 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone
Dec 27, 2025While autoregressive Large Vision-Language Models (VLMs) have achieved remarkable success, their sequential generation often limits their efficacy in complex visual planning and dynamic robotic control. In this work, we investigate the potential of constructing Vision-Language Models upon diffusion-based large language models (dLLMs) to overcome these limitations. We introduce Dream-VL, an open diffusion-based VLM (dVLM) that achieves state-of-the-art performance among previous dVLMs. Dream-VL is comparable to top-tier AR-based VLMs trained on open data on various benchmarks but exhibits superior potential when applied to visual planning tasks. Building upon Dream-VL, we introduce Dream-VLA, a dLLM-based Vision-Language-Action model (dVLA) developed through continuous pre-training on open robotic datasets. We demonstrate that the natively bidirectional nature of this diffusion backbone serves as a superior foundation for VLA tasks, inherently suited for action chunking and parallel generation, leading to significantly faster convergence in downstream fine-tuning. Dream-VLA achieves top-tier performance of 97.2% average success rate on LIBERO, 71.4% overall average on SimplerEnv-Bridge, and 60.5% overall average on SimplerEnv-Fractal, surpassing leading models such as $π_0$ and GR00T-N1. We also validate that dVLMs surpass AR baselines on downstream tasks across different training objectives. We release both Dream-VL and Dream-VLA to facilitate further research in the community.
Implicit Search via Discrete Diffusion: A Study on Chess
Feb 27, 2025In the post-AlphaGo era, there has been a renewed interest in search techniques such as Monte Carlo Tree Search (MCTS), particularly in their application to Large Language Models (LLMs). This renewed attention is driven by the recognition that current next-token prediction models often lack the ability for long-term planning. Is it possible to instill search-like abilities within the models to enhance their planning abilities without relying on explicit search? We propose DiffuSearch , a model that does \textit{implicit search} by looking into the future world via discrete diffusion modeling. We instantiate DiffuSearch on a classical board game, Chess, where explicit search is known to be essential. Through extensive controlled experiments, we show DiffuSearch outperforms both the searchless and explicit search-enhanced policies. Specifically, DiffuSearch outperforms the one-step policy by 19.2% and the MCTS-enhanced policy by 14% on action accuracy. Furthermore, DiffuSearch demonstrates a notable 30% enhancement in puzzle-solving abilities compared to explicit search-based policies, along with a significant 540 Elo increase in game-playing strength assessment. These results indicate that implicit search via discrete diffusion is a viable alternative to explicit search over a one-step policy. All codes are publicly available at \href{https://github.com/HKUNLP/DiffuSearch}{https://github.com/HKUNLP/DiffuSearch}.
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Oct 23, 2024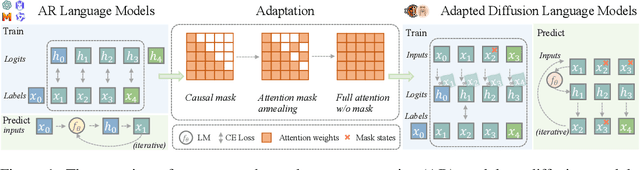
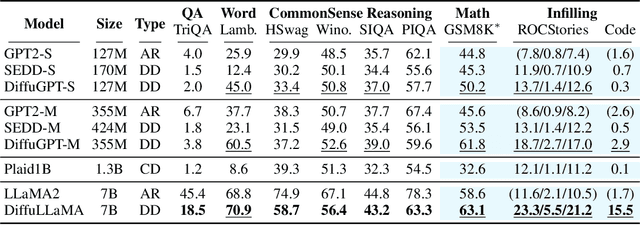
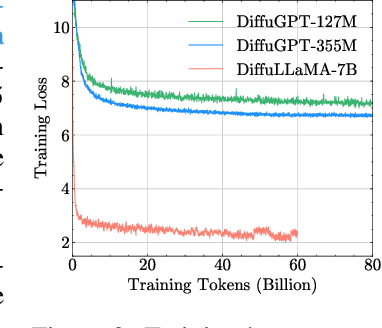
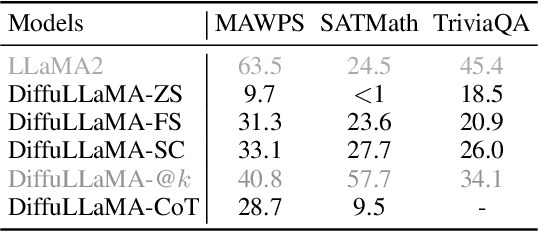
Diffusion Language Models (DLMs) have emerged as a promising new paradigm for text generative modeling, potentially addressing limitations of autoregressive (AR) models. However, current DLMs have been studied at a smaller scale compared to their AR counterparts and lack fair comparison on language modeling benchmarks. Additionally, training diffusion models from scratch at scale remains challenging. Given the prevalence of open-source AR language models, we propose adapting these models to build text diffusion models. We demonstrate connections between AR and diffusion modeling objectives and introduce a simple continual pre-training approach for training diffusion models. Through systematic evaluation on language modeling, reasoning, and commonsense benchmarks, we show that we can convert AR models ranging from 127M to 7B parameters (GPT2 and LLaMA) into diffusion models DiffuGPT and DiffuLLaMA, using less than 200B tokens for training. Our experimental results reveal that these models outperform earlier DLMs and are competitive with their AR counterparts. We release a suite of DLMs (with 127M, 355M, and 7B parameters) capable of generating fluent text, performing in-context learning, filling in the middle without prompt re-ordering, and following instructions \url{https://github.com/HKUNLP/DiffuLLaMA}.
Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning
Oct 18, 2024



Autoregressive language models, despite their impressive capabilities, struggle with complex reasoning and long-term planning tasks. We introduce discrete diffusion models as a novel solution to these challenges. Through the lens of subgoal imbalance, we demonstrate how diffusion models effectively learn difficult subgoals that elude autoregressive approaches. We propose Multi-granularity Diffusion Modeling (MDM), which prioritizes subgoals based on difficulty during learning. On complex tasks like Countdown, Sudoku, and Boolean Satisfiability Problems, MDM significantly outperforms autoregressive models without using search techniques. For instance, MDM achieves 91.5\% and 100\% accuracy on Countdown and Sudoku, respectively, compared to 45.8\% and 20.7\% for autoregressive models. Our work highlights the potential of diffusion-based approaches in advancing AI capabilities for sophisticated language understanding and problem-solving tasks.
PRoLoRA: Partial Rotation Empowers More Parameter-Efficient LoRA
Feb 24, 2024



With the rapid scaling of large language models (LLMs), serving numerous LoRAs concurrently has become increasingly impractical, leading to unaffordable costs and necessitating more parameter-efficient finetuning methods. In this work, we introduce Partially Rotation-enhanced Low-Rank Adaptation (PRoLoRA), an intra-layer sharing mechanism comprising four essential components: broadcast reduction, rotation enhancement, partially-sharing refinement, and rectified initialization strategy. As a superset of LoRA, PRoLoRA pertains its advantages, and effectively circumvent the drawbacks of peer parameter-sharing methods with superior model capacity, practical feasibility, and broad applicability. Empirical experiments demonstrate the remarkably higher parameter efficiency of PRoLoRA in both specific parameter budget and performance target scenarios, and its scalability to larger LLMs. Notably, with one time less trainable parameters, PRoLoRA still outperforms LoRA on multiple instruction tuning datasets. Subsequently, an ablation study is conducted to validate the necessity of individual components and highlight the superiority of PRoLoRA over three potential variants. Hopefully, the conspicuously higher parameter efficiency can establish PRoLoRA as a resource-friendly alternative to LoRA.
Diffusion of Thoughts: Chain-of-Thought Reasoning in Diffusion Language Models
Feb 12, 2024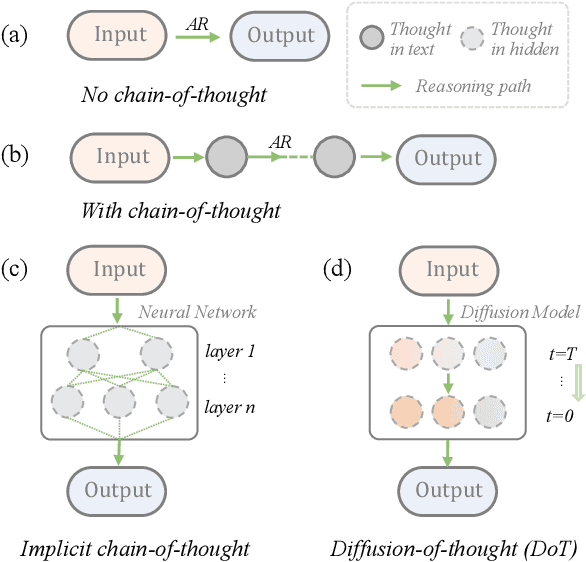
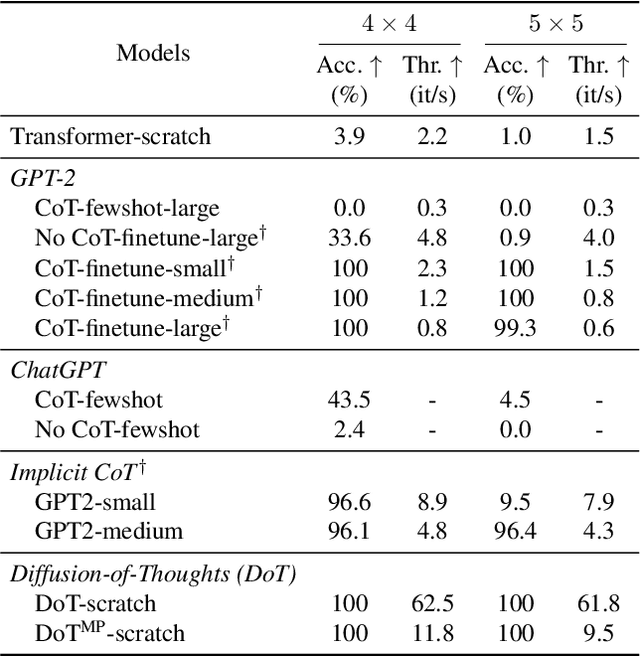
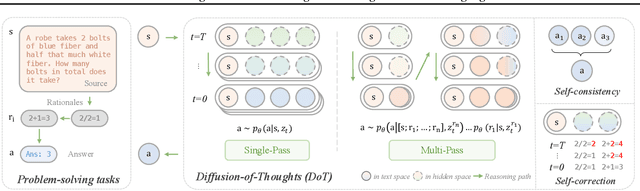
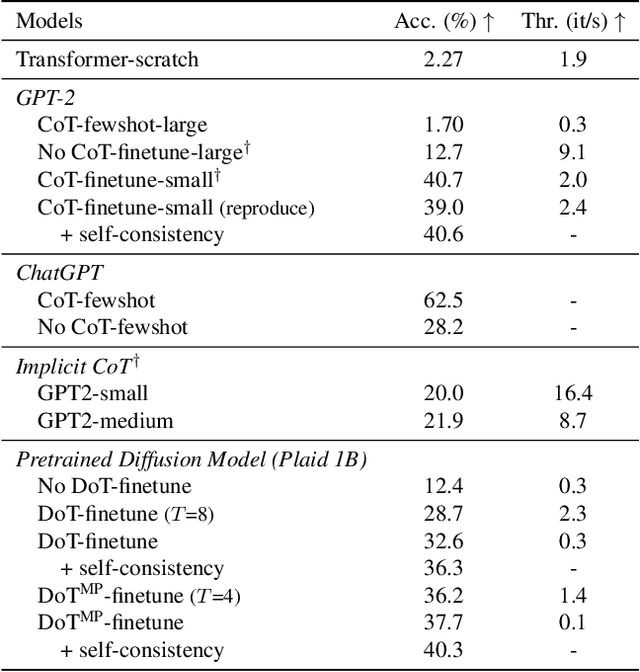
Diffusion models have gained attention in text processing, offering many potential advantages over traditional autoregressive models. This work explores the integration of diffusion models and Chain-of-Thought (CoT), a well-established technique to improve the reasoning ability in autoregressive language models. We propose Diffusion-of-Thought (DoT), allowing reasoning steps to diffuse over time through the diffusion process. In contrast to traditional autoregressive language models that make decisions in a left-to-right, token-by-token manner, DoT offers more flexibility in the trade-off between computation and reasoning performance. Our experimental results demonstrate the effectiveness of DoT in multi-digit multiplication and grade school math problems. Additionally, DoT showcases promising self-correction abilities and benefits from existing reasoning-enhancing techniques like self-consistency decoding. Our findings contribute to the understanding and development of reasoning capabilities in diffusion language models.
G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model
Dec 18, 2023

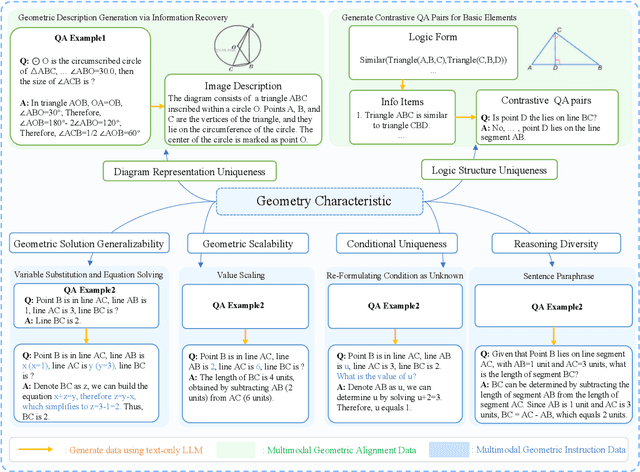
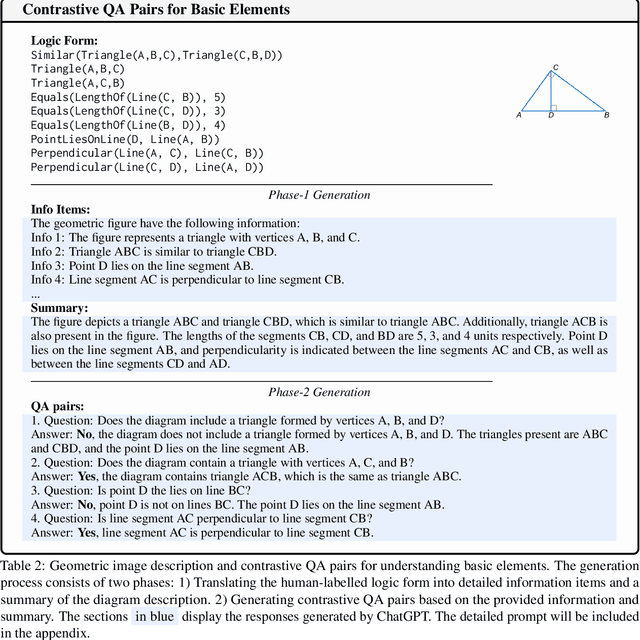
Large language models (LLMs) have shown remarkable proficiency in human-level reasoning and generation capabilities, which encourages extensive research on their application in mathematical problem solving. However, current work has been largely focused on text-based mathematical problems, with limited investigation in problems involving geometric information. Addressing this gap, we aim to enable LLMs to solve geometric problems by understanding image input. We first analyze the limitations of current Multimodal Large Language Models (MLLMs) in this area: they struggle to accurately comprehending basic geometric elements and their relationships. To overcome these challenges, we take advantage of the unique characteristics of geometric problems (such as unique geometric logical form, and geometric scalability) and the capacity of the textual LLMs to build an enriched multimodal geometry dataset based on existing data. The augmented dataset, Geo170K, contains more than 170K geometric image-caption and question-answer pairs. Utilizing our constructed Geo170K dataset, we develop G-LLaVA, which demonstrates exceptional performance in solving geometric problems, significantly outperforming GPT-4-V on the MathVista benchmark with only 7B parameters.
Language Versatilists vs. Specialists: An Empirical Revisiting on Multilingual Transfer Ability
Jun 11, 2023



Multilingual transfer ability, which reflects how well the models fine-tuned on one source language can be applied to other languages, has been well studied in multilingual pre-trained models (e.g., BLOOM). However, such ability has not been investigated for English-centric models (e.g., LLaMA). To fill this gap, we study the following research questions. First, does multilingual transfer ability exist in English-centric models and how does it compare with multilingual pretrained models? Second, does it only appears when English is the source language for the English-centric model? Third, how does it vary in different tasks? We take multilingual reasoning ability as our focus and conduct extensive experiments across four types of reasoning tasks. We find that the multilingual pretrained model does not always outperform an English-centric model. Furthermore, English appears to be a less suitable source language, and the choice of source language becomes less important when the English-centric model scales up. In addition, different types of tasks exhibit different multilingual transfer abilities. These findings demonstrate that English-centric models not only possess multilingual transfer ability but may even surpass the transferability of multilingual pretrained models if well-trained. By showing the strength and weaknesses, the experiments also provide valuable insights into enhancing multilingual reasoning abilities for the English-centric models.
Generating Data for Symbolic Language with Large Language Models
May 23, 2023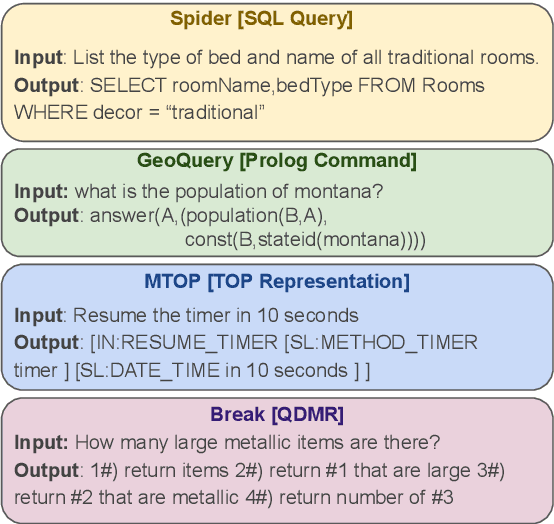


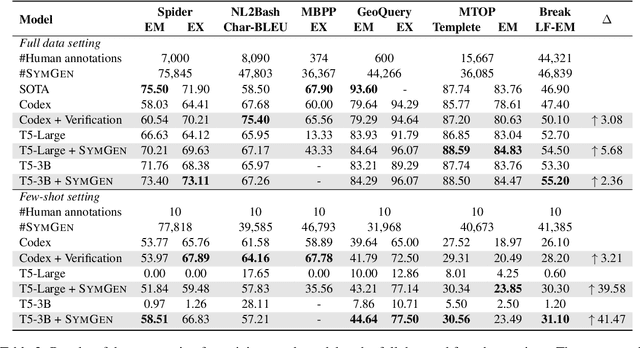
While large language models (LLMs) bring not only performance but also complexity, recent work has started to turn LLMs into data generators rather than task inferencers, where another affordable task model is trained for efficient deployment and inference. However, such an approach has primarily been applied to natural language tasks and has not yet been explored for symbolic language tasks with complex structured outputs (e.g., semantic parsing and code generation). In this paper, we propose SymGen which utilizes LLMs for generating various annotation-expensive symbolic language data. SymGen consists of an informative prompt to steer generation and an agreement-based verifier to improve data correctness. We conduct extensive experiments on six symbolic language tasks across various settings. Compared with the LLMs, we demonstrate the 1\%-sized task model can achieve comparable or better performance, largely cutting inference and deployment costs. We also show that generated data with only a few human demonstrations can be as effective as over 10 times the amount of human-annotated data when training the task model, saving a considerable amount of annotation effort. SymGen sheds new light on data generation for complex tasks, and we release the code at \href{https://github.com/HKUNLP/SymGen}{https://github.com/HKUNLP/SymGen}.