 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering?
Mar 16, 2026Agent skills, structured procedural knowledge packages injected at inference time, are increasingly used to augment LLM agents on software engineering tasks. However, their real utility in end-to-end development settings remains unclear. We present SWE-Skills-Bench, the first requirement-driven benchmark that isolates the marginal utility of agent skills in real-world software engineering (SWE). It pairs 49 public SWE skills with authentic GitHub repositories pinned at fixed commits and requirement documents with explicit acceptance criteria, yielding approximately 565 task instances across six SWE subdomains. We introduce a deterministic verification framework that maps each task's acceptance criteria to execution-based tests, enabling controlled paired evaluation with and without the skill. Our results show that skill injection benefits are far more limited than rapid adoption suggests: 39 of 49 skills yield zero pass-rate improvement, and the average gain is only +1.2%. Token overhead varies from modest savings to a 451% increase while pass rates remain unchanged. Only seven specialized skills produce meaningful gains (up to +30%), while three degrade performance (up to -10%) due to version-mismatched guidance conflicting with project context. These findings suggest that agent skills are a narrow intervention whose utility depends strongly on domain fit, abstraction level, and contextual compatibility. SWE-Skills-Bench provides a testbed for evaluating the design, selection, and deployment of skills in software engineering agents. SWE-Skills-Bench is available at https://github.com/GeniusHTX/SWE-Skills-Bench.
FAIRT2V: Training-Free Debiasing for Text-to-Video Diffusion Models
Jan 28, 2026Text-to-video (T2V) diffusion models have achieved rapid progress, yet their demographic biases, particularly gender bias, remain largely unexplored. We present FairT2V, a training-free debiasing framework for text-to-video generation that mitigates encoder-induced bias without finetuning. We first analyze demographic bias in T2V models and show that it primarily originates from pretrained text encoders, which encode implicit gender associations even for neutral prompts. We quantify this effect with a gender-leaning score that correlates with bias in generated videos. Based on this insight, FairT2V mitigates demographic bias by neutralizing prompt embeddings via anchor-based spherical geodesic transformations while preserving semantics. To maintain temporal coherence, we apply debiasing only during early identity-forming steps through a dynamic denoising schedule. We further propose a video-level fairness evaluation protocol combining VideoLLM-based reasoning with human verification. Experiments on the modern T2V model Open-Sora show that FairT2V substantially reduces demographic bias across occupations with minimal impact on video quality.
Token-Budget-Aware LLM Reasoning
Dec 24, 2024



Reasoning is critical for large language models (LLMs) to excel in a wide range of tasks. While methods like Chain-of-Thought (CoT) reasoning enhance LLM performance by decomposing problems into intermediate steps, they also incur significant overhead in token usage, leading to increased costs. We find that the reasoning process of current LLMs is unnecessarily lengthy and it can be compressed by including a reasonable token budget in the prompt, but the choice of token budget plays a crucial role in the actual compression effectiveness. We then propose a token-budget-aware LLM reasoning framework, which dynamically estimates token budgets for different problems based on reasoning complexity and uses the estimated token budgets to guide the reasoning process. Experiments show that our method effectively reduces token costs in CoT reasoning with only a slight performance reduction, offering a practical solution to balance efficiency and accuracy in LLM reasoning. Code: https://github.com/GeniusHTX/TALE.
Continuous Concepts Removal in Text-to-image Diffusion Models
Nov 30, 2024
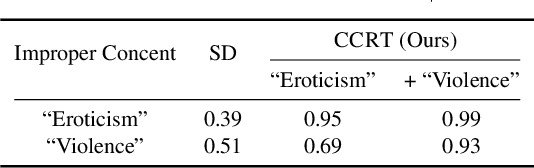

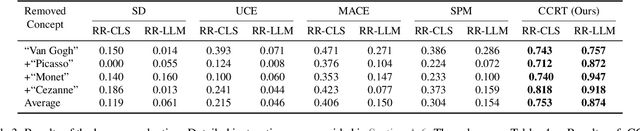
Text-to-image diffusion models have shown an impressive ability to generate high-quality images from input textual descriptions. However, concerns have been raised about the potential for these models to create content that infringes on copyrights or depicts disturbing subject matter. Removing specific concepts from these models is a promising potential solution to this problem. However, existing methods for concept removal do not work well in practical but challenging scenarios where concepts need to be continuously removed. Specifically, these methods lead to poor alignment between the text prompts and the generated image after the continuous removal process. To address this issue, we propose a novel approach called CCRT that includes a designed knowledge distillation paradigm. It constrains the text-image alignment behavior during the continuous concept removal process by using a set of text prompts generated through our genetic algorithm, which employs a designed fuzzing strategy. We conduct extensive experiments involving the removal of various concepts. The results evaluated through both algorithmic metrics and human studies demonstrate that our CCRT can effectively remove the targeted concepts in a continuous manner while maintaining the high generation quality (e.g., text-image alignment) of the model.
Mutual Information Guided Backdoor Mitigation for Pre-trained Encoders
Jun 05, 2024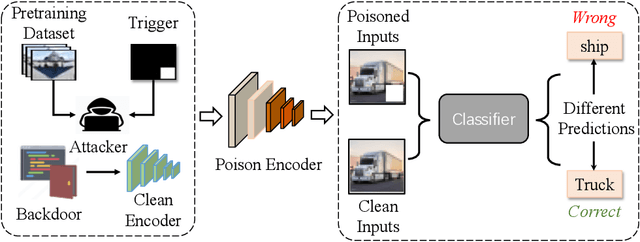
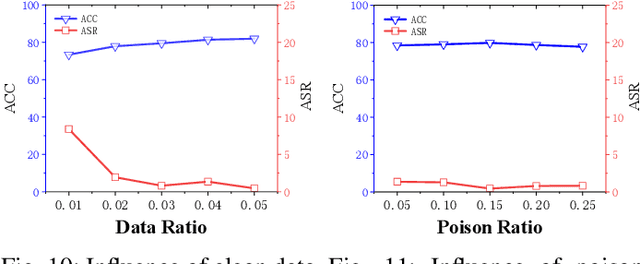
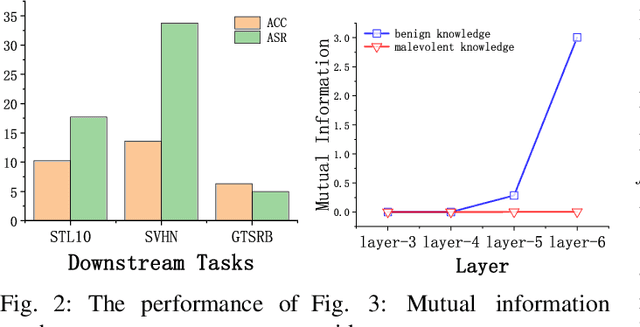
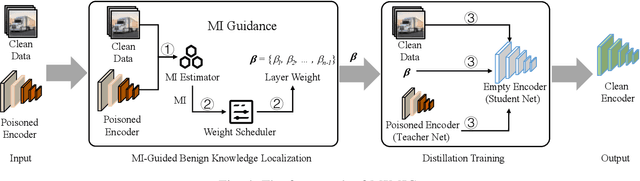
Self-supervised learning (SSL) is increasingly attractive for pre-training encoders without requiring labeled data. Downstream tasks built on top of those pre-trained encoders can achieve nearly state-of-the-art performance. The pre-trained encoders by SSL, however, are vulnerable to backdoor attacks as demonstrated by existing studies. Numerous backdoor mitigation techniques are designed for downstream task models. However, their effectiveness is impaired and limited when adapted to pre-trained encoders, due to the lack of label information when pre-training. To address backdoor attacks against pre-trained encoders, in this paper, we innovatively propose a mutual information guided backdoor mitigation technique, named MIMIC. MIMIC treats the potentially backdoored encoder as the teacher net and employs knowledge distillation to distill a clean student encoder from the teacher net. Different from existing knowledge distillation approaches, MIMIC initializes the student with random weights, inheriting no backdoors from teacher nets. Then MIMIC leverages mutual information between each layer and extracted features to locate where benign knowledge lies in the teacher net, with which distillation is deployed to clone clean features from teacher to student. We craft the distillation loss with two aspects, including clone loss and attention loss, aiming to mitigate backdoors and maintain encoder performance at the same time. Our evaluation conducted on two backdoor attacks in SSL demonstrates that MIMIC can significantly reduce the attack success rate by only utilizing <5% of clean data, surpassing seven state-of-the-art backdoor mitigation techniques.
Towards Imperceptible Backdoor Attack in Self-supervised Learning
May 23, 2024
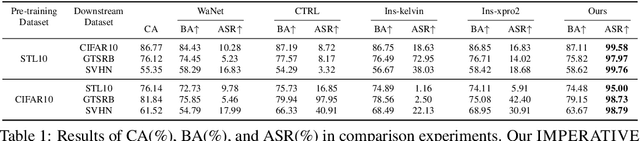


Self-supervised learning models are vulnerable to backdoor attacks. Existing backdoor attacks that are effective in self-supervised learning often involve noticeable triggers, like colored patches, which are vulnerable to human inspection. In this paper, we propose an imperceptible and effective backdoor attack against self-supervised models. We first find that existing imperceptible triggers designed for supervised learning are not as effective in compromising self-supervised models. We then identify this ineffectiveness is attributed to the overlap in distributions between the backdoor and augmented samples used in self-supervised learning. Building on this insight, we design an attack using optimized triggers that are disentangled to the augmented transformation in the self-supervised learning, while also remaining imperceptible to human vision. Experiments on five datasets and seven SSL algorithms demonstrate our attack is highly effective and stealthy. It also has strong resistance to existing backdoor defenses. Our code can be found at https://github.com/Zhang-Henry/IMPERATIVE.
On the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024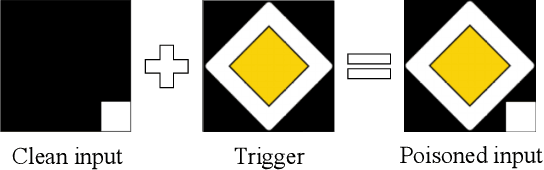
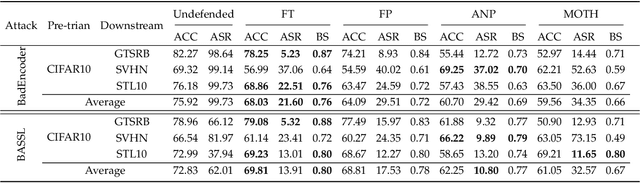
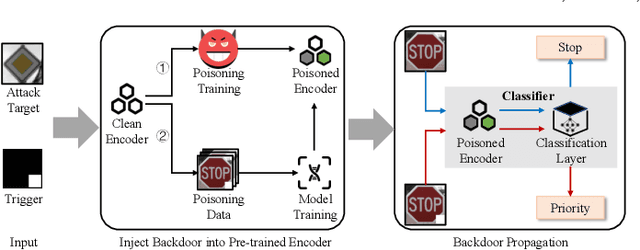
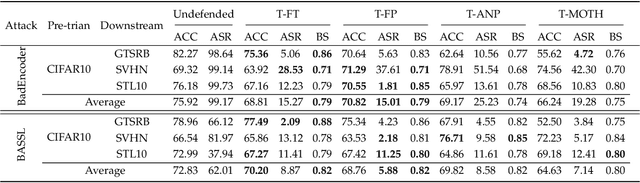
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
An Extractive-and-Abstractive Framework for Source Code Summarization
Jun 15, 2022



(Source) Code summarization aims to automatically generate summaries/comments for a given code snippet in the form of natural language. Such summaries play a key role in helping developers understand and maintain source code. Existing code summarization techniques can be categorized into extractive methods and abstractive methods. The extractive methods extract a subset of important statements and keywords from the code snippet using retrieval techniques, and generate a summary that preserves factual details in important statements and keywords. However, such a subset may miss identifier or entity naming, and consequently, the naturalness of generated summary is usually poor. The abstractive methods can generate human-written-like summaries leveraging encoder-decoder models from the neural machine translation domain. The generated summaries however often miss important factual details. To generate human-written-like summaries with preserved factual details, we propose a novel extractive-and-abstractive framework. The extractive module in the framework performs a task of extractive code summarization, which takes in the code snippet and predicts important statements containing key factual details. The abstractive module in the framework performs a task of abstractive code summarization, which takes in the entire code snippet and important statements in parallel and generates a succinct and human-written-like natural language summary. We evaluate the effectiveness of our technique, called EACS, by conducting extensive experiments on three datasets involving six programming languages. Experimental results show that EACS significantly outperforms state-of-the-art techniques in terms of all three widely used metrics, including BLEU, METEOR, and ROUGH-L.
Code Search based on Context-aware Code Translation
Feb 16, 2022

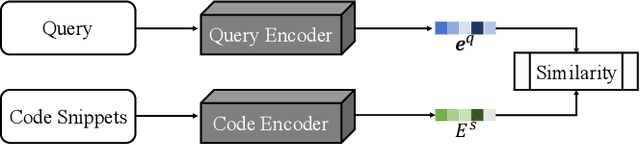
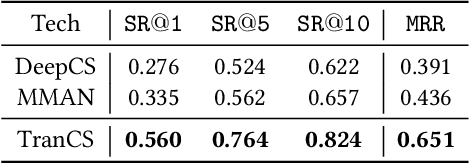
Code search is a widely used technique by developers during software development. It provides semantically similar implementations from a large code corpus to developers based on their queries. Existing techniques leverage deep learning models to construct embedding representations for code snippets and queries, respectively. Features such as abstract syntactic trees, control flow graphs, etc., are commonly employed for representing the semantics of code snippets. However, the same structure of these features does not necessarily denote the same semantics of code snippets, and vice versa. In addition, these techniques utilize multiple different word mapping functions that map query words/code tokens to embedding representations. This causes diverged embeddings of the same word/token in queries and code snippets. We propose a novel context-aware code translation technique that translates code snippets into natural language descriptions (called translations). The code translation is conducted on machine instructions, where the context information is collected by simulating the execution of instructions. We further design a shared word mapping function using one single vocabulary for generating embeddings for both translations and queries. We evaluate the effectiveness of our technique, called TranCS, on the CodeSearchNet corpus with 1,000 queries. Experimental results show that TranCS significantly outperforms state-of-the-art techniques by 49.31% to 66.50% in terms of MRR (mean reciprocal rank).