 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Thinking Enhances Missing Information Detection in Large Language Models
Dec 11, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various reasoning tasks, yet they often struggle with problems involving missing information, exhibiting issues such as incomplete responses, factual errors, and hallucinations. While forward reasoning approaches like Chain-of-Thought (CoT) and Tree-of-Thought (ToT) have shown success in structured problem-solving, they frequently fail to systematically identify and recover omitted information. In this paper, we explore the potential of reverse thinking methodologies to enhance LLMs' performance on missing information detection tasks. Drawing inspiration from recent work on backward reasoning, we propose a novel framework that guides LLMs through reverse thinking to identify necessary conditions and pinpoint missing elements. Our approach transforms the challenging task of missing information identification into a more manageable backward reasoning problem, significantly improving model accuracy. Experimental results demonstrate that our reverse thinking approach achieves substantial performance gains compared to traditional forward reasoning methods, providing a promising direction for enhancing LLMs' logical completeness and reasoning robustness.
Beyond First-Order: Training LLMs with Stochastic Conjugate Subgradients and AdamW
Jul 01, 2025Stochastic gradient-based descent (SGD), have long been central to training large language models (LLMs). However, their effectiveness is increasingly being questioned, particularly in large-scale applications where empirical evidence suggests potential performance limitations. In response, this paper proposes a stochastic conjugate subgradient method together with adaptive sampling tailored specifically for training LLMs. The method not only achieves faster convergence per iteration but also demonstrates improved scalability compared to traditional SGD techniques. It leverages sample complexity analysis to adaptively choose the sample size, employs a stochastic conjugate subgradient approach to determine search directions and utilizing an AdamW-like algorithm to adaptively adjust step sizes. This approach preserves the key advantages of first-order methods while effectively addressing the nonconvexity and non-smoothness inherent in LLMs training. Additionally, we provide a detailed analysis of the advantage of the algorithm. Experimental results show that the proposed method not only maintains, but in many cases surpasses, the scalability of traditional SGD techniques, significantly enhancing both the speed and accuracy of the optimization process.
A Comprehensive Survey on Imbalanced Data Learning
Feb 13, 2025With the expansion of data availability, machine learning (ML) has achieved remarkable breakthroughs in both academia and industry. However, imbalanced data distributions are prevalent in various types of raw data and severely hinder the performance of ML by biasing the decision-making processes. To deepen the understanding of imbalanced data and facilitate the related research and applications, this survey systematically analyzing various real-world data formats and concludes existing researches for different data formats into four distinct categories: data re-balancing, feature representation, training strategy, and ensemble learning. This structured analysis help researchers comprehensively understand the pervasive nature of imbalance across diverse data format, thereby paving a clearer path toward achieving specific research goals. we provide an overview of relevant open-source libraries, spotlight current challenges, and offer novel insights aimed at fostering future advancements in this critical area of study.
SSMLoRA: Enhancing Low-Rank Adaptation with State Space Model
Feb 07, 2025Fine-tuning is a key approach for adapting language models to specific downstream tasks, but updating all model parameters becomes impractical as model sizes increase. Parameter-Efficient Fine-Tuning (PEFT) methods, such as Low-Rank Adaptation (LoRA), address this challenge by introducing additional adaptation parameters into pre-trained weight matrices. However, LoRA's performance varies across different insertion points within the model, highlighting potential parameter inefficiency due to unnecessary insertions. To this end, we propose SSMLoRA (State Space Model Low-Rank Adaptation), an extension of LoRA that incorporates a State Space Model (SSM) to interconnect low-rank matrices. SSMLoRA ensures that performance is maintained even with sparser insertions. SSMLoRA allows the model to not only map inputs to a low-rank space for better feature extraction but also leverage the computations from the previous low-rank space. Our method achieves comparable performance to LoRA on the General Language Understanding Evaluation (GLUE) benchmark while using only half the parameters. Additionally, due to its structure, SSMLoRA shows promise in handling tasks with longer input sequences. .You can find our code here:https://github.com/yuhkalhic/SSMLoRA.
GlycanML: A Multi-Task and Multi-Structure Benchmark for Glycan Machine Learning
May 25, 2024



Glycans are basic biomolecules and perform essential functions within living organisms. The rapid increase of functional glycan data provides a good opportunity for machine learning solutions to glycan understanding. However, there still lacks a standard machine learning benchmark for glycan function prediction. In this work, we fill this blank by building a comprehensive benchmark for Glycan Machine Learning (GlycanML). The GlycanML benchmark consists of diverse types of tasks including glycan taxonomy prediction, glycan immunogenicity prediction, glycosylation type prediction, and protein-glycan interaction prediction. Glycans can be represented by both sequences and graphs in GlycanML, which enables us to extensively evaluate sequence-based models and graph neural networks (GNNs) on benchmark tasks. Furthermore, by concurrently performing eight glycan taxonomy prediction tasks, we introduce the GlycanML-MTL testbed for multi-task learning (MTL) algorithms. Experimental results show the superiority of modeling glycans with multi-relational GNNs, and suitable MTL methods can further boost model performance. We provide all datasets and source codes at https://github.com/GlycanML/GlycanML and maintain a leaderboard at https://GlycanML.github.io/project
DoLLM: How Large Language Models Understanding Network Flow Data to Detect Carpet Bombing DDoS
May 13, 2024



It is an interesting question Can and How Large Language Models (LLMs) understand non-language network data, and help us detect unknown malicious flows. This paper takes Carpet Bombing as a case study and shows how to exploit LLMs' powerful capability in the networking area. Carpet Bombing is a new DDoS attack that has dramatically increased in recent years, significantly threatening network infrastructures. It targets multiple victim IPs within subnets, causing congestion on access links and disrupting network services for a vast number of users. Characterized by low-rates, multi-vectors, these attacks challenge traditional DDoS defenses. We propose DoLLM, a DDoS detection model utilizes open-source LLMs as backbone. By reorganizing non-contextual network flows into Flow-Sequences and projecting them into LLMs semantic space as token embeddings, DoLLM leverages LLMs' contextual understanding to extract flow representations in overall network context. The representations are used to improve the DDoS detection performance. We evaluate DoLLM with public datasets CIC-DDoS2019 and real NetFlow trace from Top-3 countrywide ISP. The tests have proven that DoLLM possesses strong detection capabilities. Its F1 score increased by up to 33.3% in zero-shot scenarios and by at least 20.6% in real ISP traces.
AAT: Adapting Audio Transformer for Various Acoustics Recognition Tasks
Jan 19, 2024Recently, Transformers have been introduced into the field of acoustics recognition. They are pre-trained on large-scale datasets using methods such as supervised learning and semi-supervised learning, demonstrating robust generality--It fine-tunes easily to downstream tasks and shows more robust performance. However, the predominant fine-tuning method currently used is still full fine-tuning, which involves updating all parameters during training. This not only incurs significant memory usage and time costs but also compromises the model's generality. Other fine-tuning methods either struggle to address this issue or fail to achieve matching performance. Therefore, we conducted a comprehensive analysis of existing fine-tuning methods and proposed an efficient fine-tuning approach based on Adapter tuning, namely AAT. The core idea is to freeze the audio Transformer model and insert extra learnable Adapters, efficiently acquiring downstream task knowledge without compromising the model's original generality. Extensive experiments have shown that our method achieves performance comparable to or even superior to full fine-tuning while optimizing only 7.118% of the parameters. It also demonstrates superiority over other fine-tuning methods.
Integrated Traffic Simulation-Prediction System using Neural Networks with Application to the Los Angeles International Airport Road Network
Aug 05, 2020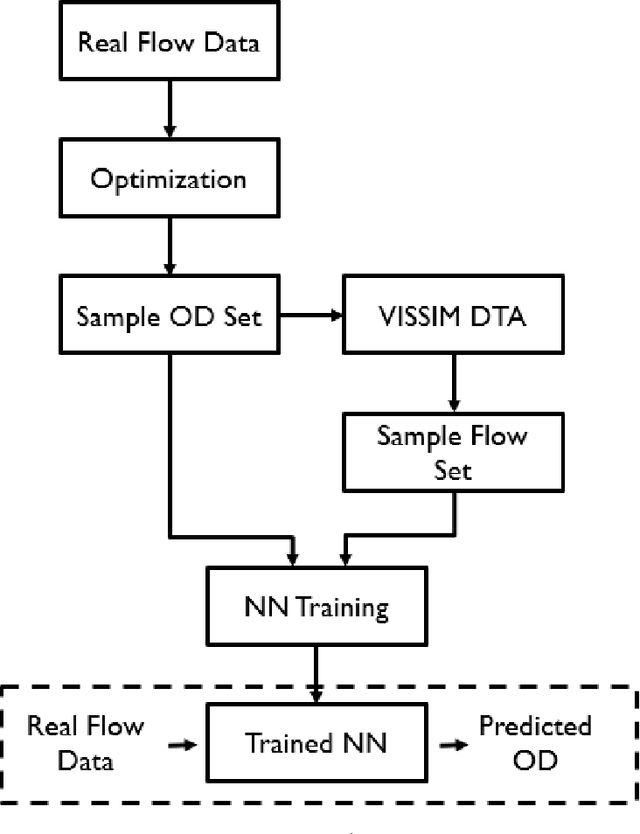
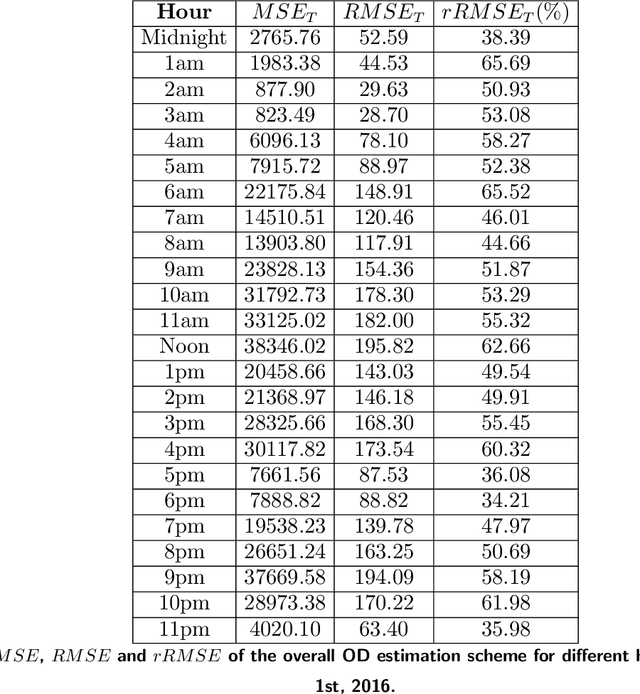
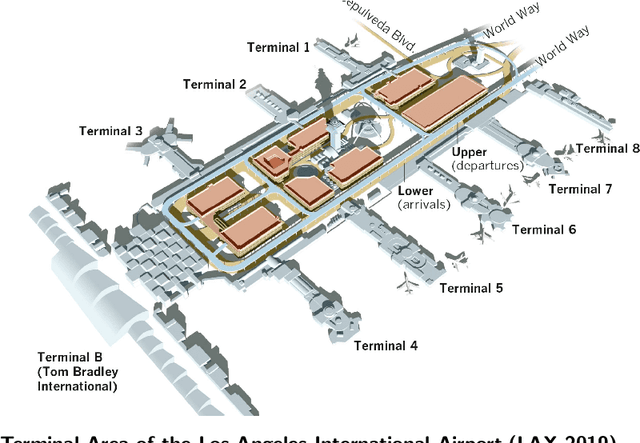
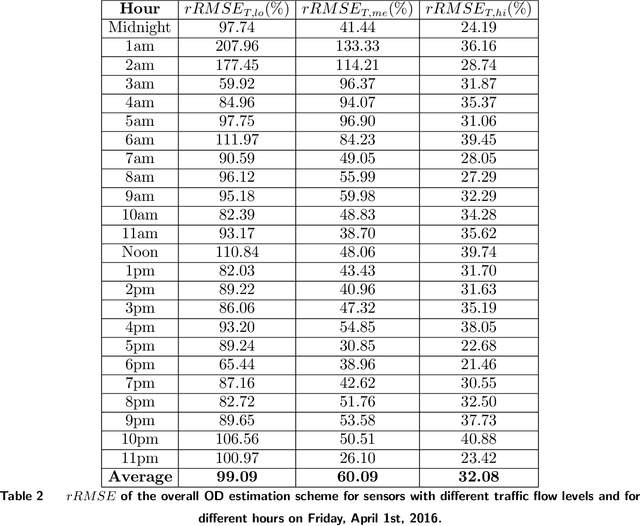
Transportation networks are highly complex and the design of efficient traffic management systems is difficult due to lack of adequate measured data and accurate predictions of the traffic states. Traffic simulation models can capture the complex dynamics of transportation networks by using limited available traffic data and can help central traffic authorities in their decision-making, if appropriate input is fed into the simulator. In this paper, we design an integrated simulation-prediction system which estimates the Origin-Destination (OD) matrix of a road network using only flow rate information and predicts the behavior of the road network in different simulation scenarios. The proposed system includes an optimization-based OD matrix generation method, a Neural Network (NN) model trained to predict OD matrices via the pattern of traffic flow and a microscopic traffic simulator with a Dynamic Traffic Assignment (DTA) scheme to predict the behavior of the transportation system. We test the proposed system on the road network of the central terminal area (CTA) of the Los Angeles International Airport (LAX), which demonstrates that the integrated traffic simulation-prediction system can be used to simulate the effects of several real world scenarios such as lane closures, curbside parking and other changes. The model is an effective tool for learning the impact and possible benefits of changes in the network and for analyzing scenarios at a very low cost without disrupting the network.