 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScratchpad Patching: Decoupling Compute from Patch Size in Byte-Level Language Models
May 10, 2026Tokenizer-free language models eliminate the tokenizer step of the language modeling pipeline by operating directly on bytes; patch-based variants further aggregate contiguous byte spans into patches for efficiency. However, the average patch size chosen at the model design stage governs a tight trade-off: larger patches reduce compute and KV-cache footprint, but degrade modeling quality. We trace this trade-off to patch lag: until a patch is fully observed, byte predictions within it must rely on a stale representation from the previous patch to preserve causality; this lag widens as patches grow larger. We introduce Scratchpad Patching (SP), which inserts transient scratchpads inside each patch to aggregate the bytes seen so far and refresh patch-level context for subsequent predictions. SP triggers scratchpads using next-byte prediction entropy, selectively allocating compute to information-dense regions and enabling post-hoc adjustment of inference-time compute. Across experiments on natural language and code, SP improves model quality at the same patch size; for example, even at $16$ bytes per patch, SP-augmented models match or closely approach the byte-level baseline on downstream evaluations while using a $16\times$ smaller KV cache over patches and $3$-$4\times$ less inference compute.
Proxy Compression for Language Modeling
Feb 04, 2026Modern language models are trained almost exclusively on token sequences produced by a fixed tokenizer, an external lossless compressor often over UTF-8 byte sequences, thereby coupling the model to that compressor. This work introduces proxy compression, an alternative training scheme that preserves the efficiency benefits of compressed inputs while providing an end-to-end, raw-byte interface at inference time. During training, one language model is jointly trained on raw byte sequences and compressed views generated by external compressors; through the process, the model learns to internally align compressed sequences and raw bytes. This alignment enables strong transfer between the two formats, even when training predominantly on compressed inputs which are discarded at inference. Extensive experiments on code language modeling demonstrate that proxy compression substantially improves training efficiency and significantly outperforms pure byte-level baselines given fixed compute budgets. As model scale increases, these gains become more pronounced, and proxy-trained models eventually match or rival tokenizer approaches, all while operating solely on raw bytes and retaining the inherent robustness of byte-level modeling.
DreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
Transform and Entropy Coding in AV2
Jan 06, 2026AV2 is the successor to the AV1 royalty-free video coding standard developed by the Alliance for Open Media (AOMedia). Its primary objective is to deliver substantial compression gains and subjective quality improvements while maintaining low-complexity encoder and decoder operations. This paper describes the transform, quantization and entropy coding design in AV2, including redesigned transform kernels and data-driven transforms, expanded transform partitioning, and a mode & coefficient dependent transform signaling. AV2 introduces several new coding tools including Intra/Inter Secondary Transforms (IST), Trellis Coded Quantization (TCQ), Adaptive Transform Coding (ATC), Probability Adaptation Rate Adjustment (PARA), Forward Skip Coding (FSC), Cross Chroma Component Transforms (CCTX), Parity Hiding (PH) tools and improved lossless coding. These advances enable AV2 to deliver the highest quality video experience for video applications at a significantly reduced bitrate.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Oct 23, 2024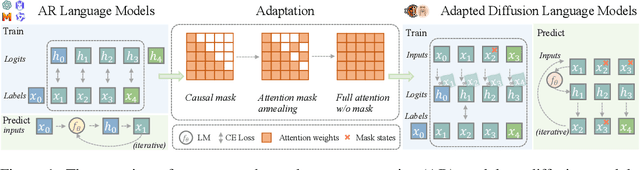
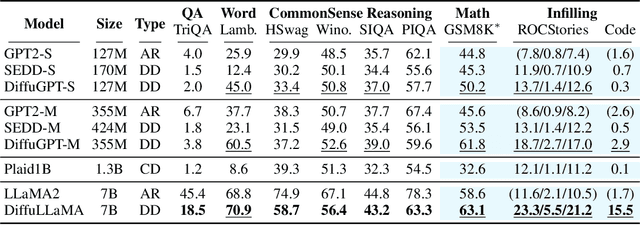
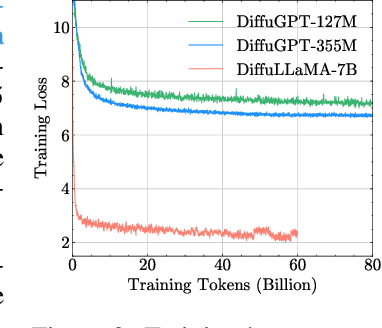
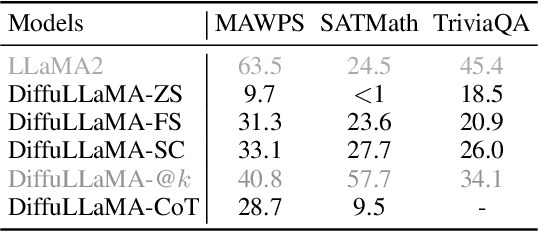
Diffusion Language Models (DLMs) have emerged as a promising new paradigm for text generative modeling, potentially addressing limitations of autoregressive (AR) models. However, current DLMs have been studied at a smaller scale compared to their AR counterparts and lack fair comparison on language modeling benchmarks. Additionally, training diffusion models from scratch at scale remains challenging. Given the prevalence of open-source AR language models, we propose adapting these models to build text diffusion models. We demonstrate connections between AR and diffusion modeling objectives and introduce a simple continual pre-training approach for training diffusion models. Through systematic evaluation on language modeling, reasoning, and commonsense benchmarks, we show that we can convert AR models ranging from 127M to 7B parameters (GPT2 and LLaMA) into diffusion models DiffuGPT and DiffuLLaMA, using less than 200B tokens for training. Our experimental results reveal that these models outperform earlier DLMs and are competitive with their AR counterparts. We release a suite of DLMs (with 127M, 355M, and 7B parameters) capable of generating fluent text, performing in-context learning, filling in the middle without prompt re-ordering, and following instructions \url{https://github.com/HKUNLP/DiffuLLaMA}.
Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning
Oct 18, 2024



Autoregressive language models, despite their impressive capabilities, struggle with complex reasoning and long-term planning tasks. We introduce discrete diffusion models as a novel solution to these challenges. Through the lens of subgoal imbalance, we demonstrate how diffusion models effectively learn difficult subgoals that elude autoregressive approaches. We propose Multi-granularity Diffusion Modeling (MDM), which prioritizes subgoals based on difficulty during learning. On complex tasks like Countdown, Sudoku, and Boolean Satisfiability Problems, MDM significantly outperforms autoregressive models without using search techniques. For instance, MDM achieves 91.5\% and 100\% accuracy on Countdown and Sudoku, respectively, compared to 45.8\% and 20.7\% for autoregressive models. Our work highlights the potential of diffusion-based approaches in advancing AI capabilities for sophisticated language understanding and problem-solving tasks.
SubgoalXL: Subgoal-based Expert Learning for Theorem Proving
Aug 20, 2024



Formal theorem proving, a field at the intersection of mathematics and computer science, has seen renewed interest with advancements in large language models (LLMs). This paper introduces SubgoalXL, a novel approach that synergizes subgoal-based proofs with expert learning to enhance LLMs' capabilities in formal theorem proving within the Isabelle environment. SubgoalXL addresses two critical challenges: the scarcity of specialized mathematics and theorem-proving data, and the need for improved multi-step reasoning abilities in LLMs. By optimizing data efficiency and employing subgoal-level supervision, SubgoalXL extracts richer information from limited human-generated proofs. The framework integrates subgoal-oriented proof strategies with an expert learning system, iteratively refining formal statement, proof, and subgoal generators. Leveraging the Isabelle environment's advantages in subgoal-based proofs, SubgoalXL achieves a new state-of-the-art performance of 56.1\% in Isabelle on the standard miniF2F dataset, marking an absolute improvement of 4.9\%. Notably, SubgoalXL successfully solves 41 AMC12, 9 AIME, and 3 IMO problems from miniF2F. These results underscore the effectiveness of maximizing limited data utility and employing targeted guidance for complex reasoning in formal theorem proving, contributing to the ongoing advancement of AI reasoning capabilities. The implementation is available at \url{https://github.com/zhaoxlpku/SubgoalXL}.
Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models
Feb 12, 2024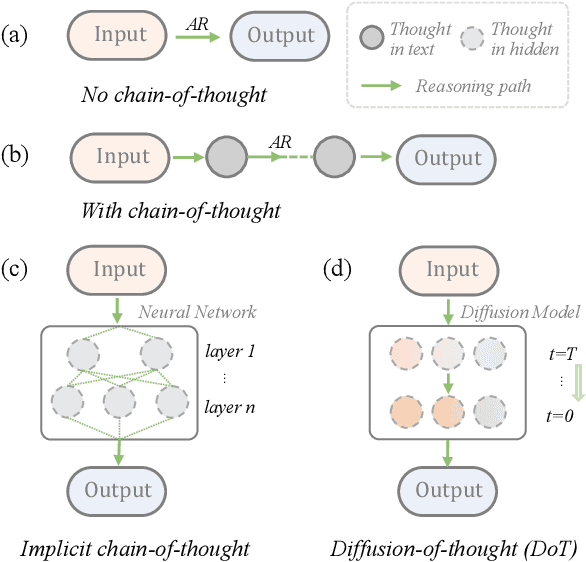
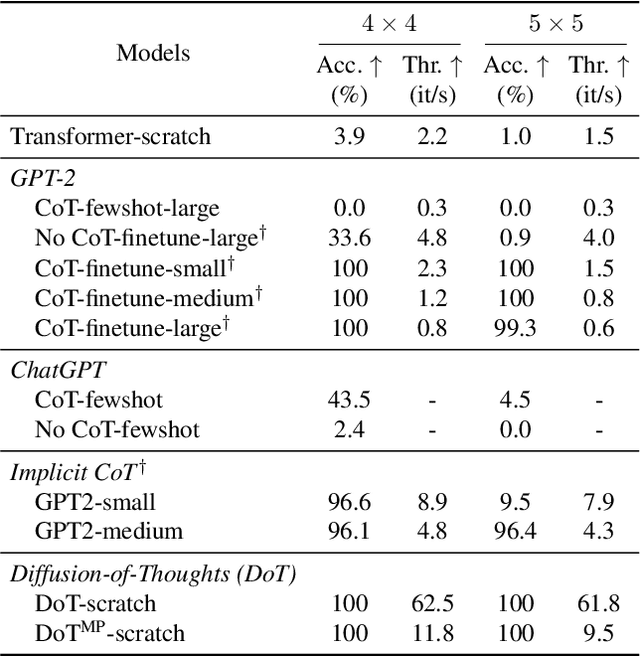
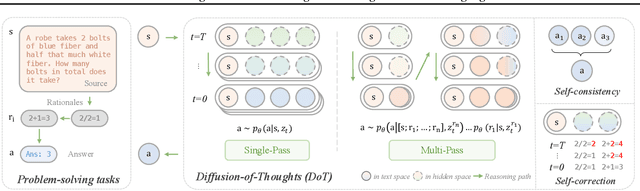
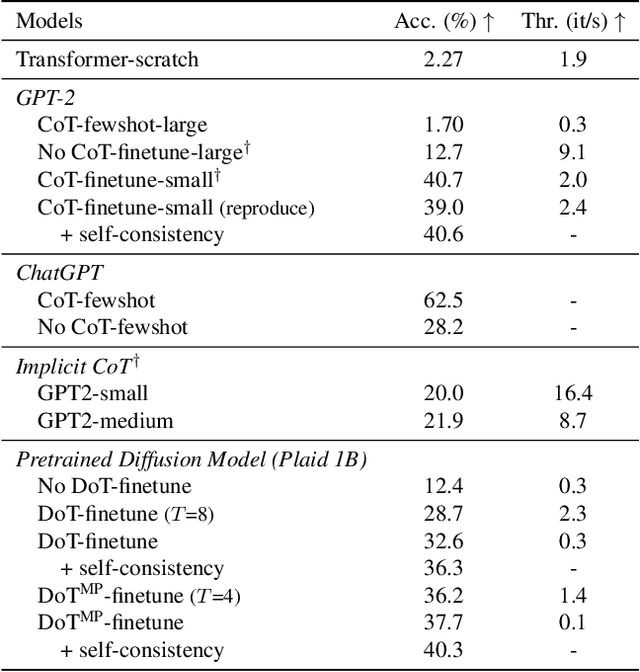
Diffusion models have gained attention in text processing, offering many potential advantages over traditional autoregressive models. This work explores the integration of diffusion models and Chain-of-Thought (CoT), a well-established technique to improve the reasoning ability in autoregressive language models. We propose Diffusion-of-Thought (DoT), allowing reasoning steps to diffuse over time through the diffusion process. In contrast to traditional autoregressive language models that make decisions in a left-to-right, token-by-token manner, DoT offers more flexibility in the trade-off between computation and reasoning performance. Our experimental results demonstrate the effectiveness of DoT in multi-digit multiplication and grade school math problems. Additionally, DoT showcases promising self-correction abilities and benefits from existing reasoning-enhancing techniques like self-consistency decoding. Our findings contribute to the understanding and development of reasoning capabilities in diffusion language models.