 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Guided Backdoor Mitigation for Pre-trained Encoders
Jun 05, 2024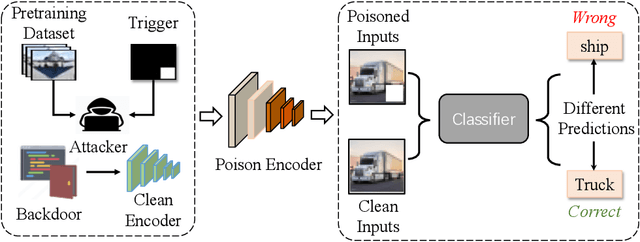
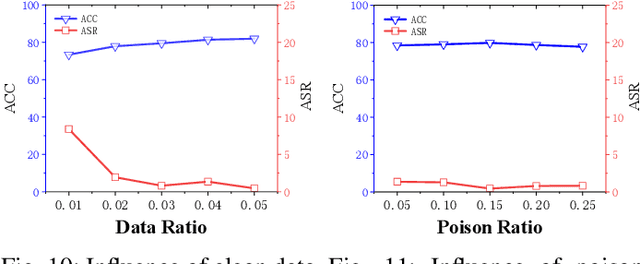
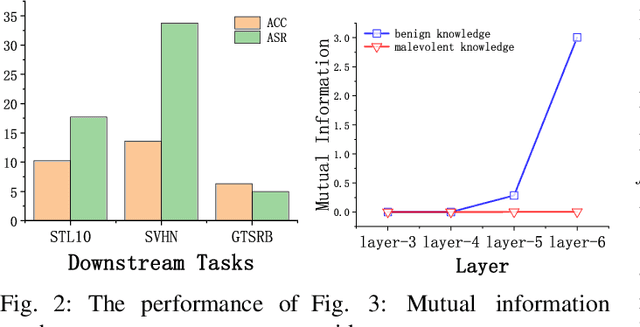
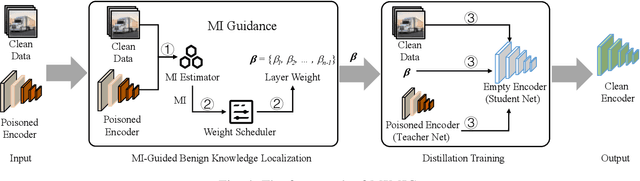
Self-supervised learning (SSL) is increasingly attractive for pre-training encoders without requiring labeled data. Downstream tasks built on top of those pre-trained encoders can achieve nearly state-of-the-art performance. The pre-trained encoders by SSL, however, are vulnerable to backdoor attacks as demonstrated by existing studies. Numerous backdoor mitigation techniques are designed for downstream task models. However, their effectiveness is impaired and limited when adapted to pre-trained encoders, due to the lack of label information when pre-training. To address backdoor attacks against pre-trained encoders, in this paper, we innovatively propose a mutual information guided backdoor mitigation technique, named MIMIC. MIMIC treats the potentially backdoored encoder as the teacher net and employs knowledge distillation to distill a clean student encoder from the teacher net. Different from existing knowledge distillation approaches, MIMIC initializes the student with random weights, inheriting no backdoors from teacher nets. Then MIMIC leverages mutual information between each layer and extracted features to locate where benign knowledge lies in the teacher net, with which distillation is deployed to clone clean features from teacher to student. We craft the distillation loss with two aspects, including clone loss and attention loss, aiming to mitigate backdoors and maintain encoder performance at the same time. Our evaluation conducted on two backdoor attacks in SSL demonstrates that MIMIC can significantly reduce the attack success rate by only utilizing <5% of clean data, surpassing seven state-of-the-art backdoor mitigation techniques.
On the Effectiveness of Distillation in Mitigating Backdoors in Pre-trained Encoder
Mar 06, 2024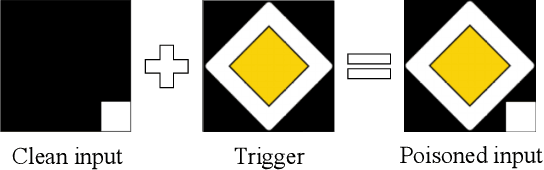
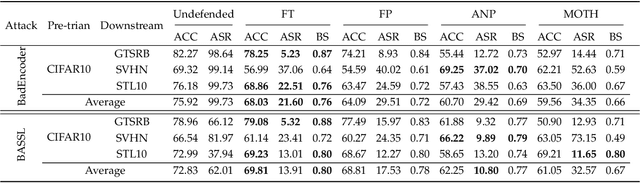
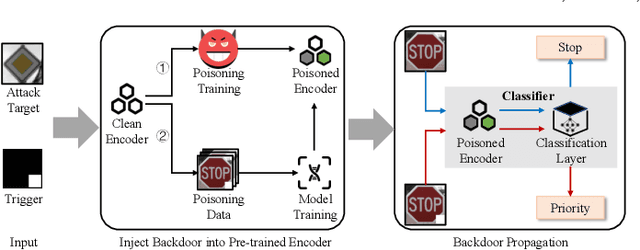
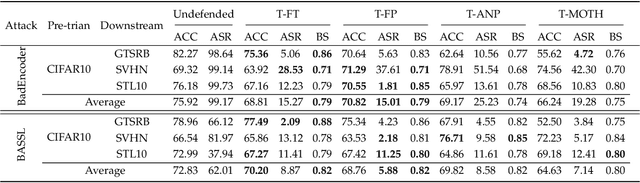
In this paper, we study a defense against poisoned encoders in SSL called distillation, which is a defense used in supervised learning originally. Distillation aims to distill knowledge from a given model (a.k.a the teacher net) and transfer it to another (a.k.a the student net). Now, we use it to distill benign knowledge from poisoned pre-trained encoders and transfer it to a new encoder, resulting in a clean pre-trained encoder. In particular, we conduct an empirical study on the effectiveness and performance of distillation against poisoned encoders. Using two state-of-the-art backdoor attacks against pre-trained image encoders and four commonly used image classification datasets, our experimental results show that distillation can reduce attack success rate from 80.87% to 27.51% while suffering a 6.35% loss in accuracy. Moreover, we investigate the impact of three core components of distillation on performance: teacher net, student net, and distillation loss. By comparing 4 different teacher nets, 3 student nets, and 6 distillation losses, we find that fine-tuned teacher nets, warm-up-training-based student nets, and attention-based distillation loss perform best, respectively.
A Prompt Learning Framework for Source Code Summarization
Dec 26, 2023
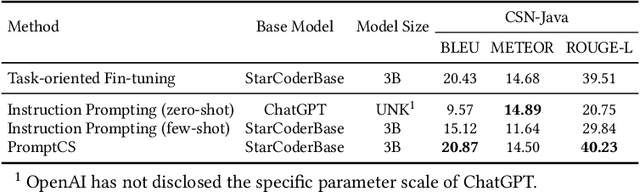
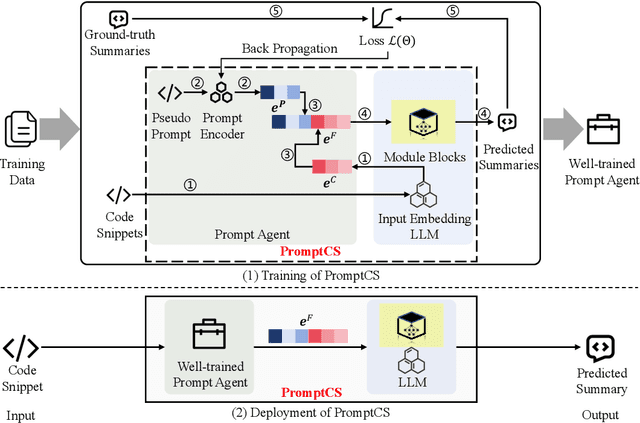
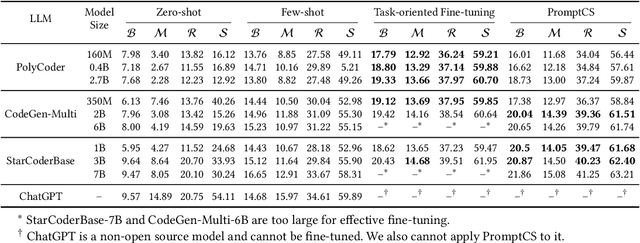
(Source) code summarization is the task of automatically generating natural language summaries for given code snippets. Such summaries play a key role in helping developers understand and maintain source code. Recently, with the successful application of large language models (LLMs) in numerous fields, software engineering researchers have also attempted to adapt LLMs to solve code summarization tasks. The main adaptation schemes include instruction prompting and task-oriented fine-tuning. However, instruction prompting involves designing crafted prompts for zero-shot learning or selecting appropriate samples for few-shot learning and requires users to have professional domain knowledge, while task-oriented fine-tuning requires high training costs. In this paper, we propose a novel prompt learning framework for code summarization called PromptCS. PromptCS trains a prompt agent that can generate continuous prompts to unleash the potential for LLMs in code summarization. Compared to the human-written discrete prompt, the continuous prompts are produced under the guidance of LLMs and are therefore easier to understand by LLMs. PromptCS freezes the parameters of LLMs when training the prompt agent, which can greatly reduce the requirements for training resources. We evaluate PromptCS on the CodeSearchNet dataset involving multiple programming languages. The results show that PromptCS significantly outperforms instruction prompting schemes on all four widely used metrics. In some base LLMs, e.g., CodeGen-Multi-2B and StarCoderBase-1B and -3B, PromptCS even outperforms the task-oriented fine-tuning scheme. More importantly, the training efficiency of PromptCS is faster than the task-oriented fine-tuning scheme, with a more pronounced advantage on larger LLMs. The results of the human evaluation demonstrate that PromptCS can generate more good summaries compared to baselines.
Automatic Code Summarization via ChatGPT: How Far Are We?
May 22, 2023To support software developers in understanding and maintaining programs, various automatic code summarization techniques have been proposed to generate a concise natural language comment for a given code snippet. Recently, the emergence of large language models (LLMs) has led to a great boost in the performance of natural language processing tasks. Among them, ChatGPT is the most popular one which has attracted wide attention from the software engineering community. However, it still remains unclear how ChatGPT performs in (automatic) code summarization. Therefore, in this paper, we focus on evaluating ChatGPT on a widely-used Python dataset called CSN-Python and comparing it with several state-of-the-art (SOTA) code summarization models. Specifically, we first explore an appropriate prompt to guide ChatGPT to generate in-distribution comments. Then, we use such a prompt to ask ChatGPT to generate comments for all code snippets in the CSN-Python test set. We adopt three widely-used metrics (including BLEU, METEOR, and ROUGE-L) to measure the quality of the comments generated by ChatGPT and SOTA models (including NCS, CodeBERT, and CodeT5). The experimental results show that in terms of BLEU and ROUGE-L, ChatGPT's code summarization performance is significantly worse than all three SOTA models. We also present some cases and discuss the advantages and disadvantages of ChatGPT in code summarization. Based on the findings, we outline several open challenges and opportunities in ChatGPT-based code summarization.