 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity Distributed Combining Design for Near-Field Cell-Free XL-MIMO Systems
Feb 03, 2026In this paper, we investigate the low-complexity distributed combining scheme design for near-field cell-free extremely large-scale multiple-input-multiple-output (CF XL-MIMO) systems. Firstly, we construct the uplink spectral efficiency (SE) performance analysis framework for CF XL-MIMO systems over centralized and distributed processing schemes. Notably, we derive the centralized minimum mean-square error (CMMSE) and local minimum mean-square error (LMMSE) combining schemes over arbitrary channel estimators. Then, focusing on the CMMSE and LMMSE combining schemes, we propose five low-complexity distributed combining schemes based on the matrix approximation methodology or the symmetric successive over relaxation (SSOR) algorithm. More specifically, we propose two matrix approximation methodology-aided combining schemes: Global Statistics \& Local Instantaneous information-based MMSE (GSLI-MMSE) and Statistics matrix Inversion-based LMMSE (SI-LMMSE). These two schemes are derived by approximating the global instantaneous information in the CMMSE combining and the local instantaneous information in the LMMSE combining with the global and local statistics information by asymptotic analysis and matrix expectation approximation, respectively. Moreover, by applying the low-complexity SSOR algorithm to iteratively solve the matrix inversion in the LMMSE combining, we derive three distributed SSOR-based LMMSE combining schemes, distinguished from the applied information and initial values.
Flexible MIMO for Future Wireless Communications: Which Flexibilities are Possible?
Jun 09, 2025To enable next-generation wireless communication networks with modest spectrum availability, multiple-input multiple-output (MIMO) technology needs to undergo further evolution. In this paper, we introduce a promising next-generation wireless communication concept: flexible MIMO technology. This technology represents a MIMO technology with flexible physical configurations and integrated applications. We categorize twelve representative flexible MIMO technologies into three major classifications: flexible deployment characteristics-based, flexible geometry characteristics-based, and flexible real-time modifications-based. Then, we provide a comprehensive overview of their fundamental characteristics, potential, and challenges. Furthermore, we demonstrate three vital enablers for the flexible MIMO technology, including efficient channel state information (CSI) acquisition schemes, low-complexity beamforming design, and explainable artificial intelligence (AI)-enabled optimization. Within these areas, eight critical sub-enabling technologies are discussed in detail. Finally, we present two case studies-pre-optimized irregular arrays and cell-free movable antennas-where significant potential for flexible MIMO technologies to enhance the system capacity is showcased.
Channel Estimation for Rydberg Atomic Receivers
Mar 12, 2025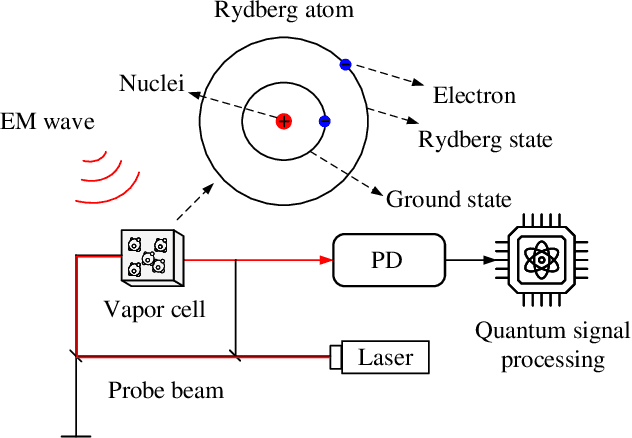
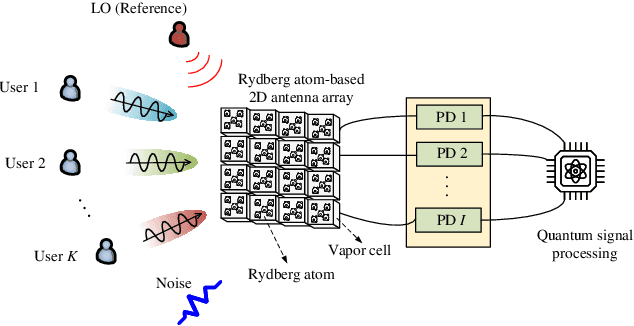
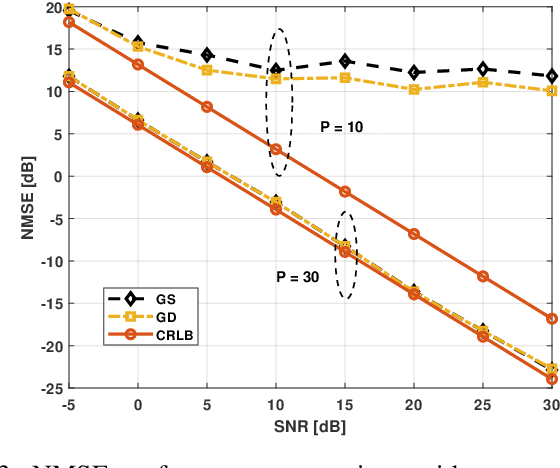
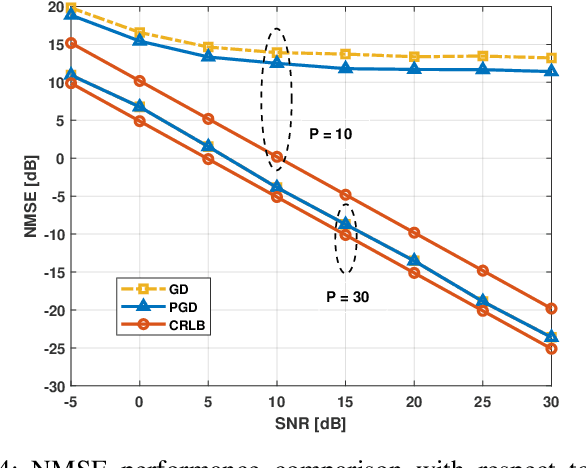
The rapid development of the quantum technology presents huge opportunities for 6G communications. Leveraging the quantum properties of highly excited Rydberg atoms, Rydberg atom-based antennas present distinct advantages, such as high sensitivity, broad frequency range, and compact size, over traditional antennas. To realize efficient precoding, accurate channel state information is essential. However, due to the distinct characteristics of atomic receivers, traditional channel estimation algorithms developed for conventional receivers are no longer applicable. To this end, we propose a novel channel estimation algorithm based on projection gradient descent (PGD), which is applicable to both one-dimensional (1D) and twodimensional (2D) arrays. Simulation results are provided to show the effectiveness of our proposed channel estimation method.
Beamforming Design for Beyond Diagonal RIS-Aided Cell-Free Massive MIMO Systems
Mar 10, 2025

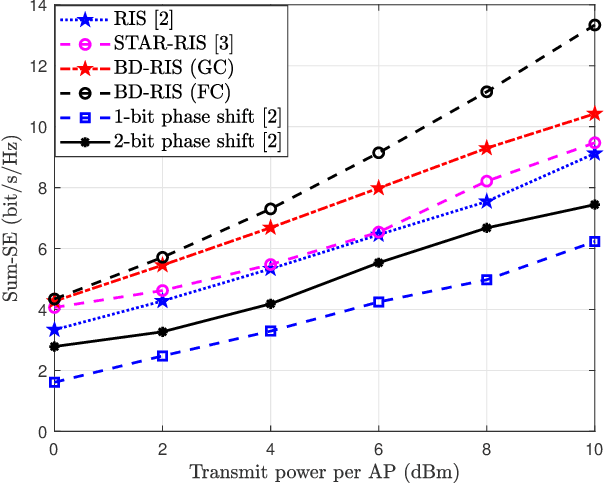

Reconfigurable intelligent surface (RIS)-aided cell-free (CF) massive multiple-input multiple-output (mMIMO) is a promising architecture for further improving spectral efficiency (SE) with low cost and power consumption. However, conventional RIS has inevitable limitations due to its capability of only reflecting signals. In contrast, beyond-diagonal RIS (BD-RIS), with its ability to both reflect and transmit signals, has gained great attention. This correspondence focuses on using BD-RIS to improve the sum SE of CF mMIMO systems. This requires completing the beamforming design under the transmit power constraints and unitary constraints of the BD-RIS, by optimizing active and passive beamformer simultaneously. To tackle this issue, we introduce an alternating optimization algorithm that decomposes it using fractional programming and solves the subproblems alternatively. Moreover, to address the challenge introduced by the unitary constraint on the beamforming matrix of the BD-RIS, a manifold optimization algorithm is proposed to solve the problem optimally. Simulation results show that BD-RISs outperform RISs comprehensively, especially in the case of the full connected architecture which achieves the best performance, enhancing the sum SE by around 40% compared to ideal RISs.
Deep Unfolding Beamforming and Power Control Designs for Multi-Port Matching Networks
Dec 09, 2024



The key technologies of sixth generation (6G), such as ultra-massive multiple-input multiple-output (MIMO), enable intricate interactions between antennas and wireless propagation environments. As a result, it becomes necessary to develop joint models that encompass both antennas and wireless propagation channels. To achieve this, we utilize the multi-port communication theory, which considers impedance matching among the source, transmission medium, and load to facilitate efficient power transfer. Specifically, we first investigate the impact of insertion loss, mutual coupling, and other factors on the performance of multi-port matching networks. Next, to further improve system performance, we explore two important deep unfolding designs for the multi-port matching networks: beamforming and power control, respectively. For the hybrid beamforming, we develop a deep unfolding framework, i.e., projected gradient descent (PGD)-Net based on unfolding projected gradient descent. For the power control, we design a deep unfolding network, graph neural network (GNN) aided alternating optimization (AO)Net, which considers the interaction between different ports in optimizing power allocation. Numerical results verify the necessity of considering insertion loss in the dynamic metasurface antenna (DMA) performance analysis. Besides, the proposed PGD-Net based hybrid beamforming approaches approximate the conventional model-based algorithm with very low complexity. Moreover, our proposed power control scheme has a fast run time compared to the traditional weighted minimum mean squared error (WMMSE) method.
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Oct 14, 2024



Retrieval-augmented generation (RAG) is an effective technique that enables large language models (LLMs) to utilize external knowledge sources for generation. However, current RAG systems are solely based on text, rendering it impossible to utilize vision information like layout and images that play crucial roles in real-world multi-modality documents. In this paper, we introduce VisRAG, which tackles this issue by establishing a vision-language model (VLM)-based RAG pipeline. In this pipeline, instead of first parsing the document to obtain text, the document is directly embedded using a VLM as an image and then retrieved to enhance the generation of a VLM. Compared to traditional text-based RAG, VisRAG maximizes the retention and utilization of the data information in the original documents, eliminating the information loss introduced during the parsing process. We collect both open-source and synthetic data to train the retriever in VisRAG and explore a variety of generation methods. Experiments demonstrate that VisRAG outperforms traditional RAG in both the retrieval and generation stages, achieving a 25--39\% end-to-end performance gain over traditional text-based RAG pipeline. Further analysis reveals that VisRAG is effective in utilizing training data and demonstrates strong generalization capability, positioning it as a promising solution for RAG on multi-modality documents. Our code and data are available at https://github.com/openbmb/visrag .
Resource Allocation for Near-Field Communications: Fundamentals, Tools, and Outlooks
Oct 27, 2023Extremely large-scale multiple-input-multiple output (XL-MIMO) is a promising technology to achieve high spectral efficiency (SE) and energy efficiency (EE) in future wireless systems. The larger array aperture of XL-MIMO makes communication scenarios closer to the near-field region. Therefore, near-field resource allocation is essential in realizing the above key performance indicators (KPIs). Moreover, the overall performance of XL-MIMO systems heavily depends on the channel characteristics of the selected users, eliminating interference between users through beamforming, power control, etc. The above resource allocation issue constitutes a complex joint multi-objective optimization problem since many variables and parameters must be optimized, including the spatial degree of freedom, rate, power allocation, and transmission technique. In this article, we review the basic properties of near-field communications and focus on the corresponding "resource allocation" problems. First, we identify available resources in near-field communication systems and highlight their distinctions from far-field communications. Then, we summarize optimization tools, such as numerical techniques and machine learning methods, for addressing near-field resource allocation, emphasizing their strengths and limitations. Finally, several important research directions of near-field communications are pointed out for further investigation.
Jac-PCG Based Low-Complexity Precoding for Extremely Large-Scale MIMO Systems
May 23, 2023



Extremely large-scale multiple-input-multipleoutput (XL-MIMO) has been reviewed as a promising technology for future sixth-generation (6G) networks to achieve higher performance. In practice, various linear precoding schemes, such as zero-forcing (ZF) and regularized ZF (RZF) precoding, are sufficient to achieve near-optimal performance in traditional massive MIMO (mMIMO) systems. It is critical to note that in large-scale antenna arrays the operation of channel matrix inversion poses a significant computational challenge for these precoders. Therefore, we explore several iterative methods for determining the precoding matrix for XL-MIMO systems instead of direct matrix inversion. Taking into account small- and large-scale fading as well as spatial correlation between antennas, we study their computational complexity and convergence rate. Furthermore, we propose the Jacobi-Preconditioning Conjugate Gradient (Jac-PCG) iterative inversion method, which enjoys a faster convergence speed than the CG method. Besides, the closed-form expression of spectral efficiency (SE) considering the interference between subarrays in downlink XL-MIMO systems is derived. In the numerical results, it is shown that the complexity given by the Jac-PCG algorithm has about 54% reduction than the traditional RZF algorithm at basically the same SE performance.
Enhancing Chat Language Models by Scaling High-quality Instructional Conversations
May 23, 2023Fine-tuning on instruction data has been widely validated as an effective practice for implementing chat language models like ChatGPT. Scaling the diversity and quality of such data, although straightforward, stands a great chance of leading to improved performance. This paper aims to improve the upper bound of open-source models further. We first provide a systematically designed, diverse, informative, large-scale dataset of instructional conversations, UltraChat, which does not involve human queries. Our objective is to capture the breadth of interactions that a human might have with an AI assistant and employs a comprehensive framework to generate multi-turn conversation iteratively. UltraChat contains 1.5 million high-quality multi-turn dialogues and covers a wide range of topics and instructions. Our statistical analysis of UltraChat reveals its superiority in various key metrics, including scale, average length, diversity, coherence, etc., solidifying its position as a leading open-source dataset. Building upon UltraChat, we fine-tune a LLaMA model to create a powerful conversational model, UltraLLaMA. Our evaluations indicate that UltraLLaMA consistently outperforms other open-source models, including Vicuna, the previously recognized state-of-the-art open-source model. The dataset and the model will be publicly released\footnote{\url{https://github.com/thunlp/UltraChat}}.
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.