 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Bayesian Tensor Reconstruction: An Approximate Message Passing Solution
May 22, 2025
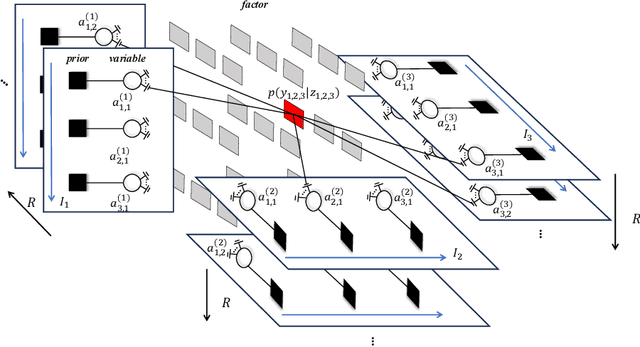

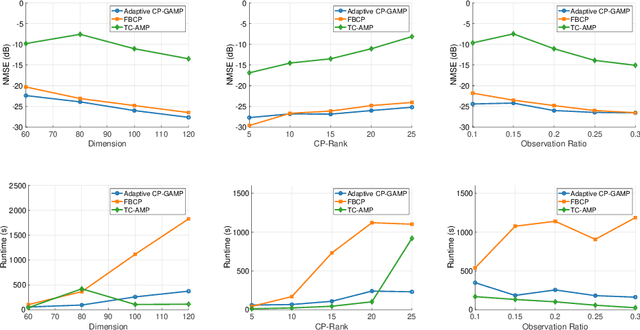
Tensor CANDECOMP/PARAFAC decomposition (CPD) is a fundamental model for tensor reconstruction. Although the Bayesian framework allows for principled uncertainty quantification and automatic hyperparameter learning, existing methods do not scale well for large tensors because of high-dimensional matrix inversions. To this end, we introduce CP-GAMP, a scalable Bayesian CPD algorithm. This algorithm leverages generalized approximate message passing (GAMP) to avoid matrix inversions and incorporates an expectation-maximization routine to jointly infer the tensor rank and noise power. Through multiple experiments, for synthetic 100x100x100 rank 20 tensors with only 20% elements observed, the proposed algorithm reduces runtime by 82.7% compared to the state-of-the-art variational Bayesian CPD method, while maintaining comparable reconstruction accuracy.
Channel Estimation for Rydberg Atomic Receivers
Mar 12, 2025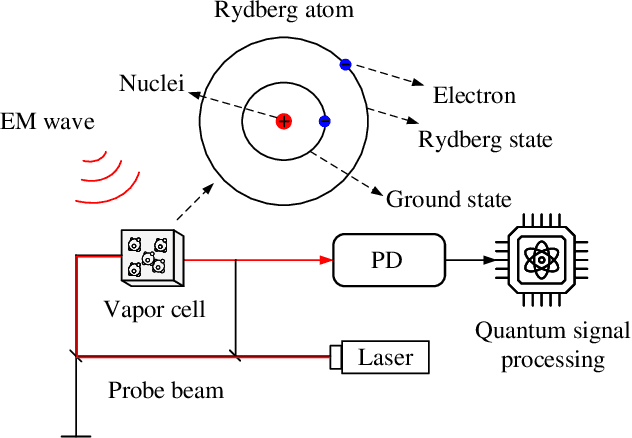
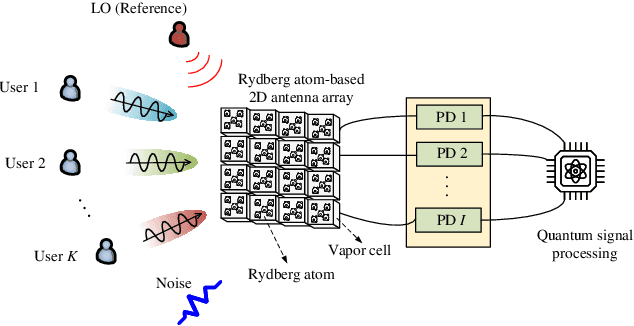
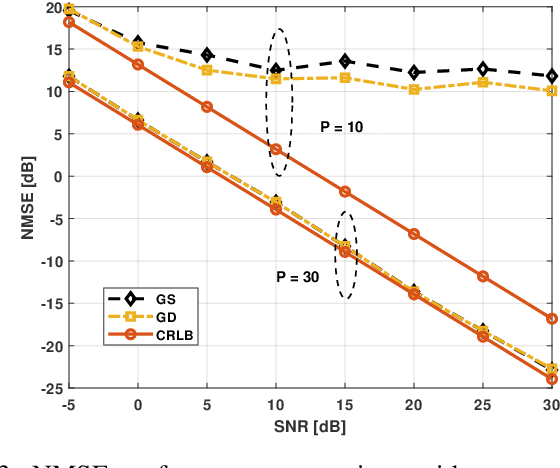
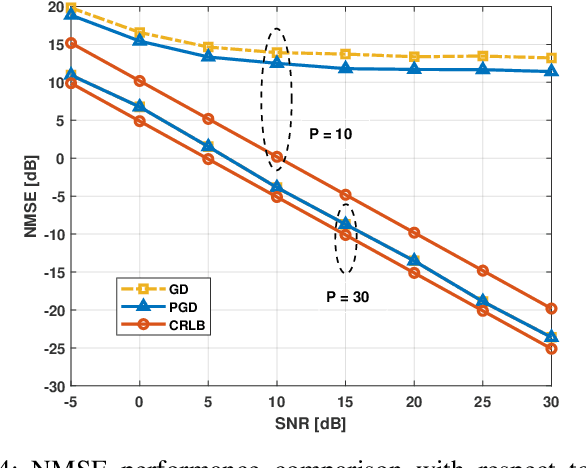
The rapid development of the quantum technology presents huge opportunities for 6G communications. Leveraging the quantum properties of highly excited Rydberg atoms, Rydberg atom-based antennas present distinct advantages, such as high sensitivity, broad frequency range, and compact size, over traditional antennas. To realize efficient precoding, accurate channel state information is essential. However, due to the distinct characteristics of atomic receivers, traditional channel estimation algorithms developed for conventional receivers are no longer applicable. To this end, we propose a novel channel estimation algorithm based on projection gradient descent (PGD), which is applicable to both one-dimensional (1D) and twodimensional (2D) arrays. Simulation results are provided to show the effectiveness of our proposed channel estimation method.
Universal Sleep Decoder: Aligning awake and sleep neural representation across subjects
Sep 28, 2023



Decoding memory content from brain activity during sleep has long been a goal in neuroscience. While spontaneous reactivation of memories during sleep in rodents is known to support memory consolidation and offline learning, capturing memory replay in humans is challenging due to the absence of well-annotated sleep datasets and the substantial differences in neural patterns between wakefulness and sleep. To address these challenges, we designed a novel cognitive neuroscience experiment and collected a comprehensive, well-annotated electroencephalography (EEG) dataset from 52 subjects during both wakefulness and sleep. Leveraging this benchmark dataset, we developed the Universal Sleep Decoder (USD) to align neural representations between wakefulness and sleep across subjects. Our model achieves up to 16.6% top-1 zero-shot accuracy on unseen subjects, comparable to decoding performances using individual sleep data. Furthermore, fine-tuning USD on test subjects enhances decoding accuracy to 25.9% top-1 accuracy, a substantial improvement over the baseline chance of 6.7%. Model comparison and ablation analyses reveal that our design choices, including the use of (i) an additional contrastive objective to integrate awake and sleep neural signals and (ii) the pretrain-finetune paradigm to incorporate different subjects, significantly contribute to these performances. Collectively, our findings and methodologies represent a significant advancement in the field of sleep decoding.
ClusTop: An unsupervised and integrated text clustering and topic extraction framework
Jan 03, 2023Text clustering and topic extraction are two important tasks in text mining. Usually, these two tasks are performed separately. For topic extraction to facilitate clustering, we can first project texts into a topic space and then perform a clustering algorithm to obtain clusters. To promote topic extraction by clustering, we can first obtain clusters with a clustering algorithm and then extract cluster-specific topics. However, this naive strategy ignores the fact that text clustering and topic extraction are strongly correlated and follow a chicken-and-egg relationship. Performing them separately fails to make them mutually benefit each other to achieve the best overall performance. In this paper, we propose an unsupervised text clustering and topic extraction framework (ClusTop) which integrates text clustering and topic extraction into a unified framework and can achieve high-quality clustering result and extract topics from each cluster simultaneously. Our framework includes four components: enhanced language model training, dimensionality reduction, clustering and topic extraction, where the enhanced language model can be viewed as a bridge between clustering and topic extraction. On one hand, it provides text embeddings with a strong cluster structure which facilitates effective text clustering; on the other hand, it pays high attention on the topic related words for topic extraction because of its self-attention architecture. Moreover, the training of enhanced language model is unsupervised. Experiments on two datasets demonstrate the effectiveness of our framework and provide benchmarks for different model combinations in this framework.
Towards Probabilistic Tensor Canonical Polyadic Decomposition 2.0: Automatic Tensor Rank Learning Using Generalized Hyperbolic Prior
Sep 05, 2020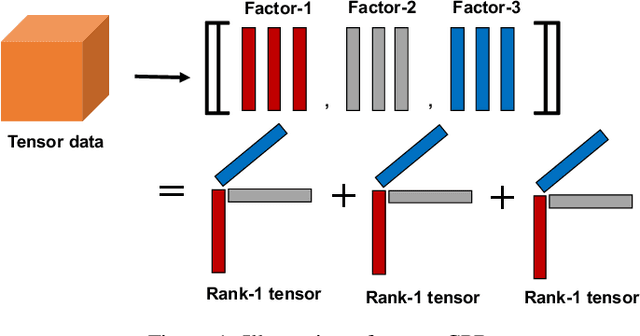
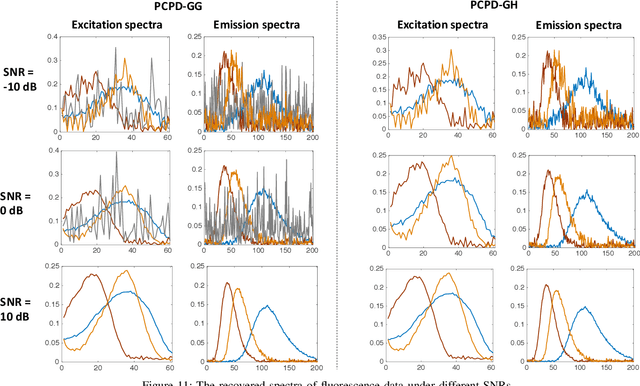
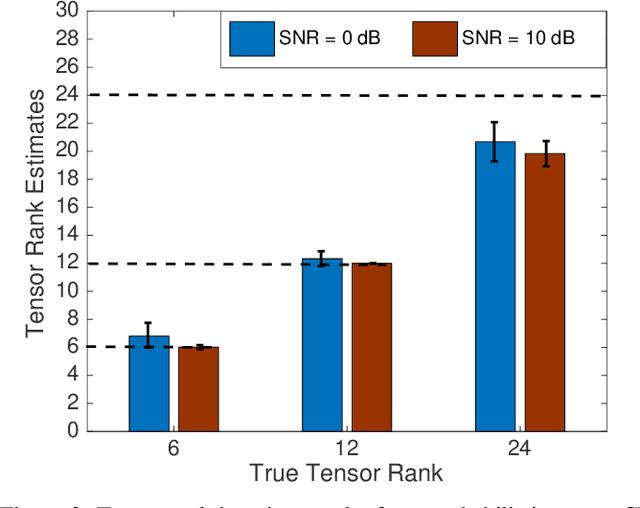
Tensor rank learning for canonical polyadic decomposition (CPD) has long been deemed as an essential but challenging problem. In particular, since the tensor rank controls the complexity of the CPD model, its inaccurate learning would cause overfitting to noise or underfitting to the signal sources, and even destroy the interpretability of model parameters. However, the optimal determination of a tensor rank is known to be a non-deterministic polynomial-time hard (NP-hard) task. Rather than exhaustively searching for the best tensor rank via trial-and-error experiments, Bayesian inference under the Gaussian-gamma prior was introduced in the context of probabilistic CPD modeling and it was shown to be an effective strategy for automatic tensor rank determination. This triggered flourishing research on other structured tensor CPDs with automatic tensor rank learning. As the other side of the coin, these research works also reveal that the Gaussian-gamma model does not perform well for high-rank tensors or/and low signal-to-noise ratios (SNRs). To overcome these drawbacks, in this paper, we introduce a more advanced generalized hyperbolic (GH) prior to the probabilistic CPD model, which not only includes the Gaussian-gamma model as a special case, but also provides more flexibilities to adapt to different levels of sparsity. Based on this novel probabilistic model, an algorithm is developed under the framework of variational inference, where each update is obtained in a closed-form. Extensive numerical results, using synthetic data and real-world datasets, demonstrate the excellent performance of the proposed method in learning both low as well as high tensor ranks even for low SNR cases.