 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Accurate, Efficient, and Interpretable MLPs on Multiplex Graphs via Node-wise Multi-View Ensemble Distillation
Paper and Code
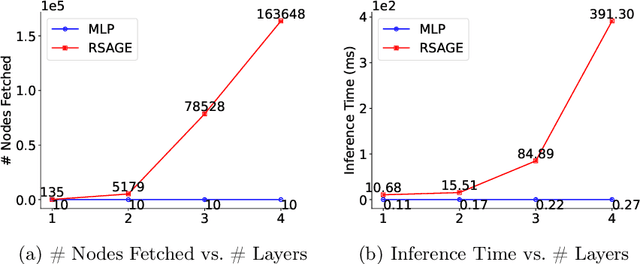
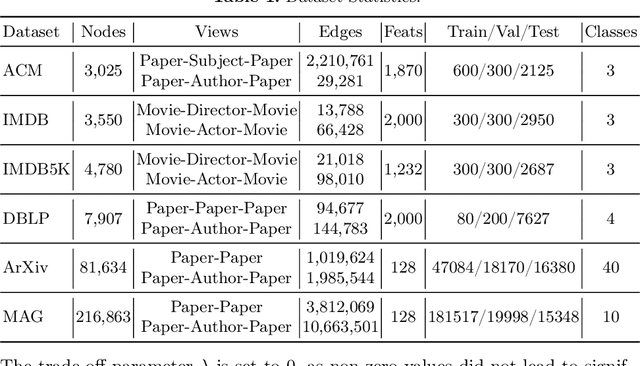
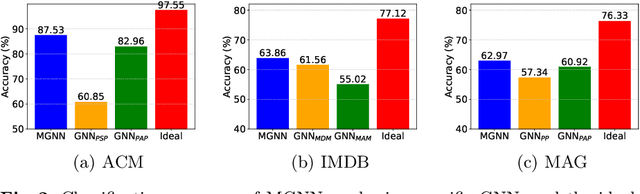
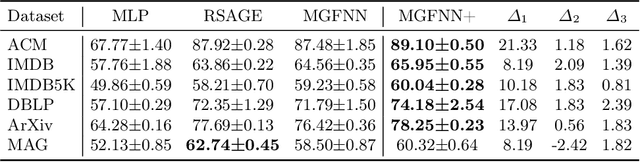
Multiplex graphs, with multiple edge types (graph views) among common nodes, provide richer structural semantics and better modeling capabilities. Multiplex Graph Neural Networks (MGNNs), typically comprising view-specific GNNs and a multi-view integration layer, have achieved advanced performance in various downstream tasks. However, their reliance on neighborhood aggregation poses challenges for deployment in latency-sensitive applications. Motivated by recent GNN-to-MLP knowledge distillation frameworks, we propose Multiplex Graph-Free Neural Networks (MGFNN and MGFNN+) to combine MGNNs' superior performance and MLPs' efficient inference via knowledge distillation. MGFNN directly trains student MLPs with node features as input and soft labels from teacher MGNNs as targets. MGFNN+ further employs a low-rank approximation-based reparameterization to learn node-wise coefficients, enabling adaptive knowledge ensemble from each view-specific GNN. This node-wise multi-view ensemble distillation strategy allows student MLPs to learn more informative multiplex semantic knowledge for different nodes. Experiments show that MGFNNs achieve average accuracy improvements of about 10% over vanilla MLPs and perform comparably or even better to teacher MGNNs (accurate); MGFNNs achieve a 35.40$\times$-89.14$\times$ speedup in inference over MGNNs (efficient); MGFNN+ adaptively assigns different coefficients for multi-view ensemble distillation regarding different nodes (interpretable).