 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024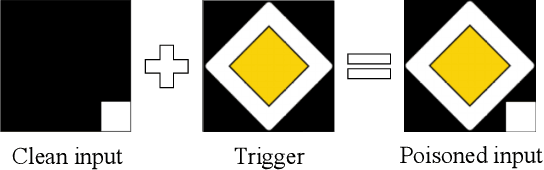
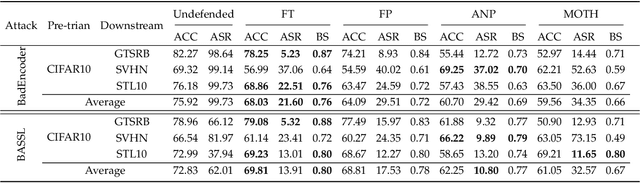
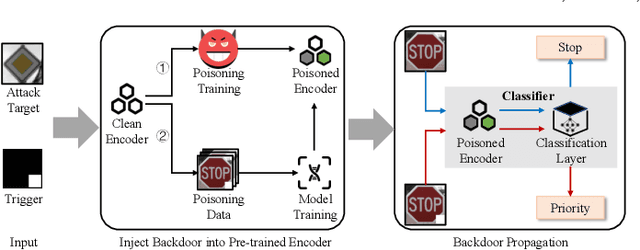
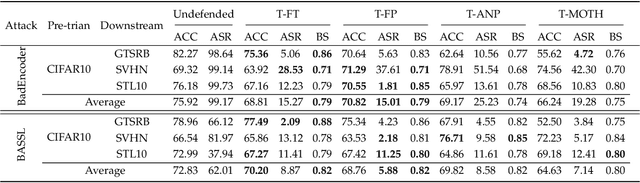
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
Automatic Code Summarization via ChatGPT: How Far Are We?
May 22, 2023To support software developers in understanding and maintaining programs, various automatic code summarization techniques have been proposed to generate a concise natural language comment for a given code snippet. Recently, the emergence of large language models (LLMs) has led to a great boost in the performance of natural language processing tasks. Among them, ChatGPT is the most popular one which has attracted wide attention from the software engineering community. However, it still remains unclear how ChatGPT performs in (automatic) code summarization. Therefore, in this paper, we focus on evaluating ChatGPT on a widely-used Python dataset called CSN-Python and comparing it with several state-of-the-art (SOTA) code summarization models. Specifically, we first explore an appropriate prompt to guide ChatGPT to generate in-distribution comments. Then, we use such a prompt to ask ChatGPT to generate comments for all code snippets in the CSN-Python test set. We adopt three widely-used metrics (including BLEU, METEOR, and ROUGE-L) to measure the quality of the comments generated by ChatGPT and SOTA models (including NCS, CodeBERT, and CodeT5). The experimental results show that in terms of BLEU and ROUGE-L, ChatGPT's code summarization performance is significantly worse than all three SOTA models. We also present some cases and discuss the advantages and disadvantages of ChatGPT in code summarization. Based on the findings, we outline several open challenges and opportunities in ChatGPT-based code summarization.