 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data
Paper and Code
Nov 18, 2016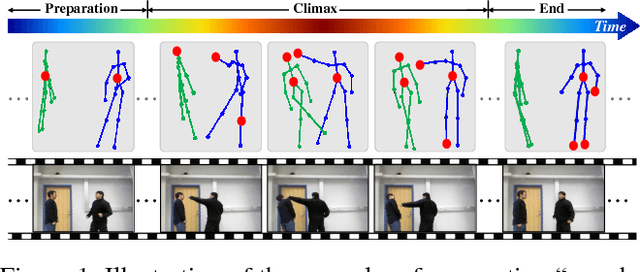
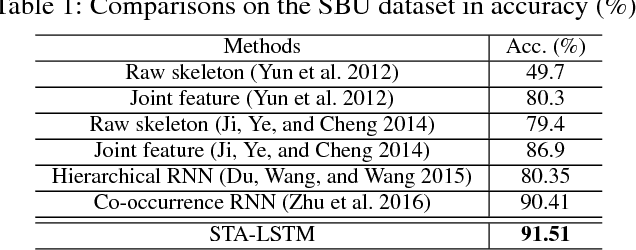
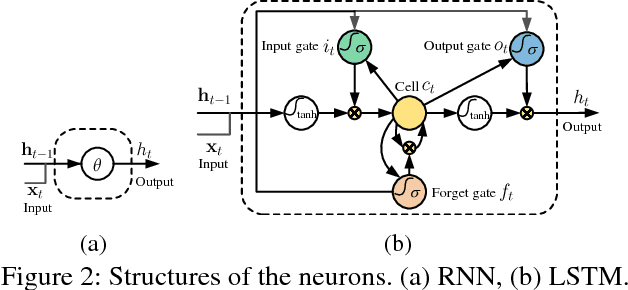

Human action recognition is an important task in computer vision. Extracting discriminative spatial and temporal features to model the spatial and temporal evolutions of different actions plays a key role in accomplishing this task. In this work, we propose an end-to-end spatial and temporal attention model for human action recognition from skeleton data. We build our model on top of the Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM), which learns to selectively focus on discriminative joints of skeleton within each frame of the inputs and pays different levels of attention to the outputs of different frames. Furthermore, to ensure effective training of the network, we propose a regularized cross-entropy loss to drive the model learning process and develop a joint training strategy accordingly. Experimental results demonstrate the effectiveness of the proposed model,both on the small human action recognition data set of SBU and the currently largest NTU dataset.