 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOSTER: First-order Dataset Distillation for Text-based Sequential Recommendation
May 29, 2026Text-based sequential recommender systems, while greatly improving recommendation accuracy by incorporating item contexts, are undeniably more expensive to train. By condensing a large dataset into a compact set of synthetic samples for model training, dataset distillation offers a promising solution. However, its adoption in text-based sequential recommendation is non-trivial given the large pool of discrete items. This challenge is further compounded by language model-based item encoding, which makes bi-level optimization commonly used in dataset distillation prohibitively expensive. To this end, we propose First-order dataset distillation for Text-based Sequential Recommendation (FOSTER), which facilitates effectiveness and efficiency via three novel components: (1) stochastic item subset sampling that replaces costly full-corpus embedding extraction at each distillation step; (2) first-order optimization with trajectory-anchored parameter reset to avoid expensive bi-level gradient computation; and (3) regularization that explicitly promotes co-occurrence between semantically similar items in the synthetic sequences. Extensive experiments on three benchmarks show that FOSTER consistently outperforms existing dataset distillation and coreset selection baselines, approximating full-dataset performance using as few as 20 synthetic interaction sequences.
GRAFT: Graph-Tokenized LLMs for Tool Planning
May 12, 2026Large language models (LLMs) are increasingly used to complete complex tasks by selecting and coordinating external tools across multiple steps. This requires aligning tool choices with subtask intent while satisfying directional execution dependencies among tools. To do this, existing methods model these dependencies as tool graphs and incorporate the graphs with LLMs through retrieval, serialization, or prompt-level injection. However, these external graph-use strategies all follow a matching paradigm, which often fails to align tool choices with the underlying subtask structure, producing semantically plausible plans that violate graph constraints. This issue is further exacerbated by error accumulation, where an early incorrect tool selection shifts the plan into an invalid graph state and causes subsequent predictions to drift away from the valid execution path. To address these challenges, we propose GRAFT, a graph-tokenized language model framework for dependency-aware tool planning. GRAFT internalizes the tool graph by mapping each tool node to a dedicated special token and learning directed tool dependencies within the representation space. It further introduces on-policy tool context distillation, training the model on its own sampled trajectories while distilling stepwise planning signals. Experiments show that GRAFT achieves state-of-the-art performance in exact sequence matching and dependency legality, supporting more reliable LLM tool planning in complex workflows.
Evolutionary Router Feature Generation for Zero-Shot Graph Anomaly Detection with Mixture-of-Experts
Feb 12, 2026Zero-shot graph anomaly detection (GAD) has attracted increasing attention recent years, yet the heterogeneity of graph structures, features, and anomaly patterns across graphs make existing single GNN methods insufficiently expressive to model diverse anomaly mechanisms. In this regard, Mixture-of-experts (MoE) architectures provide a promising paradigm by integrating diverse GNN experts with complementary inductive biases, yet their effectiveness in zero-shot GAD is severely constrained by distribution shifts, leading to two key routing challenges. First, nodes often carry vastly different semantics across graphs, and straightforwardly performing routing based on their features is prone to generating biased or suboptimal expert assignments. Second, as anomalous graphs often exhibit pronounced distributional discrepancies, existing router designs fall short in capturing domain-invariant routing principles that generalize beyond the training graphs. To address these challenges, we propose a novel MoE framework with evolutionary router feature generation (EvoFG) for zero-shot GAD. To enhance MoE routing, we propose an evolutionary feature generation scheme that iteratively constructs and selects informative structural features via an LLM-based generator and Shapley-guided evaluation. Moreover, a memory-enhanced router with an invariant learning objective is designed to capture transferable routing patterns under distribution shifts. Extensive experiments on six benchmarks show that EvoFG consistently outperforms state-of-the-art baselines, achieving strong and stable zero-shot GAD performance.
Relational Database Distillation: From Structured Tables to Condensed Graph Data
Oct 08, 2025Relational databases (RDBs) underpin the majority of global data management systems, where information is structured into multiple interdependent tables. To effectively use the knowledge within RDBs for predictive tasks, recent advances leverage graph representation learning to capture complex inter-table relations as multi-hop dependencies. Despite achieving state-of-the-art performance, these methods remain hindered by the prohibitive storage overhead and excessive training time, due to the massive scale of the database and the computational burden of intensive message passing across interconnected tables. To alleviate these concerns, we propose and study the problem of Relational Database Distillation (RDD). Specifically, we aim to distill large-scale RDBs into compact heterogeneous graphs while retaining the predictive power (i.e., utility) required for training graph-based models. Multi-modal column information is preserved through node features, and primary-foreign key relations are encoded via heterogeneous edges, thereby maintaining both data fidelity and relational structure. To ensure adaptability across diverse downstream tasks without engaging the traditional, inefficient bi-level distillation framework, we further design a kernel ridge regression-guided objective with pseudo-labels, which produces quality features for the distilled graph. Extensive experiments on multiple real-world RDBs demonstrate that our solution substantially reduces the data size while maintaining competitive performance on classification and regression tasks, creating an effective pathway for scalable learning with RDBs.
A Hierarchical Probabilistic Framework for Incremental Knowledge Tracing in Classroom Settings
Jun 11, 2025Knowledge tracing (KT) aims to estimate a student's evolving knowledge state and predict their performance on new exercises based on performance history. Many realistic classroom settings for KT are typically low-resource in data and require online updates as students' exercise history grows, which creates significant challenges for existing KT approaches. To restore strong performance under low-resource conditions, we revisit the hierarchical knowledge concept (KC) information, which is typically available in many classroom settings and can provide strong prior when data are sparse. We therefore propose Knowledge-Tree-based Knowledge Tracing (KT$^2$), a probabilistic KT framework that models student understanding over a tree-structured hierarchy of knowledge concepts using a Hidden Markov Tree Model. KT$^2$ estimates student mastery via an EM algorithm and supports personalized prediction through an incremental update mechanism as new responses arrive. Our experiments show that KT$^2$ consistently outperforms strong baselines in realistic online, low-resource settings.
A Comprehensive Survey on Imbalanced Data Learning
Feb 13, 2025With the expansion of data availability, machine learning (ML) has achieved remarkable breakthroughs in both academia and industry. However, imbalanced data distributions are prevalent in various types of raw data and severely hinder the performance of ML by biasing the decision-making processes. To deepen the understanding of imbalanced data and facilitate the related research and applications, this survey systematically analyzing various real-world data formats and concludes existing researches for different data formats into four distinct categories: data re-balancing, feature representation, training strategy, and ensemble learning. This structured analysis help researchers comprehensively understand the pervasive nature of imbalance across diverse data format, thereby paving a clearer path toward achieving specific research goals. we provide an overview of relevant open-source libraries, spotlight current challenges, and offer novel insights aimed at fostering future advancements in this critical area of study.
Norm Augmented Graph AutoEncoders for Link Prediction
Feb 09, 2025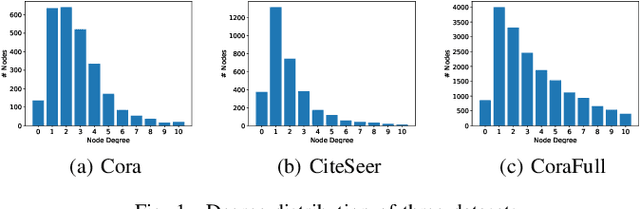
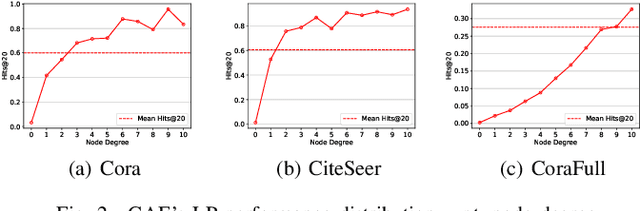
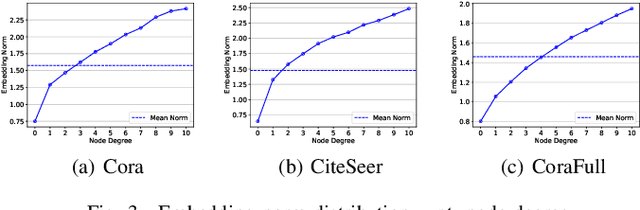
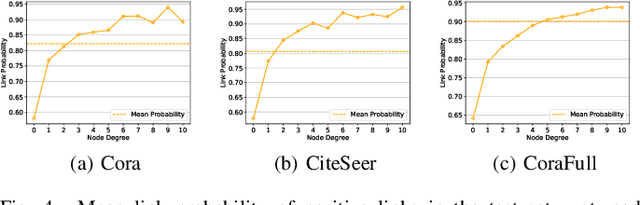
Link Prediction (LP) is a crucial problem in graph-structured data. Graph Neural Networks (GNNs) have gained prominence in LP, with Graph AutoEncoders (GAEs) being a notable representation. However, our empirical findings reveal that GAEs' LP performance suffers heavily from the long-tailed node degree distribution, i.e., low-degree nodes tend to exhibit inferior LP performance compared to high-degree nodes. \emph{What causes this degree-related bias, and how can it be mitigated?} In this study, we demonstrate that the norm of node embeddings learned by GAEs exhibits variation among nodes with different degrees, underscoring its central significance in influencing the final performance of LP. Specifically, embeddings with larger norms tend to guide the decoder towards predicting higher scores for positive links and lower scores for negative links, thereby contributing to superior performance. This observation motivates us to improve GAEs' LP performance on low-degree nodes by increasing their embedding norms, which can be implemented simply yet effectively by introducing additional self-loops into the training objective for low-degree nodes. This norm augmentation strategy can be seamlessly integrated into existing GAE methods with light computational cost. Extensive experiments on various datasets and GAE methods show the superior performance of norm-augmented GAEs.
FedVCK: Non-IID Robust and Communication-Efficient Federated Learning via Valuable Condensed Knowledge for Medical Image Analysis
Dec 24, 2024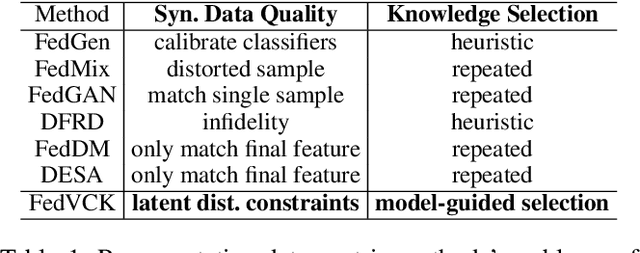
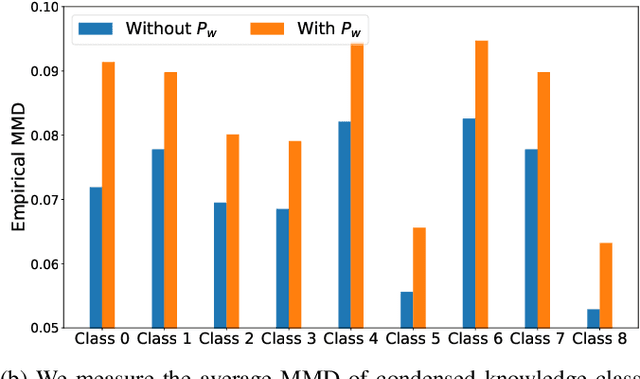
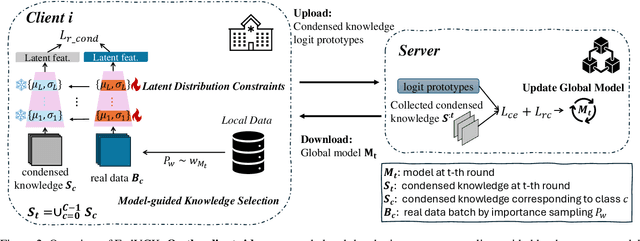
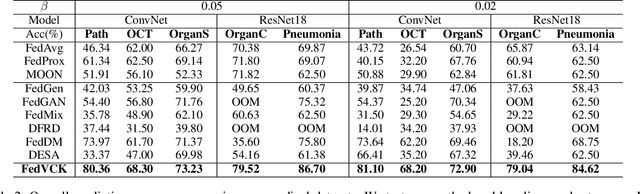
Federated learning has become a promising solution for collaboration among medical institutions. However, data owned by each institution would be highly heterogeneous and the distribution is always non-independent and identical distribution (non-IID), resulting in client drift and unsatisfactory performance. Despite existing federated learning methods attempting to solve the non-IID problems, they still show marginal advantages but rely on frequent communication which would incur high costs and privacy concerns. In this paper, we propose a novel federated learning method: \textbf{Fed}erated learning via \textbf{V}aluable \textbf{C}ondensed \textbf{K}nowledge (FedVCK). We enhance the quality of condensed knowledge and select the most necessary knowledge guided by models, to tackle the non-IID problem within limited communication budgets effectively. Specifically, on the client side, we condense the knowledge of each client into a small dataset and further enhance the condensation procedure with latent distribution constraints, facilitating the effective capture of high-quality knowledge. During each round, we specifically target and condense knowledge that has not been assimilated by the current model, thereby preventing unnecessary repetition of homogeneous knowledge and minimizing the frequency of communications required. On the server side, we propose relational supervised contrastive learning to provide more supervision signals to aid the global model updating. Comprehensive experiments across various medical tasks show that FedVCK can outperform state-of-the-art methods, demonstrating that it's non-IID robust and communication-efficient.
Training-free Heterogeneous Graph Condensation via Data Selection
Dec 20, 2024Efficient training of large-scale heterogeneous graphs is of paramount importance in real-world applications. However, existing approaches typically explore simplified models to mitigate resource and time overhead, neglecting the crucial aspect of simplifying large-scale heterogeneous graphs from the data-centric perspective. Addressing this gap, HGCond introduces graph condensation (GC) in heterogeneous graphs and generates a small condensed graph for efficient model training. Despite its efficacy in graph generation, HGCond encounters two significant limitations. The first is low effectiveness, HGCond excessively relies on the simplest relay model for the condensation procedure, which restricts the ability to exert powerful Heterogeneous Graph Neural Networks (HGNNs) with flexible condensation ratio and limits the generalization ability. The second is low efficiency, HGCond follows the existing GC methods designed for homogeneous graphs and leverages the sophisticated optimization paradigm, resulting in a time-consuming condensing procedure. In light of these challenges, we present the first Training \underline{Free} Heterogeneous Graph Condensation method, termed FreeHGC, facilitating both efficient and high-quality generation of heterogeneous condensed graphs. Specifically, we reformulate the heterogeneous graph condensation problem as a data selection issue, offering a new perspective for assessing and condensing representative nodes and edges in the heterogeneous graphs. By leveraging rich meta-paths, we introduce a new, high-quality heterogeneous data selection criterion to select target-type nodes. Furthermore, two training-free condensation strategies for heterogeneous graphs are designed to condense and synthesize other-types nodes effectively.
Contrastive Graph Condensation: Advancing Data Versatility through Self-Supervised Learning
Nov 26, 2024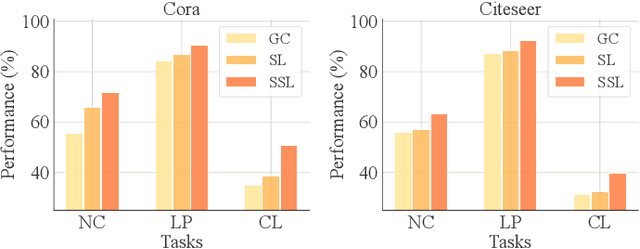
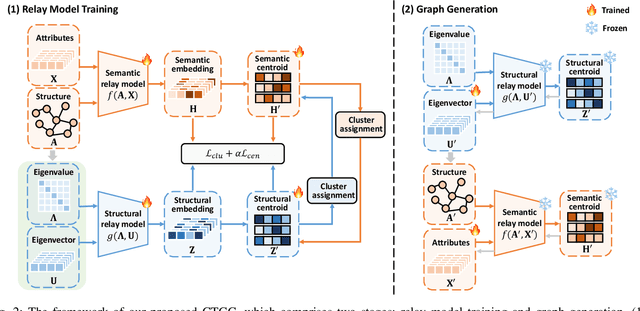
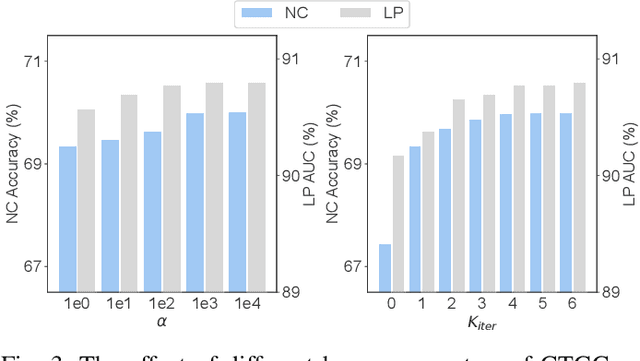
With the increasing computation of training graph neural networks (GNNs) on large-scale graphs, graph condensation (GC) has emerged as a promising solution to synthesize a compact, substitute graph of the large-scale original graph for efficient GNN training. However, existing GC methods predominantly employ classification as the surrogate task for optimization, thus excessively relying on node labels and constraining their utility in label-sparsity scenarios. More critically, this surrogate task tends to overfit class-specific information within the condensed graph, consequently restricting the generalization capabilities of GC for other downstream tasks. To address these challenges, we introduce Contrastive Graph Condensation (CTGC), which adopts a self-supervised surrogate task to extract critical, causal information from the original graph and enhance the cross-task generalizability of the condensed graph. Specifically, CTGC employs a dual-branch framework to disentangle the generation of the node attributes and graph structures, where a dedicated structural branch is designed to explicitly encode geometric information through nodes' positional embeddings. By implementing an alternating optimization scheme with contrastive loss terms, CTGC promotes the mutual enhancement of both branches and facilitates high-quality graph generation through the model inversion technique. Extensive experiments demonstrate that CTGC excels in handling various downstream tasks with a limited number of labels, consistently outperforming state-of-the-art GC methods.