 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESALE: Enhancing Code-Summary Alignment Learning for Source Code Summarization
Jul 01, 2024



(Source) code summarization aims to automatically generate succinct natural language summaries for given code snippets. Such summaries play a significant role in promoting developers to understand and maintain code. Inspired by neural machine translation, deep learning-based code summarization techniques widely adopt an encoder-decoder framework, where the encoder transforms given code snippets into context vectors, and the decoder decodes context vectors into summaries. Recently, large-scale pre-trained models for source code are equipped with encoders capable of producing general context vectors and have achieved substantial improvements on code summarization. However, although they are usually trained mainly on code-focused tasks and can capture general code features, they still fall short in capturing specific features that need to be summarized. This paper proposes a novel approach to improve code summarization based on summary-focused tasks. Specifically, we exploit a multi-task learning paradigm to train the encoder on three summary-focused tasks to enhance its ability to learn code-summary alignment, including unidirectional language modeling (ULM), masked language modeling (MLM), and action word prediction (AWP). Unlike pre-trained models that mainly predict masked tokens in code snippets, we design ULM and MLM to predict masked words in summaries. Intuitively, predicting words based on given code snippets would help learn the code-summary alignment. Additionally, we introduce the domain-specific task AWP to enhance the ability of the encoder to learn the alignment between action words and code snippets. The extensive experiments on four datasets demonstrate that our approach, called ESALE significantly outperforms baselines in all three widely used metrics, including BLEU, METEOR, and ROUGE-L.
A Prompt Learning Framework for Source Code Summarization
Dec 26, 2023
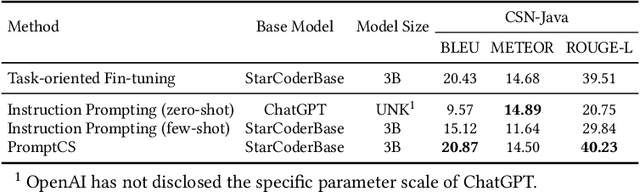
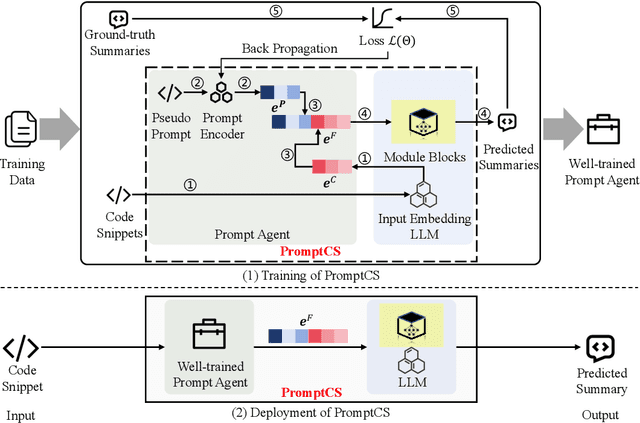
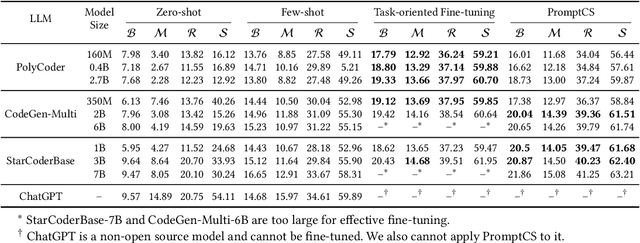
(Source) code summarization is the task of automatically generating natural language summaries for given code snippets. Such summaries play a key role in helping developers understand and maintain source code. Recently, with the successful application of large language models (LLMs) in numerous fields, software engineering researchers have also attempted to adapt LLMs to solve code summarization tasks. The main adaptation schemes include instruction prompting and task-oriented fine-tuning. However, instruction prompting involves designing crafted prompts for zero-shot learning or selecting appropriate samples for few-shot learning and requires users to have professional domain knowledge, while task-oriented fine-tuning requires high training costs. In this paper, we propose a novel prompt learning framework for code summarization called PromptCS. PromptCS trains a prompt agent that can generate continuous prompts to unleash the potential for LLMs in code summarization. Compared to the human-written discrete prompt, the continuous prompts are produced under the guidance of LLMs and are therefore easier to understand by LLMs. PromptCS freezes the parameters of LLMs when training the prompt agent, which can greatly reduce the requirements for training resources. We evaluate PromptCS on the CodeSearchNet dataset involving multiple programming languages. The results show that PromptCS significantly outperforms instruction prompting schemes on all four widely used metrics. In some base LLMs, e.g., CodeGen-Multi-2B and StarCoderBase-1B and -3B, PromptCS even outperforms the task-oriented fine-tuning scheme. More importantly, the training efficiency of PromptCS is faster than the task-oriented fine-tuning scheme, with a more pronounced advantage on larger LLMs. The results of the human evaluation demonstrate that PromptCS can generate more good summaries compared to baselines.
Abstract Syntax Tree for Programming Language Understanding and Representation: How Far Are We?
Dec 01, 2023Programming language understanding and representation (a.k.a code representation learning) has always been a hot and challenging task in software engineering. It aims to apply deep learning techniques to produce numerical representations of the source code features while preserving its semantics. These representations can be used for facilitating subsequent code-related tasks. The abstract syntax tree (AST), a fundamental code feature, illustrates the syntactic information of the source code and has been widely used in code representation learning. However, there is still a lack of systematic and quantitative evaluation of how well AST-based code representation facilitates subsequent code-related tasks. In this paper, we first conduct a comprehensive empirical study to explore the effectiveness of the AST-based code representation in facilitating follow-up code-related tasks. To do so, we compare the performance of models trained with code token sequence (Token for short) based code representation and AST-based code representation on three popular types of code-related tasks. Surprisingly, the overall quantitative statistical results demonstrate that models trained with AST-based code representation consistently perform worse across all three tasks compared to models trained with Token-based code representation. Our further quantitative analysis reveals that models trained with AST-based code representation outperform models trained with Token-based code representation in certain subsets of samples across all three tasks. We also conduct comprehensive experiments to evaluate and reveal the impact of the choice of AST parsing/preprocessing/encoding methods on AST-based code representation and subsequent code-related tasks. Our study provides future researchers with detailed guidance on how to select solutions at each stage to fully exploit AST.
Automatic Code Summarization via ChatGPT: How Far Are We?
May 22, 2023To support software developers in understanding and maintaining programs, various automatic code summarization techniques have been proposed to generate a concise natural language comment for a given code snippet. Recently, the emergence of large language models (LLMs) has led to a great boost in the performance of natural language processing tasks. Among them, ChatGPT is the most popular one which has attracted wide attention from the software engineering community. However, it still remains unclear how ChatGPT performs in (automatic) code summarization. Therefore, in this paper, we focus on evaluating ChatGPT on a widely-used Python dataset called CSN-Python and comparing it with several state-of-the-art (SOTA) code summarization models. Specifically, we first explore an appropriate prompt to guide ChatGPT to generate in-distribution comments. Then, we use such a prompt to ask ChatGPT to generate comments for all code snippets in the CSN-Python test set. We adopt three widely-used metrics (including BLEU, METEOR, and ROUGE-L) to measure the quality of the comments generated by ChatGPT and SOTA models (including NCS, CodeBERT, and CodeT5). The experimental results show that in terms of BLEU and ROUGE-L, ChatGPT's code summarization performance is significantly worse than all three SOTA models. We also present some cases and discuss the advantages and disadvantages of ChatGPT in code summarization. Based on the findings, we outline several open challenges and opportunities in ChatGPT-based code summarization.
An Extractive-and-Abstractive Framework for Source Code Summarization
Jun 15, 2022



(Source) Code summarization aims to automatically generate summaries/comments for a given code snippet in the form of natural language. Such summaries play a key role in helping developers understand and maintain source code. Existing code summarization techniques can be categorized into extractive methods and abstractive methods. The extractive methods extract a subset of important statements and keywords from the code snippet using retrieval techniques, and generate a summary that preserves factual details in important statements and keywords. However, such a subset may miss identifier or entity naming, and consequently, the naturalness of generated summary is usually poor. The abstractive methods can generate human-written-like summaries leveraging encoder-decoder models from the neural machine translation domain. The generated summaries however often miss important factual details. To generate human-written-like summaries with preserved factual details, we propose a novel extractive-and-abstractive framework. The extractive module in the framework performs a task of extractive code summarization, which takes in the code snippet and predicts important statements containing key factual details. The abstractive module in the framework performs a task of abstractive code summarization, which takes in the entire code snippet and important statements in parallel and generates a succinct and human-written-like natural language summary. We evaluate the effectiveness of our technique, called EACS, by conducting extensive experiments on three datasets involving six programming languages. Experimental results show that EACS significantly outperforms state-of-the-art techniques in terms of all three widely used metrics, including BLEU, METEOR, and ROUGH-L.