 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridPrompt: Bridging Generative Priors and Traditional Codecs for Mobile Streaming
Feb 19, 2026In Video on Demand (VoD) scenarios, traditional codecs are the industry standard due to their high decoding efficiency. However, they suffer from severe quality degradation under low bandwidth conditions. While emerging generative neural codecs offer significantly higher perceptual quality, their reliance on heavy frame-by-frame generation makes real-time playback on mobile devices impractical. We ask: is it possible to combine the blazing-fast speed of traditional standards with the superior visual fidelity of neural approaches? We present HybridPrompt, the first generative-based video system capable of achieving real-time 1080p decoding at over 150 FPS on a commercial smartphone. Specifically, we employ a hybrid architecture that encodes Keyframes using a generative model while relying on traditional codecs for the remaining frames. A major challenge is that the two paradigms have conflicting objectives: the "hallucinated" details from generative models often misalign with the rigid prediction mechanisms of traditional codecs, causing bitrate inefficiency. To address this, we demonstrate that the traditional decoding process is differentiable, enabling an end-to-end optimization loop. This allows us to use subsequent frames as additional supervision, forcing the generative model to synthesize keyframes that are not only perceptually high-fidelity but also mathematically optimal references for the traditional codec. By integrating a two-stage generation strategy, our system outperforms pure neural baselines by orders of magnitude in speed while achieving an average LPIPS gain of 8% over traditional codecs at 200kbps.
GaussVideoDreamer: 3D Scene Generation with Video Diffusion and Inconsistency-Aware Gaussian Splatting
Apr 16, 2025

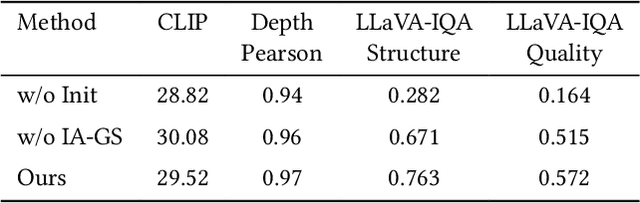
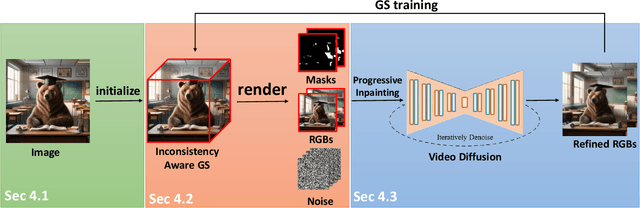
Single-image 3D scene reconstruction presents significant challenges due to its inherently ill-posed nature and limited input constraints. Recent advances have explored two promising directions: multiview generative models that train on 3D consistent datasets but struggle with out-of-distribution generalization, and 3D scene inpainting and completion frameworks that suffer from cross-view inconsistency and suboptimal error handling, as they depend exclusively on depth data or 3D smoothness, which ultimately degrades output quality and computational performance. Building upon these approaches, we present GaussVideoDreamer, which advances generative multimedia approaches by bridging the gap between image, video, and 3D generation, integrating their strengths through two key innovations: (1) A progressive video inpainting strategy that harnesses temporal coherence for improved multiview consistency and faster convergence. (2) A 3D Gaussian Splatting consistency mask to guide the video diffusion with 3D consistent multiview evidence. Our pipeline combines three core components: a geometry-aware initialization protocol, Inconsistency-Aware Gaussian Splatting, and a progressive video inpainting strategy. Experimental results demonstrate that our approach achieves 32% higher LLaVA-IQA scores and at least 2x speedup compared to existing methods while maintaining robust performance across diverse scenes.
PromptMobile: Efficient Promptus for Low Bandwidth Mobile Video Streaming
Mar 20, 2025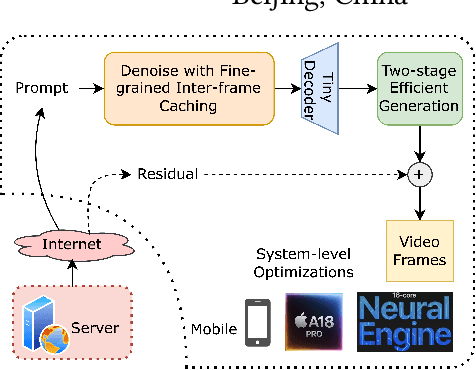
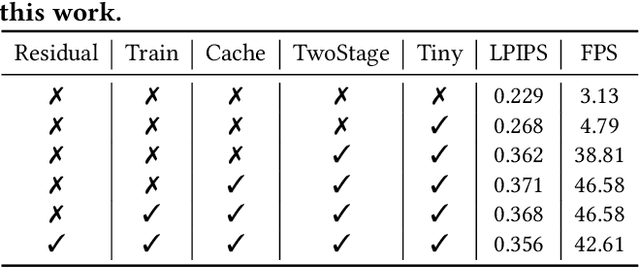
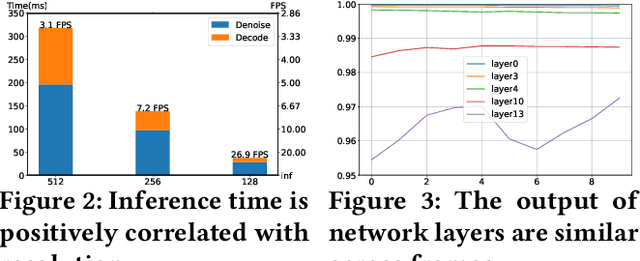

Traditional video compression algorithms exhibit significant quality degradation at extremely low bitrates. Promptus emerges as a new paradigm for video streaming, substantially cutting down the bandwidth essential for video streaming. However, Promptus is computationally intensive and can not run in real-time on mobile devices. This paper presents PromptMobile, an efficient acceleration framework tailored for on-device Promptus. Specifically, we propose (1) a two-stage efficient generation framework to reduce computational cost by 8.1x, (2) a fine-grained inter-frame caching to reduce redundant computations by 16.6\%, (3) system-level optimizations to further enhance efficiency. The evaluations demonstrate that compared with the original Promptus, PromptMobile achieves a 13.6x increase in image generation speed. Compared with other streaming methods, PromptMobile achives an average LPIPS improvement of 0.016 (compared with H.265), reducing 60\% of severely distorted frames (compared to VQGAN).
DoLLM: How Large Language Models Understanding Network Flow Data to Detect Carpet Bombing DDoS
May 13, 2024



It is an interesting question Can and How Large Language Models (LLMs) understand non-language network data, and help us detect unknown malicious flows. This paper takes Carpet Bombing as a case study and shows how to exploit LLMs' powerful capability in the networking area. Carpet Bombing is a new DDoS attack that has dramatically increased in recent years, significantly threatening network infrastructures. It targets multiple victim IPs within subnets, causing congestion on access links and disrupting network services for a vast number of users. Characterized by low-rates, multi-vectors, these attacks challenge traditional DDoS defenses. We propose DoLLM, a DDoS detection model utilizes open-source LLMs as backbone. By reorganizing non-contextual network flows into Flow-Sequences and projecting them into LLMs semantic space as token embeddings, DoLLM leverages LLMs' contextual understanding to extract flow representations in overall network context. The representations are used to improve the DDoS detection performance. We evaluate DoLLM with public datasets CIC-DDoS2019 and real NetFlow trace from Top-3 countrywide ISP. The tests have proven that DoLLM possesses strong detection capabilities. Its F1 score increased by up to 33.3% in zero-shot scenarios and by at least 20.6% in real ISP traces.
Generic Reversible Visible Watermarking Via Regularized Graph Fourier Transform Coding
May 18, 2021

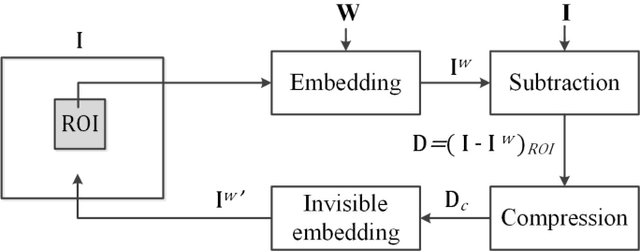
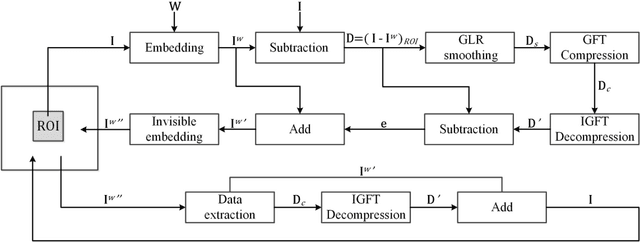
Reversible visible watermarking (RVW) is an active copyright protection mechanism. It not only transparently superimposes copyright patterns on specific positions of digital images or video frames to declare the copyright ownership information, but also completely erases the visible watermark image and thus enables restoring the original host image without any distortion. However, existing RVW algorithms mostly construct the reversible mapping mechanism for a specific visible watermarking scheme, which is not general. Hence, we propose a generic RVW framework to accommodate various visible watermarking schemes, which is based on Regularized Graph Fourier Transform (GFT) coding. In particular, we obtain a reconstruction data packet -- the compressed difference image between the watermarked image and the original host image, which is embedded into the watermarked image via any conventional reversible data hiding method to facilitate the blind recovery of the host image. The key is to achieve compact compression of the difference image for efficient embedding of the reconstruction data packet. To this end, we propose regularized GFT coding, where the difference image is smoothed via the graph Laplacian regularizer for more efficient compression and then encoded by multi-resolution GFTs in an approximately optimal manner. Experimental results show that the proposed method achieves the state-of-the-art performance with high data compression efficiency, which is applicable to both gray-scale and color images. In addition, the proposed generic framework accommodates various visible watermarking algorithms, which demonstrates strong versatility.
Co-Grounding Networks with Semantic Attention for Referring Expression Comprehension in Videos
Mar 23, 2021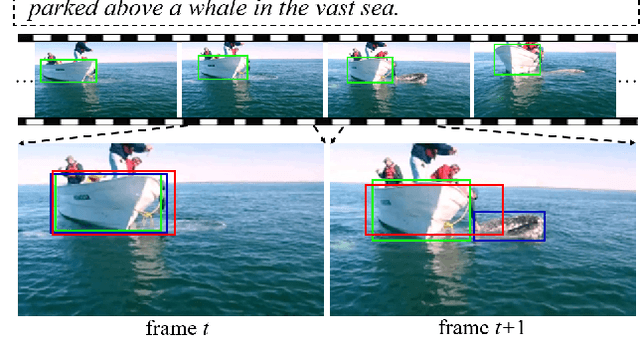
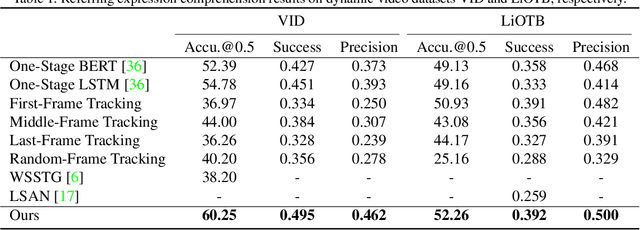
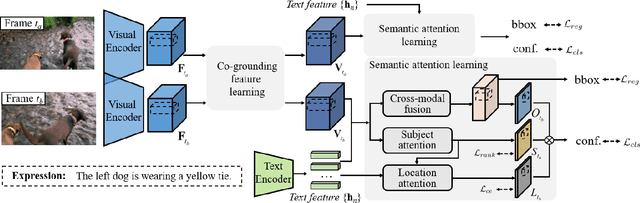
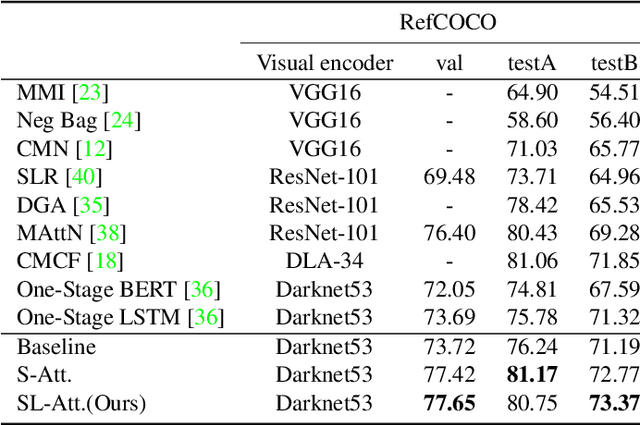
In this paper, we address the problem of referring expression comprehension in videos, which is challenging due to complex expression and scene dynamics. Unlike previous methods which solve the problem in multiple stages (i.e., tracking, proposal-based matching), we tackle the problem from a novel perspective, \textbf{co-grounding}, with an elegant one-stage framework. We enhance the single-frame grounding accuracy by semantic attention learning and improve the cross-frame grounding consistency with co-grounding feature learning. Semantic attention learning explicitly parses referring cues in different attributes to reduce the ambiguity in the complex expression. Co-grounding feature learning boosts visual feature representations by integrating temporal correlation to reduce the ambiguity caused by scene dynamics. Experiment results demonstrate the superiority of our framework on the video grounding datasets VID and LiOTB in generating accurate and stable results across frames. Our model is also applicable to referring expression comprehension in images, illustrated by the improved performance on the RefCOCO dataset. Our project is available at https://sijiesong.github.io/co-grounding.
Modality Compensation Network: Cross-Modal Adaptation for Action Recognition
Jan 31, 2020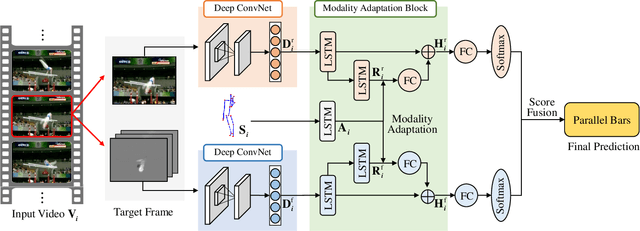
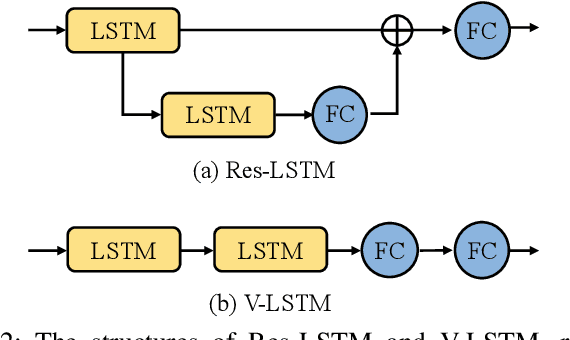
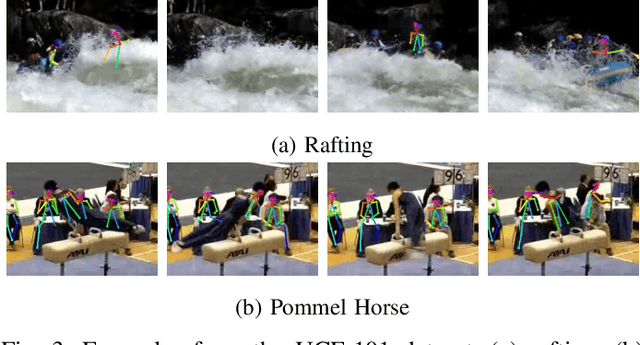
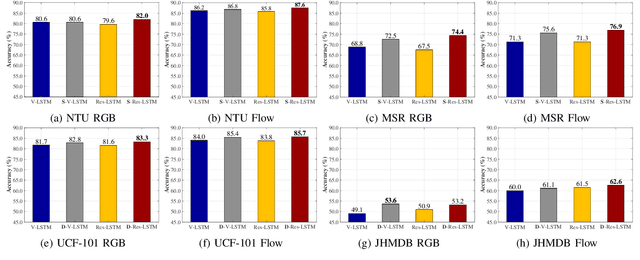
With the prevalence of RGB-D cameras, multi-modal video data have become more available for human action recognition. One main challenge for this task lies in how to effectively leverage their complementary information. In this work, we propose a Modality Compensation Network (MCN) to explore the relationships of different modalities, and boost the representations for human action recognition. We regard RGB/optical flow videos as source modalities, skeletons as auxiliary modality. Our goal is to extract more discriminative features from source modalities, with the help of auxiliary modality. Built on deep Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM) networks, our model bridges data from source and auxiliary modalities by a modality adaptation block to achieve adaptive representation learning, that the network learns to compensate for the loss of skeletons at test time and even at training time. We explore multiple adaptation schemes to narrow the distance between source and auxiliary modal distributions from different levels, according to the alignment of source and auxiliary data in training. In addition, skeletons are only required in the training phase. Our model is able to improve the recognition performance with source data when testing. Experimental results reveal that MCN outperforms state-of-the-art approaches on four widely-used action recognition benchmarks.
Deep Plastic Surgery: Robust and Controllable Image Editing with Human-Drawn Sketches
Jan 09, 2020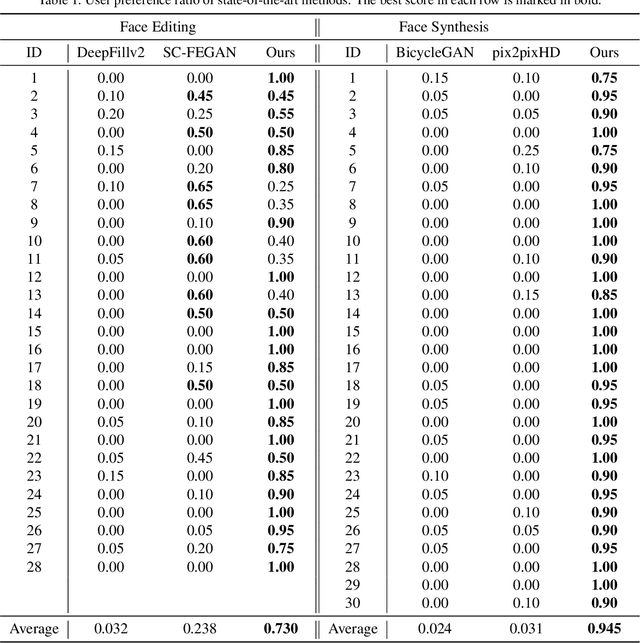

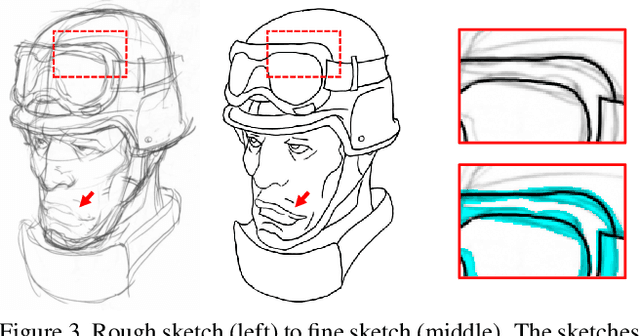

Sketch-based image editing aims to synthesize and modify photos based on the structural information provided by the human-drawn sketches. Since sketches are difficult to collect, previous methods mainly use edge maps instead of sketches to train models (referred to as edge-based models). However, sketches display great structural discrepancy with edge maps, thus failing edge-based models. Moreover, sketches often demonstrate huge variety among different users, demanding even higher generalizability and robustness for the editing model to work. In this paper, we propose Deep Plastic Surgery, a novel, robust and controllable image editing framework that allows users to interactively edit images using hand-drawn sketch inputs. We present a sketch refinement strategy, as inspired by the coarse-to-fine drawing process of the artists, which we show can help our model well adapt to casual and varied sketches without the need for real sketch training data. Our model further provides a refinement level control parameter that enables users to flexibly define how "reliable" the input sketch should be considered for the final output, balancing between sketch faithfulness and output verisimilitude (as the two goals might contradict if the input sketch is drawn poorly). To achieve the multi-level refinement, we introduce a style-based module for level conditioning, which allows adaptive feature representations for different levels in a singe network. Extensive experimental results demonstrate the superiority of our approach in improving the visual quality and user controllablity of image editing over the state-of-the-art methods.
GraphPoseGAN: 3D Hand Pose Estimation from a Monocular RGB Image via Adversarial Learning on Graphs
Dec 04, 2019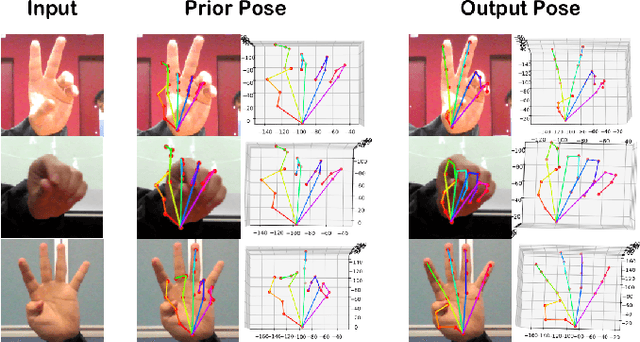
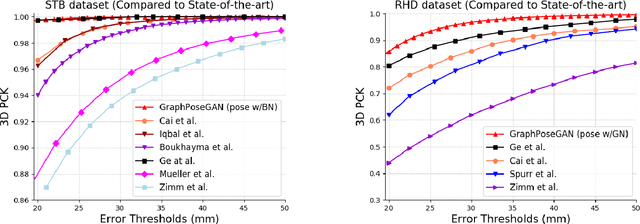
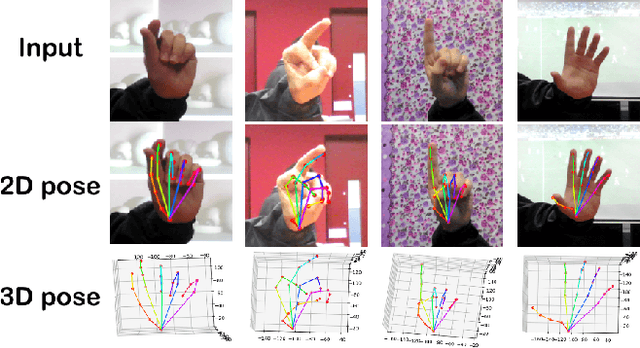
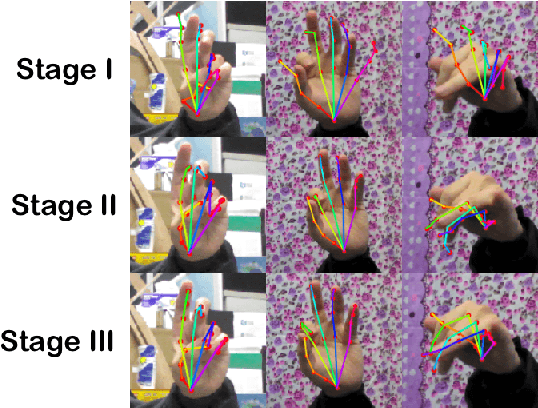
This paper addresses the problem of 3D hand pose estimation from a monocular RGB image. We are the first to propose a graph-based generative adversarial learning framework regularized by a hand model, aiming at realistic 3D hand pose estimation. Our model consists of a 3D hand pose generator and a multi-source discriminator. Taking one monocular RGB image as the input, the generator is essentially a residual graph convolution module with a parametric deformable hand model as prior for pose refinement. Further, we design a multi-source discriminator with hand poses, bones and the input image as input to capture intrinsic features, which distinguishes the predicted 3D hand pose from the ground-truth and leads to anthropomorphically valid hand poses. In addition, we propose two novel bone-constrained loss functions, which characterize the morphable structure of hand poses explicitly. Extensive experiments demonstrate that our model sets new state-of-the-art performances in 3D hand pose estimation from a monocular image on standard benchmarks.
Joint Learning of Graph Representation and Node Features in Graph Convolutional Neural Networks
Sep 11, 2019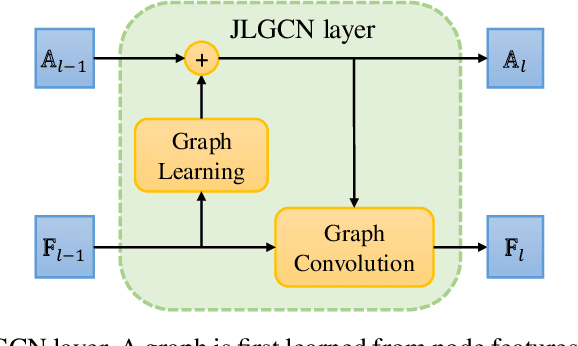
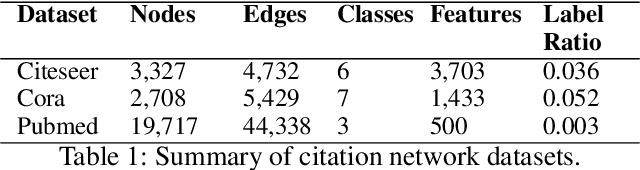
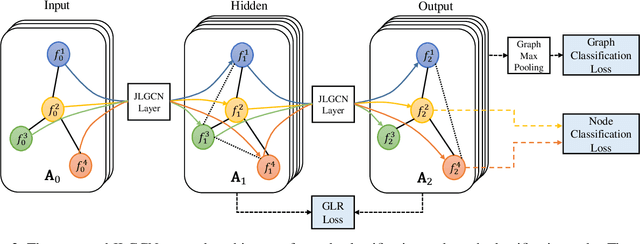
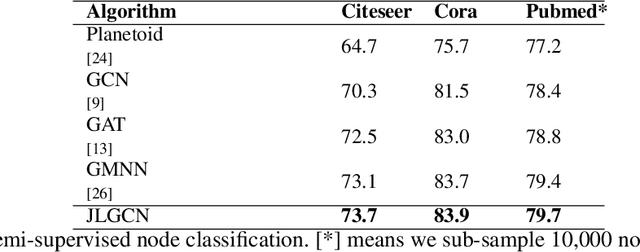
Graph Convolutional Neural Networks (GCNNs) extend classical CNNs to graph data domain, such as brain networks, social networks and 3D point clouds. It is critical to identify an appropriate graph for the subsequent graph convolution. Existing methods manually construct or learn one fixed graph for all the layers of a GCNN. In order to adapt to the underlying structure of node features in different layers, we propose dynamic learning of graphs and node features jointly in GCNNs. In particular, we cast the graph optimization problem as distance metric learning to capture pairwise similarities of features in each layer. We deploy the Mahalanobis distance metric and further decompose the metric matrix into a low-dimensional matrix, which converts graph learning to the optimization of a low-dimensional matrix for efficient implementation. Extensive experiments on point clouds and citation network datasets demonstrate the superiority of the proposed method in terms of both accuracies and robustness.