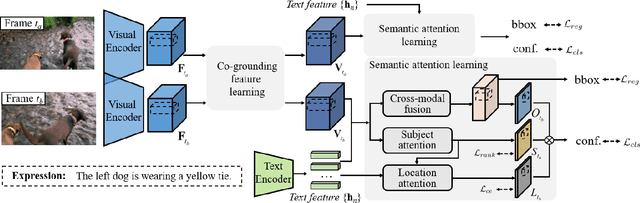
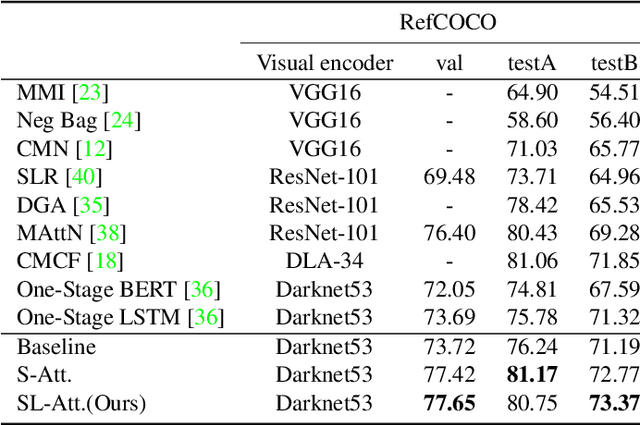
In this paper, we address the problem of referring expression comprehension in videos, which is challenging due to complex expression and scene dynamics. Unlike previous methods which solve the problem in multiple stages (i.e., tracking, proposal-based matching), we tackle the problem from a novel perspective, \textbf{co-grounding}, with an elegant one-stage framework. We enhance the single-frame grounding accuracy by semantic attention learning and improve the cross-frame grounding consistency with co-grounding feature learning. Semantic attention learning explicitly parses referring cues in different attributes to reduce the ambiguity in the complex expression. Co-grounding feature learning boosts visual feature representations by integrating temporal correlation to reduce the ambiguity caused by scene dynamics. Experiment results demonstrate the superiority of our framework on the video grounding datasets VID and LiOTB in generating accurate and stable results across frames. Our model is also applicable to referring expression comprehension in images, illustrated by the improved performance on the RefCOCO dataset. Our project is available at https://sijiesong.github.io/co-grounding.
MS$^2$L: Multi-Task Self-Supervised Learning for Skeleton Based Action Recognition
Oct 14, 2020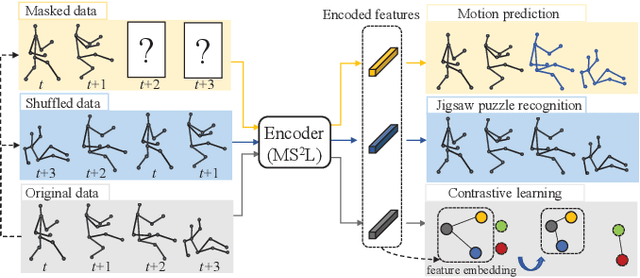

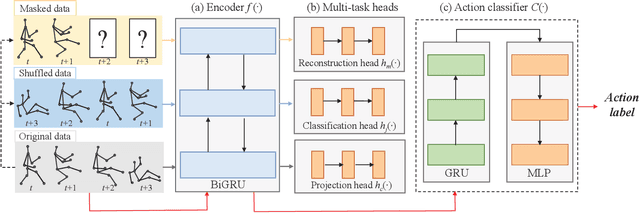
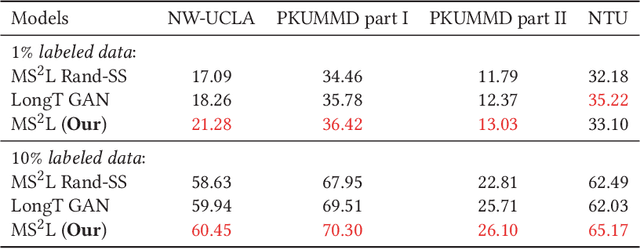
In this paper, we address self-supervised representation learning from human skeletons for action recognition. Previous methods, which usually learn feature presentations from a single reconstruction task, may come across the overfitting problem, and the features are not generalizable for action recognition. Instead, we propose to integrate multiple tasks to learn more general representations in a self-supervised manner. To realize this goal, we integrate motion prediction, jigsaw puzzle recognition, and contrastive learning to learn skeleton features from different aspects. Skeleton dynamics can be modeled through motion prediction by predicting the future sequence. And temporal patterns, which are critical for action recognition, are learned through solving jigsaw puzzles. We further regularize the feature space by contrastive learning. Besides, we explore different training strategies to utilize the knowledge from self-supervised tasks for action recognition. We evaluate our multi-task self-supervised learning approach with action classifiers trained under different configurations, including unsupervised, semi-supervised and fully-supervised settings. Our experiments on the NW-UCLA, NTU RGB+D, and PKUMMD datasets show remarkable performance for action recognition, demonstrating the superiority of our method in learning more discriminative and general features. Our project website is available at https://langlandslin.github.io/projects/MSL/.
Fashion Meets Computer Vision: A Survey
Mar 31, 2020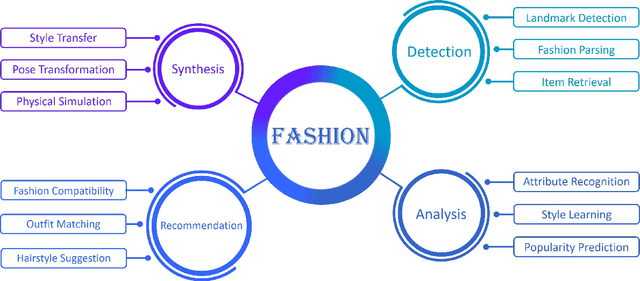


Fashion is the way we present ourselves to the world and has become one of the world's largest industries. Fashion, mainly conveyed by vision, has thus attracted much attention from computer vision researchers in recent years. Given the rapid development, this paper provides a comprehensive survey of more than 200 major fashion-related works covering four main aspects for enabling intelligent fashion: (1) Fashion detection includes landmark detection, fashion parsing, and item retrieval, (2) Fashion analysis contains attribute recognition, style learning, and popularity prediction, (3) Fashion synthesis involves style transfer, pose transformation, and physical simulation, and (4) Fashion recommendation comprises fashion compatibility, outfit matching, and hairstyle suggestion. For each task, the benchmark datasets and the evaluation protocols are summarized. Furthermore, we highlight promising directions for future research.
Modality Compensation Network: Cross-Modal Adaptation for Action Recognition
Jan 31, 2020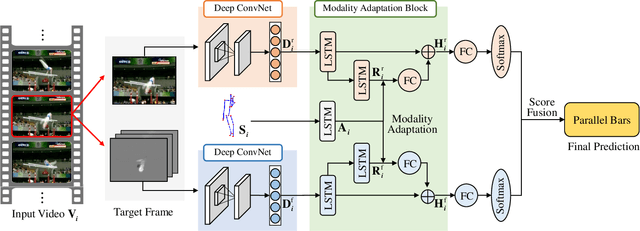
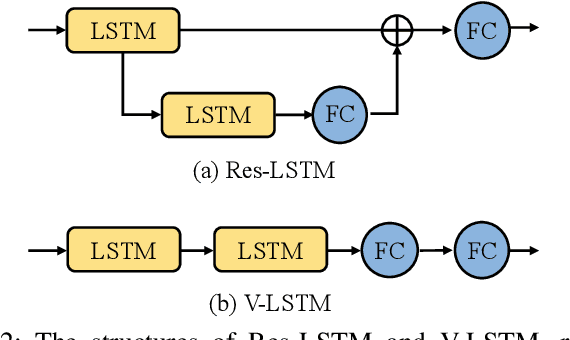
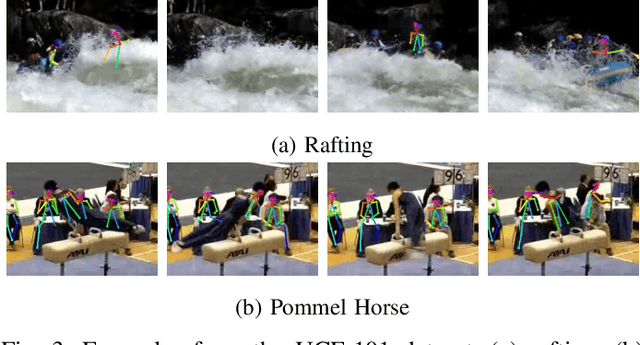
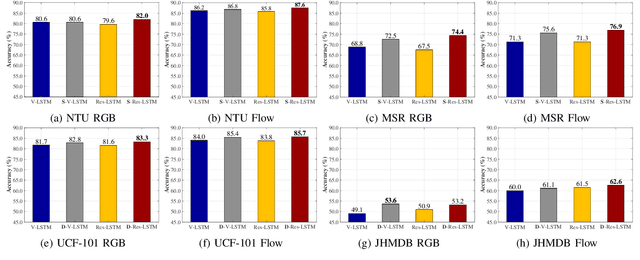
With the prevalence of RGB-D cameras, multi-modal video data have become more available for human action recognition. One main challenge for this task lies in how to effectively leverage their complementary information. In this work, we propose a Modality Compensation Network (MCN) to explore the relationships of different modalities, and boost the representations for human action recognition. We regard RGB/optical flow videos as source modalities, skeletons as auxiliary modality. Our goal is to extract more discriminative features from source modalities, with the help of auxiliary modality. Built on deep Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM) networks, our model bridges data from source and auxiliary modalities by a modality adaptation block to achieve adaptive representation learning, that the network learns to compensate for the loss of skeletons at test time and even at training time. We explore multiple adaptation schemes to narrow the distance between source and auxiliary modal distributions from different levels, according to the alignment of source and auxiliary data in training. In addition, skeletons are only required in the training phase. Our model is able to improve the recognition performance with source data when testing. Experimental results reveal that MCN outperforms state-of-the-art approaches on four widely-used action recognition benchmarks.
Unsupervised Person Image Generation with Semantic Parsing Transformation
Apr 18, 2019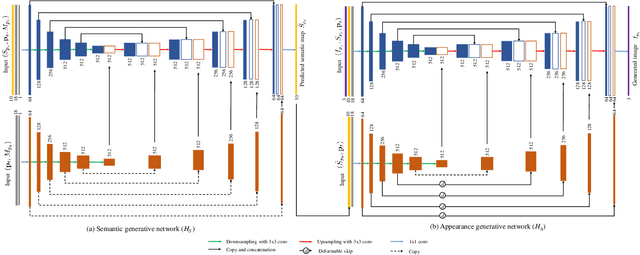

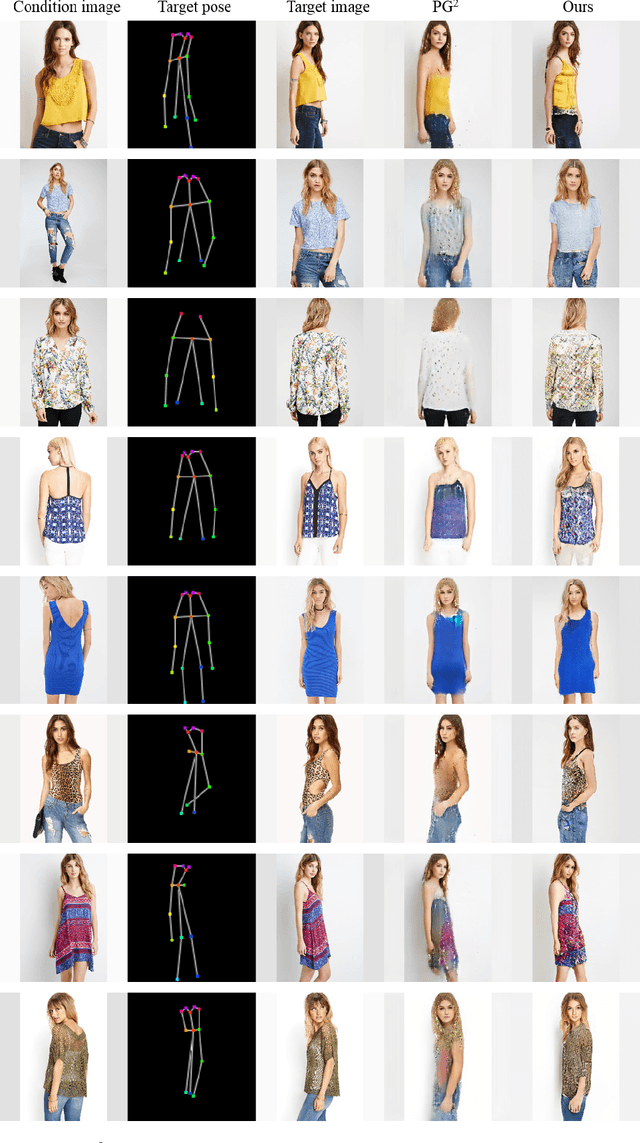
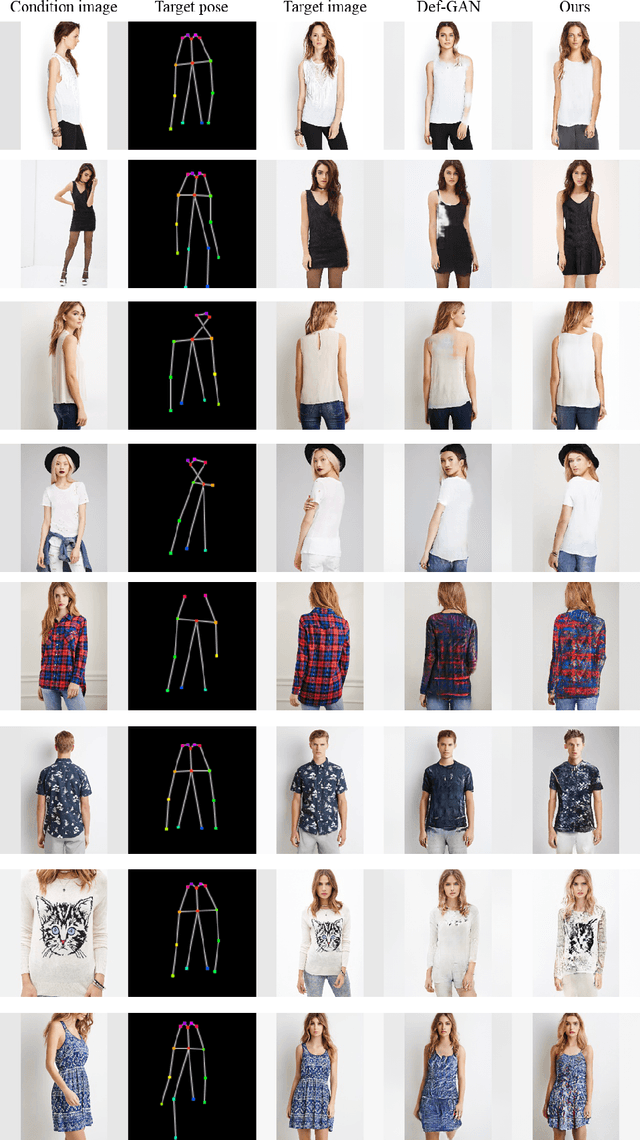
In this paper, we address unsupervised pose-guided person image generation, which is known challenging due to non-rigid deformation. Unlike previous methods learning a rock-hard direct mapping between human bodies, we propose a new pathway to decompose the hard mapping into two more accessible subtasks, namely, semantic parsing transformation and appearance generation. Firstly, a semantic generative network is proposed to transform between semantic parsing maps, in order to simplify the non-rigid deformation learning. Secondly, an appearance generative network learns to synthesize semantic-aware textures. Thirdly, we demonstrate that training our framework in an end-to-end manner further refines the semantic maps and final results accordingly. Our method is generalizable to other semantic-aware person image generation tasks, eg, clothing texture transfer and controlled image manipulation. Experimental results demonstrate the superiority of our method on DeepFashion and Market-1501 datasets, especially in keeping the clothing attributes and better body shapes.
Temporal Bilinear Networks for Video Action Recognition
Nov 25, 2018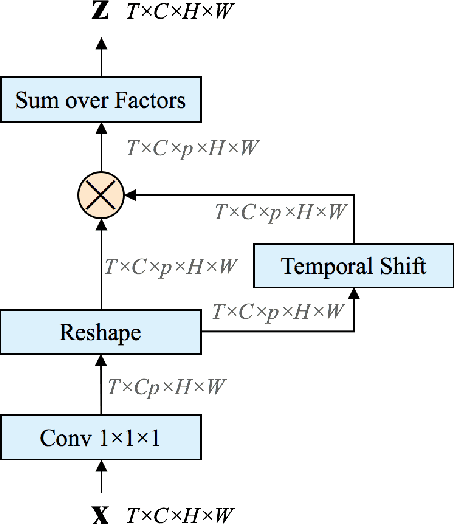

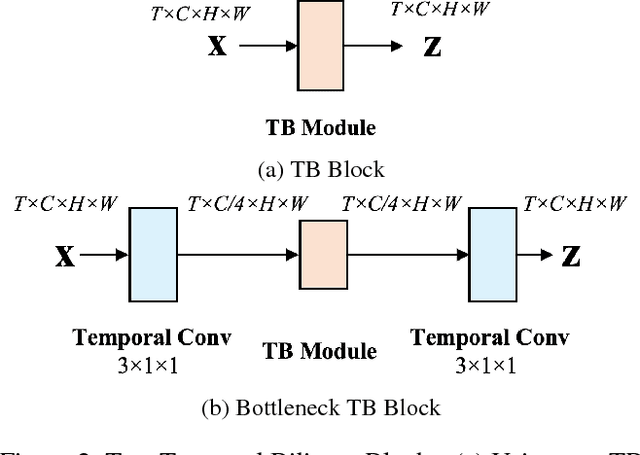

Temporal modeling in videos is a fundamental yet challenging problem in computer vision. In this paper, we propose a novel Temporal Bilinear (TB) model to capture the temporal pairwise feature interactions between adjacent frames. Compared with some existing temporal methods which are limited in linear transformations, our TB model considers explicit quadratic bilinear transformations in the temporal domain for motion evolution and sequential relation modeling. We further leverage the factorized bilinear model in linear complexity and a bottleneck network design to build our TB blocks, which also constrains the parameters and computation cost. We consider two schemes in terms of the incorporation of TB blocks and the original 2D spatial convolutions, namely wide and deep Temporal Bilinear Networks (TBN). Finally, we perform experiments on several widely adopted datasets including Kinetics, UCF101 and HMDB51. The effectiveness of our TBNs is validated by comprehensive ablation analyses and comparisons with various state-of-the-art methods.
PKU-MMD: A Large Scale Benchmark for Continuous Multi-Modal Human Action Understanding
Mar 28, 2017
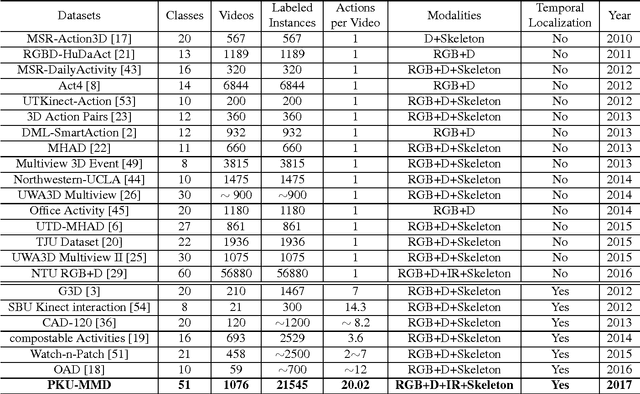


Despite the fact that many 3D human activity benchmarks being proposed, most existing action datasets focus on the action recognition tasks for the segmented videos. There is a lack of standard large-scale benchmarks, especially for current popular data-hungry deep learning based methods. In this paper, we introduce a new large scale benchmark (PKU-MMD) for continuous multi-modality 3D human action understanding and cover a wide range of complex human activities with well annotated information. PKU-MMD contains 1076 long video sequences in 51 action categories, performed by 66 subjects in three camera views. It contains almost 20,000 action instances and 5.4 million frames in total. Our dataset also provides multi-modality data sources, including RGB, depth, Infrared Radiation and Skeleton. With different modalities, we conduct extensive experiments on our dataset in terms of two scenarios and evaluate different methods by various metrics, including a new proposed evaluation protocol 2D-AP. We believe this large-scale dataset will benefit future researches on action detection for the community.
An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data
Nov 18, 2016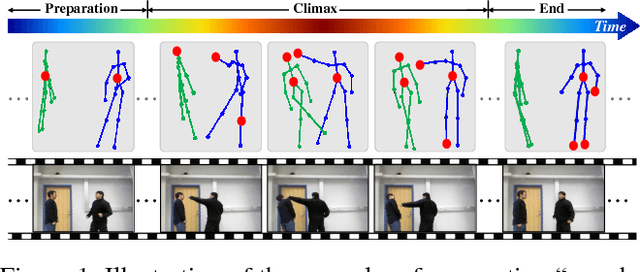
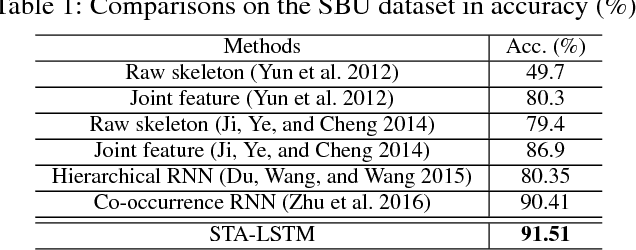
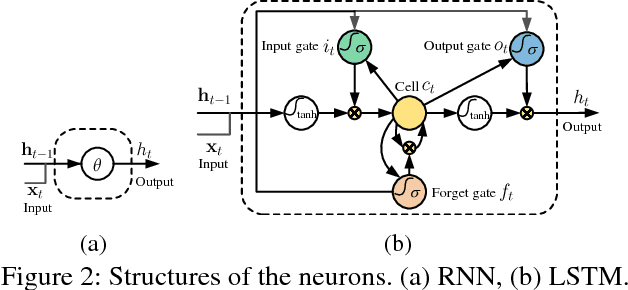

Human action recognition is an important task in computer vision. Extracting discriminative spatial and temporal features to model the spatial and temporal evolutions of different actions plays a key role in accomplishing this task. In this work, we propose an end-to-end spatial and temporal attention model for human action recognition from skeleton data. We build our model on top of the Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM), which learns to selectively focus on discriminative joints of skeleton within each frame of the inputs and pays different levels of attention to the outputs of different frames. Furthermore, to ensure effective training of the network, we propose a regularized cross-entropy loss to drive the model learning process and develop a joint training strategy accordingly. Experimental results demonstrate the effectiveness of the proposed model,both on the small human action recognition data set of SBU and the currently largest NTU dataset.