 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Quant: Granular Semantic and Generative Structural Quantization for Knowledge Graph Completion
Apr 23, 2026Large Language Models (LLMs) have shown immense potential in Knowledge Graph Completion (KGC), yet bridging the modality gap between continuous graph embeddings and discrete LLM tokens remains a critical challenge. While recent quantization-based approaches attempt to align these modalities, they typically treat quantization as flat numerical compression, resulting in semantically entangled codes that fail to mirror the hierarchical nature of human reasoning. In this paper, we propose GS-Quant, a novel framework that generates semantically coherent and structurally stratified discrete codes for KG entities. Unlike prior methods, GS-Quant is grounded in the insight that entity representations should follow a linguistic coarse-to-fine logic. We introduce a Granular Semantic Enhancement module that injects hierarchical knowledge into the codebook, ensuring that earlier codes capture global semantic categories while later codes refine specific attributes. Furthermore, a Generative Structural Reconstruction module imposes causal dependencies on the code sequence, transforming independent discrete units into structured semantic descriptors. By expanding the LLM vocabulary with these learned codes, we enable the model to reason over graph structures isomorphically to natural language generation. Experimental results demonstrate that GS-Quant significantly outperforms existing text-based and embedding-based baselines. Our code is publicly available at https://github.com/mikumifa/GS-Quant.
Beyond the Academic Monoculture: A Unified Framework and Industrial Perspective for Attributed Graph Clustering
Mar 21, 2026Attributed Graph Clustering (AGC) is a fundamental unsupervised task that partitions nodes into cohesive groups by jointly modeling structural topology and node attributes. While the advent of graph neural networks and self-supervised learning has catalyzed a proliferation of AGC methodologies, a widening chasm persists between academic benchmark performance and the stringent demands of real-world industrial deployment. To bridge this gap, this survey provides a comprehensive, industrially grounded review of AGC from three complementary perspectives. First, we introduce the Encode-Cluster-Optimize taxonomic framework, which decomposes the diverse algorithmic landscape into three orthogonal, composable modules: representation encoding, cluster projection, and optimization strategy. This unified paradigm enables principled architectural comparisons and inspires novel methodological combinations. Second, we critically examine prevailing evaluation protocols to expose the field's academic monoculture: a pervasive over-reliance on small, homophilous citation networks, the inadequacy of supervised-only metrics for an inherently unsupervised task, and the chronic neglect of computational scalability. In response, we advocate for a holistic evaluation standard that integrates supervised semantic alignment, unsupervised structural integrity, and rigorous efficiency profiling. Third, we explicitly confront the practical realities of industrial deployment. By analyzing operational constraints such as massive scale, severe heterophily, and tabular feature noise alongside extensive empirical evidence from our companion benchmark, we outline actionable engineering strategies. Furthermore, we chart a clear roadmap for future research, prioritizing heterophily-robust encoders, scalable joint optimization, and unsupervised model selection criteria to meet production-grade requirements.
Mitigating Homophily Disparity in Graph Anomaly Detection: A Scalable and Adaptive Approach
Mar 09, 2026Graph anomaly detection (GAD) aims to identify nodes that deviate from normal patterns in structure or features. While recent GNN-based approaches have advanced this task, they struggle with two major challenges: 1) homophily disparity, where nodes exhibit varying homophily at both class and node levels; and 2) limited scalability, as many methods rely on costly whole-graph operations. To address them, we propose SAGAD, a Scalable and Adaptive framework for GAD. SAGAD precomputes multi-hop embeddings and applies reparameterized Chebyshev filters to extract low- and high-frequency information, enabling efficient training and capturing both homophilic and heterophilic patterns. To mitigate node-level homophily disparity, we introduce an Anomaly Context-Aware Adaptive Fusion, which adaptively fuses low- and high-pass embeddings using fusion coefficients conditioned on Rayleigh Quotient-guided anomalous subgraph structures for each node. To alleviate class-level disparity, we design a Frequency Preference Guidance Loss, which encourages anomalies to preserve more high-frequency information than normal nodes. SAGAD supports mini-batch training, achieves linear time and space complexity, and drastically reduces memory usage on large-scale graphs. Theoretically, SAGAD ensures asymptotic linear separability between normal and abnormal nodes under mild conditions. Extensive experiments on 10 benchmarks confirm SAGAD's superior accuracy and scalability over state-of-the-art methods.
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning
Mar 09, 2026Hierarchical knowledge structures are ubiquitous across real-world domains and play a vital role in organizing information from coarse to fine semantic levels. While such structures have been widely used in taxonomy systems, biomedical ontologies, and retrieval-augmented generation, their potential remains underexplored in the context of Text-Rich Networks (TRNs), where each node contains rich textual content and edges encode semantic relationships. Existing methods for learning on TRNs often focus on flat semantic modeling, overlooking the inherent hierarchical semantics embedded in textual documents. To this end, we propose TIER (Hierarchical \textbf{T}axonomy-\textbf{I}nformed R\textbf{E}presentation Learning on Text-\textbf{R}ich Networks), which first constructs an implicit hierarchical taxonomy and then integrates it into the learned node representations. Specifically, TIER employs similarity-guided contrastive learning to build a clustering-friendly embedding space, upon which it performs hierarchical K-Means followed by LLM-powered clustering refinement to enable semantically coherent taxonomy construction. Leveraging the resulting taxonomy, TIER introduces a cophenetic correlation coefficient-based regularization loss to align the learned embeddings with the hierarchical structure. By learning representations that respect both fine-grained and coarse-grained semantics, TIER enables more interpretable and structured modeling of real-world TRNs. We demonstrate that our approach significantly outperforms existing methods on multiple datasets across diverse domains, highlighting the importance of hierarchical knowledge learning for TRNs.
Bridging Academia and Industry: A Comprehensive Benchmark for Attributed Graph Clustering
Feb 09, 2026Attributed Graph Clustering (AGC) is a fundamental unsupervised task that integrates structural topology and node attributes to uncover latent patterns in graph-structured data. Despite its significance in industrial applications such as fraud detection and user segmentation, a significant chasm persists between academic research and real-world deployment. Current evaluation protocols suffer from the small-scale, high-homophily citation datasets, non-scalable full-batch training paradigms, and a reliance on supervised metrics that fail to reflect performance in label-scarce environments. To bridge these gaps, we present PyAGC, a comprehensive, production-ready benchmark and library designed to stress-test AGC methods across diverse scales and structural properties. We unify existing methodologies into a modular Encode-Cluster-Optimize framework and, for the first time, provide memory-efficient, mini-batch implementations for a wide array of state-of-the-art AGC algorithms. Our benchmark curates 12 diverse datasets, ranging from 2.7K to 111M nodes, specifically incorporating industrial graphs with complex tabular features and low homophily. Furthermore, we advocate for a holistic evaluation protocol that mandates unsupervised structural metrics and efficiency profiling alongside traditional supervised metrics. Battle-tested in high-stakes industrial workflows at Ant Group, this benchmark offers the community a robust, reproducible, and scalable platform to advance AGC research towards realistic deployment. The code and resources are publicly available via GitHub (https://github.com/Cloudy1225/PyAGC), PyPI (https://pypi.org/project/pyagc), and Documentation (https://pyagc.readthedocs.io).
Multi-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
Learning Accurate, Efficient, and Interpretable MLPs on Multiplex Graphs via Node-wise Multi-View Ensemble Distillation
Feb 09, 2025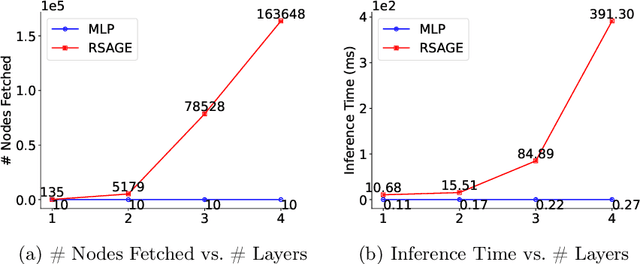
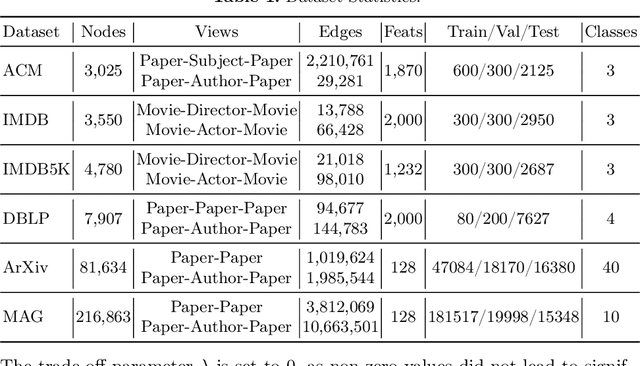
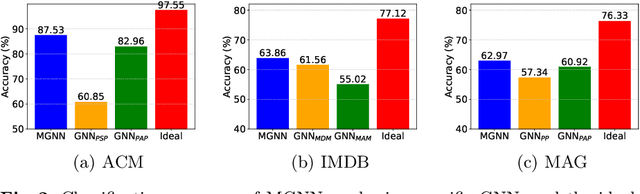
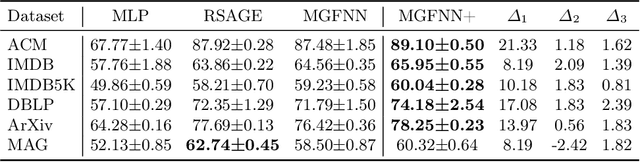
Multiplex graphs, with multiple edge types (graph views) among common nodes, provide richer structural semantics and better modeling capabilities. Multiplex Graph Neural Networks (MGNNs), typically comprising view-specific GNNs and a multi-view integration layer, have achieved advanced performance in various downstream tasks. However, their reliance on neighborhood aggregation poses challenges for deployment in latency-sensitive applications. Motivated by recent GNN-to-MLP knowledge distillation frameworks, we propose Multiplex Graph-Free Neural Networks (MGFNN and MGFNN+) to combine MGNNs' superior performance and MLPs' efficient inference via knowledge distillation. MGFNN directly trains student MLPs with node features as input and soft labels from teacher MGNNs as targets. MGFNN+ further employs a low-rank approximation-based reparameterization to learn node-wise coefficients, enabling adaptive knowledge ensemble from each view-specific GNN. This node-wise multi-view ensemble distillation strategy allows student MLPs to learn more informative multiplex semantic knowledge for different nodes. Experiments show that MGFNNs achieve average accuracy improvements of about 10% over vanilla MLPs and perform comparably or even better to teacher MGNNs (accurate); MGFNNs achieve a 35.40$\times$-89.14$\times$ speedup in inference over MGNNs (efficient); MGFNN+ adaptively assigns different coefficients for multi-view ensemble distillation regarding different nodes (interpretable).
Continuous Concepts Removal in Text-to-image Diffusion Models
Nov 30, 2024
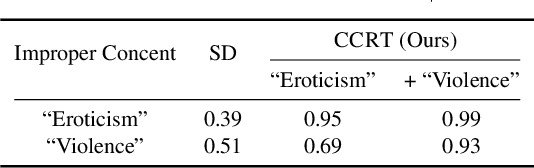

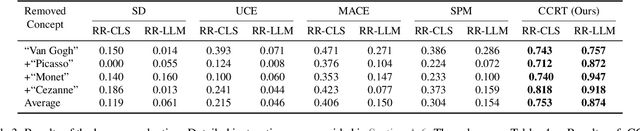
Text-to-image diffusion models have shown an impressive ability to generate high-quality images from input textual descriptions. However, concerns have been raised about the potential for these models to create content that infringes on copyrights or depicts disturbing subject matter. Removing specific concepts from these models is a promising potential solution to this problem. However, existing methods for concept removal do not work well in practical but challenging scenarios where concepts need to be continuously removed. Specifically, these methods lead to poor alignment between the text prompts and the generated image after the continuous removal process. To address this issue, we propose a novel approach called CCRT that includes a designed knowledge distillation paradigm. It constrains the text-image alignment behavior during the continuous concept removal process by using a set of text prompts generated through our genetic algorithm, which employs a designed fuzzing strategy. We conduct extensive experiments involving the removal of various concepts. The results evaluated through both algorithmic metrics and human studies demonstrate that our CCRT can effectively remove the targeted concepts in a continuous manner while maintaining the high generation quality (e.g., text-image alignment) of the model.
Negative-Free Self-Supervised Gaussian Embedding of Graphs
Nov 02, 2024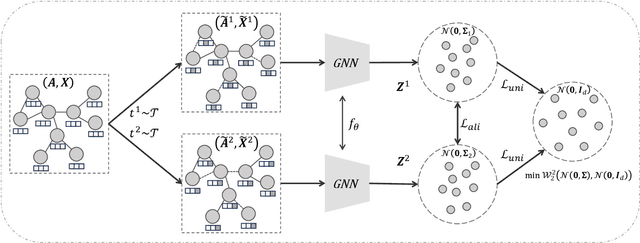
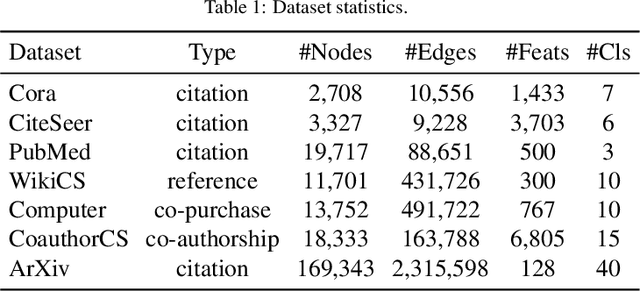
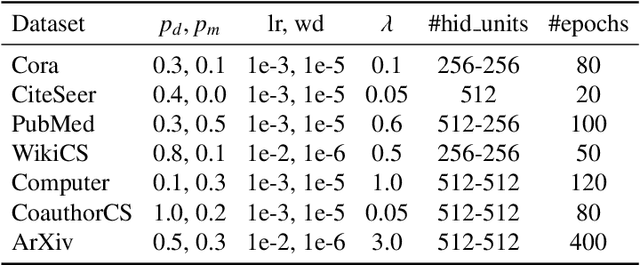
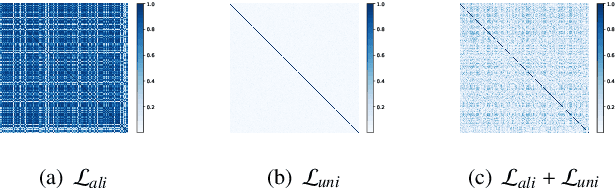
Graph Contrastive Learning (GCL) has recently emerged as a promising graph self-supervised learning framework for learning discriminative node representations without labels. The widely adopted objective function of GCL benefits from two key properties: \emph{alignment} and \emph{uniformity}, which align representations of positive node pairs while uniformly distributing all representations on the hypersphere. The uniformity property plays a critical role in preventing representation collapse and is achieved by pushing apart augmented views of different nodes (negative pairs). As such, existing GCL methods inherently rely on increasing the quantity and quality of negative samples, resulting in heavy computational demands, memory overhead, and potential class collision issues. In this study, we propose a negative-free objective to achieve uniformity, inspired by the fact that points distributed according to a normalized isotropic Gaussian are uniformly spread across the unit hypersphere. Therefore, we can minimize the distance between the distribution of learned representations and the isotropic Gaussian distribution to promote the uniformity of node representations. Our method also distinguishes itself from other approaches by eliminating the need for a parameterized mutual information estimator, an additional projector, asymmetric structures, and, crucially, negative samples. Extensive experiments over seven graph benchmarks demonstrate that our proposal achieves competitive performance with fewer parameters, shorter training times, and lower memory consumption compared to existing GCL methods.
Heterogeneous Space Fusion and Dual-Dimension Attention: A New Paradigm for Speech Enhancement
Aug 13, 2024Self-supervised learning has demonstrated impressive performance in speech tasks, yet there remains ample opportunity for advancement in the realm of speech enhancement research. In addressing speech tasks, confining the attention mechanism solely to the temporal dimension poses limitations in effectively focusing on critical speech features. Considering the aforementioned issues, our study introduces a novel speech enhancement framework, HFSDA, which skillfully integrates heterogeneous spatial features and incorporates a dual-dimension attention mechanism to significantly enhance speech clarity and quality in noisy environments. By leveraging self-supervised learning embeddings in tandem with Short-Time Fourier Transform (STFT) spectrogram features, our model excels at capturing both high-level semantic information and detailed spectral data, enabling a more thorough analysis and refinement of speech signals. Furthermore, we employ the innovative Omni-dimensional Dynamic Convolution (ODConv) technology within the spectrogram input branch, enabling enhanced extraction and integration of crucial information across multiple dimensions. Additionally, we refine the Conformer model by enhancing its feature extraction capabilities not only in the temporal dimension but also across the spectral domain. Extensive experiments on the VCTK-DEMAND dataset show that HFSDA is comparable to existing state-of-the-art models, confirming the validity of our approach.