 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Quant: Granular Semantic and Generative Structural Quantization for Knowledge Graph Completion
Apr 23, 2026Large Language Models (LLMs) have shown immense potential in Knowledge Graph Completion (KGC), yet bridging the modality gap between continuous graph embeddings and discrete LLM tokens remains a critical challenge. While recent quantization-based approaches attempt to align these modalities, they typically treat quantization as flat numerical compression, resulting in semantically entangled codes that fail to mirror the hierarchical nature of human reasoning. In this paper, we propose GS-Quant, a novel framework that generates semantically coherent and structurally stratified discrete codes for KG entities. Unlike prior methods, GS-Quant is grounded in the insight that entity representations should follow a linguistic coarse-to-fine logic. We introduce a Granular Semantic Enhancement module that injects hierarchical knowledge into the codebook, ensuring that earlier codes capture global semantic categories while later codes refine specific attributes. Furthermore, a Generative Structural Reconstruction module imposes causal dependencies on the code sequence, transforming independent discrete units into structured semantic descriptors. By expanding the LLM vocabulary with these learned codes, we enable the model to reason over graph structures isomorphically to natural language generation. Experimental results demonstrate that GS-Quant significantly outperforms existing text-based and embedding-based baselines. Our code is publicly available at https://github.com/mikumifa/GS-Quant.
FedRio: Personalized Federated Social Bot Detection via Cooperative Reinforced Contrastive Adversarial Distillation
Apr 12, 2026Social bot detection is critical to the stability and security of online social platforms. However, current state-of-the-art bot detection models are largely developed in isolation, overlooking the benefits of leveraging shared detection patterns across platforms to improve performance and promptly identify emerging bot variants. The heterogeneity of data distributions and model architectures further complicates the design of an effective cross-platform and cross-model detection framework. To address these challenges, we propose FedRio (Personalized Federated Social Bot Detection with Cooperative Reinforced Contrastive Adversarial Distillation framework. We first introduce an adaptive message-passing module as the graph neural network backbone for each client. To facilitate efficient knowledge sharing of global data distributions, we design a federated knowledge extraction mechanism based on generative adversarial networks. Additionally, we employ a multi-stage adversarial contrastive learning strategy to enforce feature space consistency among clients and reduce divergence between local and global models. Finally, we adopt adaptive server-side parameter aggregation and reinforcement learning-based client-side parameter control to better accommodate data heterogeneity in heterogeneous federated settings. Extensive experiments on two real-world social bot detection benchmarks demonstrate that FedRio consistently outperforms state-of-the-art federated learning baselines in detection accuracy, communication efficiency, and feature space consistency, while remaining competitive with published centralized results under substantially stronger privacy constraints.
Beyond the Academic Monoculture: A Unified Framework and Industrial Perspective for Attributed Graph Clustering
Mar 21, 2026Attributed Graph Clustering (AGC) is a fundamental unsupervised task that partitions nodes into cohesive groups by jointly modeling structural topology and node attributes. While the advent of graph neural networks and self-supervised learning has catalyzed a proliferation of AGC methodologies, a widening chasm persists between academic benchmark performance and the stringent demands of real-world industrial deployment. To bridge this gap, this survey provides a comprehensive, industrially grounded review of AGC from three complementary perspectives. First, we introduce the Encode-Cluster-Optimize taxonomic framework, which decomposes the diverse algorithmic landscape into three orthogonal, composable modules: representation encoding, cluster projection, and optimization strategy. This unified paradigm enables principled architectural comparisons and inspires novel methodological combinations. Second, we critically examine prevailing evaluation protocols to expose the field's academic monoculture: a pervasive over-reliance on small, homophilous citation networks, the inadequacy of supervised-only metrics for an inherently unsupervised task, and the chronic neglect of computational scalability. In response, we advocate for a holistic evaluation standard that integrates supervised semantic alignment, unsupervised structural integrity, and rigorous efficiency profiling. Third, we explicitly confront the practical realities of industrial deployment. By analyzing operational constraints such as massive scale, severe heterophily, and tabular feature noise alongside extensive empirical evidence from our companion benchmark, we outline actionable engineering strategies. Furthermore, we chart a clear roadmap for future research, prioritizing heterophily-robust encoders, scalable joint optimization, and unsupervised model selection criteria to meet production-grade requirements.
Mitigating Homophily Disparity in Graph Anomaly Detection: A Scalable and Adaptive Approach
Mar 09, 2026Graph anomaly detection (GAD) aims to identify nodes that deviate from normal patterns in structure or features. While recent GNN-based approaches have advanced this task, they struggle with two major challenges: 1) homophily disparity, where nodes exhibit varying homophily at both class and node levels; and 2) limited scalability, as many methods rely on costly whole-graph operations. To address them, we propose SAGAD, a Scalable and Adaptive framework for GAD. SAGAD precomputes multi-hop embeddings and applies reparameterized Chebyshev filters to extract low- and high-frequency information, enabling efficient training and capturing both homophilic and heterophilic patterns. To mitigate node-level homophily disparity, we introduce an Anomaly Context-Aware Adaptive Fusion, which adaptively fuses low- and high-pass embeddings using fusion coefficients conditioned on Rayleigh Quotient-guided anomalous subgraph structures for each node. To alleviate class-level disparity, we design a Frequency Preference Guidance Loss, which encourages anomalies to preserve more high-frequency information than normal nodes. SAGAD supports mini-batch training, achieves linear time and space complexity, and drastically reduces memory usage on large-scale graphs. Theoretically, SAGAD ensures asymptotic linear separability between normal and abnormal nodes under mild conditions. Extensive experiments on 10 benchmarks confirm SAGAD's superior accuracy and scalability over state-of-the-art methods.
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning
Mar 09, 2026Hierarchical knowledge structures are ubiquitous across real-world domains and play a vital role in organizing information from coarse to fine semantic levels. While such structures have been widely used in taxonomy systems, biomedical ontologies, and retrieval-augmented generation, their potential remains underexplored in the context of Text-Rich Networks (TRNs), where each node contains rich textual content and edges encode semantic relationships. Existing methods for learning on TRNs often focus on flat semantic modeling, overlooking the inherent hierarchical semantics embedded in textual documents. To this end, we propose TIER (Hierarchical \textbf{T}axonomy-\textbf{I}nformed R\textbf{E}presentation Learning on Text-\textbf{R}ich Networks), which first constructs an implicit hierarchical taxonomy and then integrates it into the learned node representations. Specifically, TIER employs similarity-guided contrastive learning to build a clustering-friendly embedding space, upon which it performs hierarchical K-Means followed by LLM-powered clustering refinement to enable semantically coherent taxonomy construction. Leveraging the resulting taxonomy, TIER introduces a cophenetic correlation coefficient-based regularization loss to align the learned embeddings with the hierarchical structure. By learning representations that respect both fine-grained and coarse-grained semantics, TIER enables more interpretable and structured modeling of real-world TRNs. We demonstrate that our approach significantly outperforms existing methods on multiple datasets across diverse domains, highlighting the importance of hierarchical knowledge learning for TRNs.
SDFed: Bridging Local Global Discrepancy via Subspace Refinement and Divergence Control in Federated Prompt Learning
Feb 09, 2026Vision-language pretrained models offer strong transferable representations, yet adapting them in privacy-sensitive multi-party settings is challenging due to the high communication cost of federated optimization and the limited local data on clients. Federated prompt learning mitigates this issue by keeping the VLPM backbone frozen and collaboratively training lightweight prompt parameters. However, existing approaches typically enforce a unified prompt structure and length across clients, which is inadequate under practical client heterogeneity in both data distributions and system resources, and may further introduce conflicts between globally shared and locally optimal knowledge. To address these challenges, we propose \textbf{SDFed}, a heterogeneous federated prompt learning framework that bridges Local-Global Discrepancy via Subspace Refinement and Divergence Control. SDFed maintains a fixed-length global prompt for efficient aggregation while allowing each client to learn a variable-length local prompt to better match its data characteristics and capacity. To mitigate local-global conflicts and facilitate effective knowledge transfer, SDFed introduces a subspace refinement method for local prompts and an information retention and divergence control strategy that preserves key local information while maintaining appropriate separability between global and local representations. Extensive experiments on several datasets demonstrate that SDFed consistently improves performance and robustness in heterogeneous federated settings.
Bridging Academia and Industry: A Comprehensive Benchmark for Attributed Graph Clustering
Feb 09, 2026Attributed Graph Clustering (AGC) is a fundamental unsupervised task that integrates structural topology and node attributes to uncover latent patterns in graph-structured data. Despite its significance in industrial applications such as fraud detection and user segmentation, a significant chasm persists between academic research and real-world deployment. Current evaluation protocols suffer from the small-scale, high-homophily citation datasets, non-scalable full-batch training paradigms, and a reliance on supervised metrics that fail to reflect performance in label-scarce environments. To bridge these gaps, we present PyAGC, a comprehensive, production-ready benchmark and library designed to stress-test AGC methods across diverse scales and structural properties. We unify existing methodologies into a modular Encode-Cluster-Optimize framework and, for the first time, provide memory-efficient, mini-batch implementations for a wide array of state-of-the-art AGC algorithms. Our benchmark curates 12 diverse datasets, ranging from 2.7K to 111M nodes, specifically incorporating industrial graphs with complex tabular features and low homophily. Furthermore, we advocate for a holistic evaluation protocol that mandates unsupervised structural metrics and efficiency profiling alongside traditional supervised metrics. Battle-tested in high-stakes industrial workflows at Ant Group, this benchmark offers the community a robust, reproducible, and scalable platform to advance AGC research towards realistic deployment. The code and resources are publicly available via GitHub (https://github.com/Cloudy1225/PyAGC), PyPI (https://pypi.org/project/pyagc), and Documentation (https://pyagc.readthedocs.io).
Tabular Foundation Models are Strong Graph Anomaly Detectors
Jan 24, 2026Graph anomaly detection (GAD), which aims to identify abnormal nodes that deviate from the majority, has become increasingly important in high-stakes Web domains. However, existing GAD methods follow a "one model per dataset" paradigm, leading to high computational costs, substantial data demands, and poor generalization when transferred to new datasets. This calls for a foundation model that enables a "one-for-all" GAD solution capable of detecting anomalies across diverse graphs without retraining. Yet, achieving this is challenging due to the large structural and feature heterogeneity across domains. In this paper, we propose TFM4GAD, a simple yet effective framework that adapts tabular foundation models (TFMs) for graph anomaly detection. Our key insight is that the core challenges of foundation GAD, handling heterogeneous features, generalizing across domains, and operating with scarce labels, are the exact problems that modern TFMs are designed to solve via synthetic pre-training and powerful in-context learning. The primary challenge thus becomes structural: TFMs are agnostic to graph topology. TFM4GAD bridges this gap by "flattening" the graph, constructing an augmented feature table that enriches raw node features with Laplacian embeddings, local and global structural characteristics, and anomaly-sensitive neighborhood aggregations. This augmented table is processed by a TFM in a fully in-context regime. Extensive experiments on multiple datasets with various TFM backbones reveal that TFM4GAD surprisingly achieves significant performance gains over specialized GAD models trained from scratch. Our work offers a new perspective and a practical paradigm for leveraging TFMs as powerful, generalist graph anomaly detectors.
A Pre-Training and Adaptive Fine-Tuning Framework for Graph Anomaly Detection
Apr 19, 2025Graph anomaly detection (GAD) has garnered increasing attention in recent years, yet it remains challenging due to the scarcity of abnormal nodes and the high cost of label annotations. Graph pre-training, the two-stage learning paradigm, has emerged as an effective approach for label-efficient learning, largely benefiting from expressive neighborhood aggregation under the assumption of strong homophily. However, in GAD, anomalies typically exhibit high local heterophily, while normal nodes retain strong homophily, resulting in a complex homophily-heterophily mixture. To understand the impact of this mixed pattern on graph pre-training, we analyze it through the lens of spectral filtering and reveal that relying solely on a global low-pass filter is insufficient for GAD. We further provide a theoretical justification for the necessity of selectively applying appropriate filters to individual nodes. Building upon this insight, we propose PAF, a Pre-Training and Adaptive Fine-tuning framework specifically designed for GAD. In particular, we introduce joint training with low- and high-pass filters in the pre-training phase to capture the full spectrum of frequency information in node features. During fine-tuning, we devise a gated fusion network that adaptively combines node representations generated by both filters. Extensive experiments across ten benchmark datasets consistently demonstrate the effectiveness of PAF.
Learning Accurate, Efficient, and Interpretable MLPs on Multiplex Graphs via Node-wise Multi-View Ensemble Distillation
Feb 09, 2025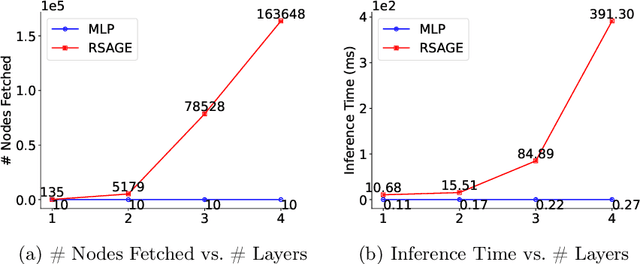
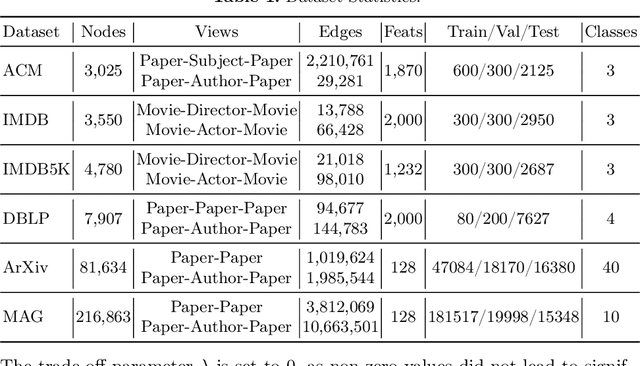
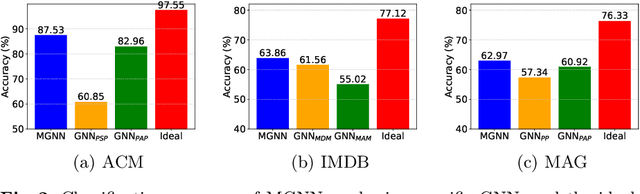
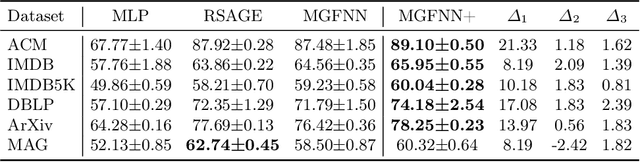
Multiplex graphs, with multiple edge types (graph views) among common nodes, provide richer structural semantics and better modeling capabilities. Multiplex Graph Neural Networks (MGNNs), typically comprising view-specific GNNs and a multi-view integration layer, have achieved advanced performance in various downstream tasks. However, their reliance on neighborhood aggregation poses challenges for deployment in latency-sensitive applications. Motivated by recent GNN-to-MLP knowledge distillation frameworks, we propose Multiplex Graph-Free Neural Networks (MGFNN and MGFNN+) to combine MGNNs' superior performance and MLPs' efficient inference via knowledge distillation. MGFNN directly trains student MLPs with node features as input and soft labels from teacher MGNNs as targets. MGFNN+ further employs a low-rank approximation-based reparameterization to learn node-wise coefficients, enabling adaptive knowledge ensemble from each view-specific GNN. This node-wise multi-view ensemble distillation strategy allows student MLPs to learn more informative multiplex semantic knowledge for different nodes. Experiments show that MGFNNs achieve average accuracy improvements of about 10% over vanilla MLPs and perform comparably or even better to teacher MGNNs (accurate); MGFNNs achieve a 35.40$\times$-89.14$\times$ speedup in inference over MGNNs (efficient); MGFNN+ adaptively assigns different coefficients for multi-view ensemble distillation regarding different nodes (interpretable).