 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Generation in Metric Spaces
Feb 07, 2026We study generation in separable metric instance spaces. We extend the language generation framework from Kleinberg and Mullainathan [2024] beyond countable domains by defining novelty through metric separation and allowing asymmetric novelty parameters for the adversary and the generator. We introduce the $(\varepsilon,\varepsilon')$-closure dimension, a scale-sensitive analogue of closure dimension, which yields characterizations of uniform and non-uniform generatability and a sufficient condition for generation in the limit. Along the way, we identify a sharp geometric contrast. Namely, in doubling spaces, including all finite-dimensional normed spaces, generatability is stable across novelty scales and invariant under equivalent metrics. In general metric spaces, however, generatability can be highly scale-sensitive and metric-dependent; even in the natural infinite-dimensional Hilbert space $\ell^2$, all notions of generation may fail abruptly as the novelty parameters vary.
Mutual Information Guided Backdoor Mitigation for Pre-trained Encoders
Jun 05, 2024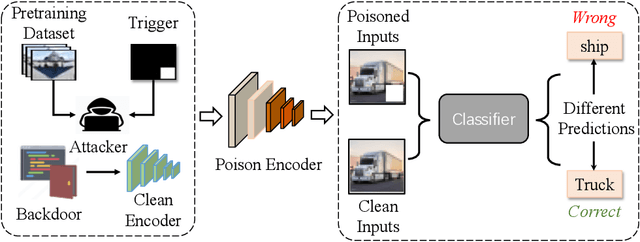
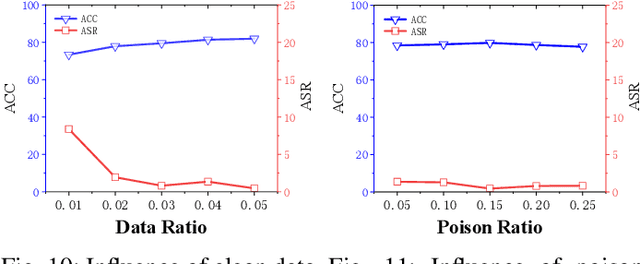
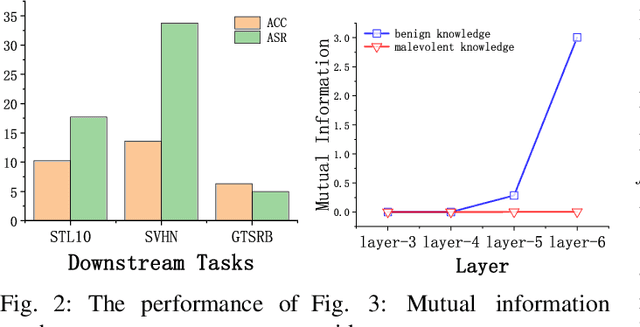
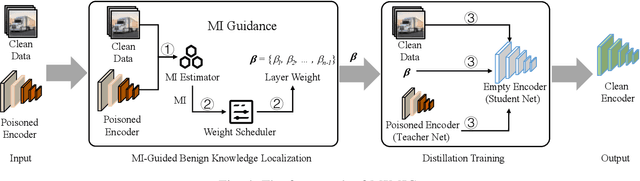
Self-supervised learning (SSL) is increasingly attractive for pre-training encoders without requiring labeled data. Downstream tasks built on top of those pre-trained encoders can achieve nearly state-of-the-art performance. The pre-trained encoders by SSL, however, are vulnerable to backdoor attacks as demonstrated by existing studies. Numerous backdoor mitigation techniques are designed for downstream task models. However, their effectiveness is impaired and limited when adapted to pre-trained encoders, due to the lack of label information when pre-training. To address backdoor attacks against pre-trained encoders, in this paper, we innovatively propose a mutual information guided backdoor mitigation technique, named MIMIC. MIMIC treats the potentially backdoored encoder as the teacher net and employs knowledge distillation to distill a clean student encoder from the teacher net. Different from existing knowledge distillation approaches, MIMIC initializes the student with random weights, inheriting no backdoors from teacher nets. Then MIMIC leverages mutual information between each layer and extracted features to locate where benign knowledge lies in the teacher net, with which distillation is deployed to clone clean features from teacher to student. We craft the distillation loss with two aspects, including clone loss and attention loss, aiming to mitigate backdoors and maintain encoder performance at the same time. Our evaluation conducted on two backdoor attacks in SSL demonstrates that MIMIC can significantly reduce the attack success rate by only utilizing <5% of clean data, surpassing seven state-of-the-art backdoor mitigation techniques.
Improving Prototypical Part Networks with Reward Reweighing, Reselection, and Retraining
Jul 08, 2023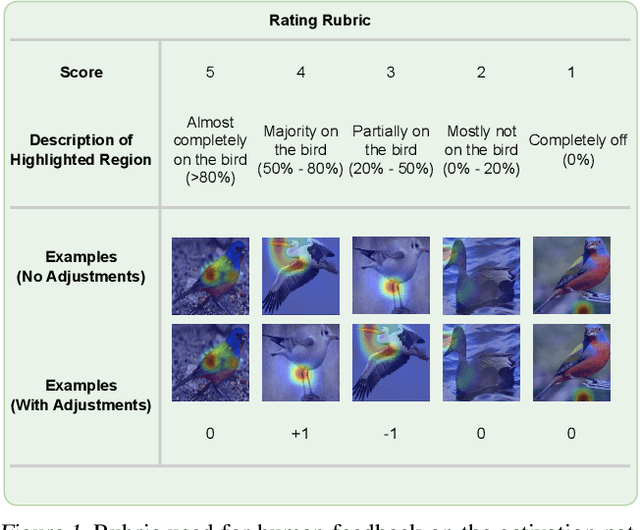
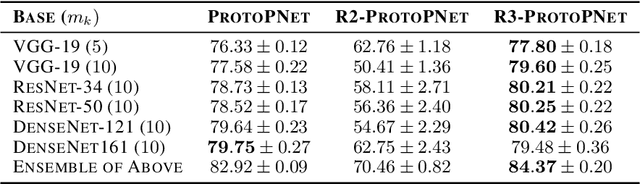

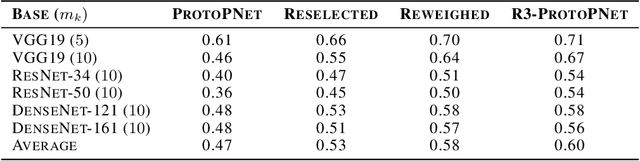
In recent years, work has gone into developing deep interpretable methods for image classification that clearly attributes a model's output to specific features of the data. One such of these methods is the prototypical part network (ProtoPNet), which attempts to classify images based on meaningful parts of the input. While this method results in interpretable classifications, this method often learns to classify from spurious or inconsistent parts of the image. Hoping to remedy this, we take inspiration from the recent developments in Reinforcement Learning with Human Feedback (RLHF) to fine-tune these prototypes. By collecting human annotations of prototypes quality via a 1-5 scale on the CUB-200-2011 dataset, we construct a reward model that learns to identify non-spurious prototypes. In place of a full RL update, we propose the reweighted, reselected, and retrained prototypical part network (R3-ProtoPNet), which adds an additional three steps to the ProtoPNet training loop. The first two steps are reward-based reweighting and reselection, which align prototypes with human feedback. The final step is retraining to realign the model's features with the updated prototypes. We find that R3-ProtoPNet improves the overall consistency and meaningfulness of the prototypes, but lower the test predictive accuracy when used independently. When multiple R3-ProtoPNets are incorporated into an ensemble, we find an increase in test predictive performance while maintaining interpretability.
Jac-PCG Based Low-Complexity Precoding for Extremely Large-Scale MIMO Systems
May 23, 2023



Extremely large-scale multiple-input-multipleoutput (XL-MIMO) has been reviewed as a promising technology for future sixth-generation (6G) networks to achieve higher performance. In practice, various linear precoding schemes, such as zero-forcing (ZF) and regularized ZF (RZF) precoding, are sufficient to achieve near-optimal performance in traditional massive MIMO (mMIMO) systems. It is critical to note that in large-scale antenna arrays the operation of channel matrix inversion poses a significant computational challenge for these precoders. Therefore, we explore several iterative methods for determining the precoding matrix for XL-MIMO systems instead of direct matrix inversion. Taking into account small- and large-scale fading as well as spatial correlation between antennas, we study their computational complexity and convergence rate. Furthermore, we propose the Jacobi-Preconditioning Conjugate Gradient (Jac-PCG) iterative inversion method, which enjoys a faster convergence speed than the CG method. Besides, the closed-form expression of spectral efficiency (SE) considering the interference between subarrays in downlink XL-MIMO systems is derived. In the numerical results, it is shown that the complexity given by the Jac-PCG algorithm has about 54% reduction than the traditional RZF algorithm at basically the same SE performance.