 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning
May 21, 2025
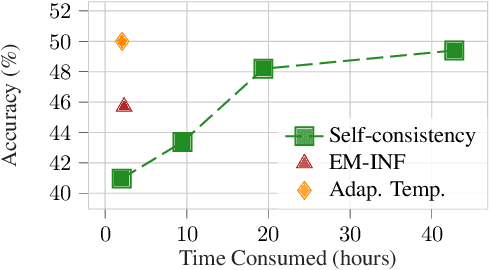
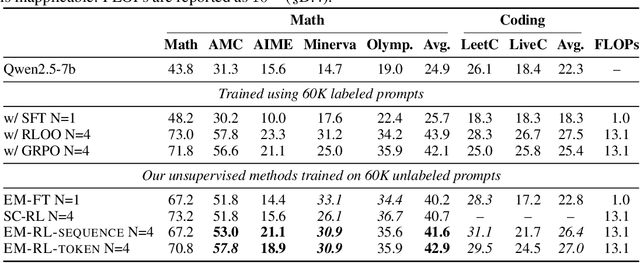
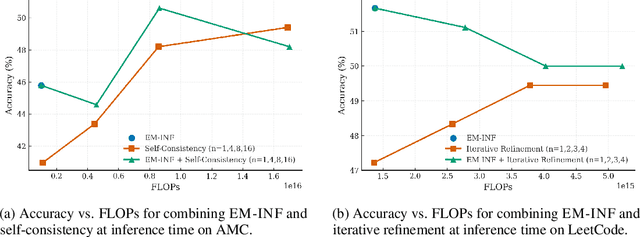
Entropy minimization (EM) trains the model to concentrate even more probability mass on its most confident outputs. We show that this simple objective alone, without any labeled data, can substantially improve large language models' (LLMs) performance on challenging math, physics, and coding tasks. We explore three approaches: (1) EM-FT minimizes token-level entropy similarly to instruction finetuning, but on unlabeled outputs drawn from the model; (2) EM-RL: reinforcement learning with negative entropy as the only reward to maximize; (3) EM-INF: inference-time logit adjustment to reduce entropy without any training data or parameter updates. On Qwen-7B, EM-RL, without any labeled data, achieves comparable or better performance than strong RL baselines such as GRPO and RLOO that are trained on 60K labeled examples. Furthermore, EM-INF enables Qwen-32B to match or exceed the performance of proprietary models like GPT-4o, Claude 3 Opus, and Gemini 1.5 Pro on the challenging SciCode benchmark, while being 3x more efficient than self-consistency and sequential refinement. Our findings reveal that many pretrained LLMs possess previously underappreciated reasoning capabilities that can be effectively elicited through entropy minimization alone, without any labeled data or even any parameter updates.
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Oct 23, 2024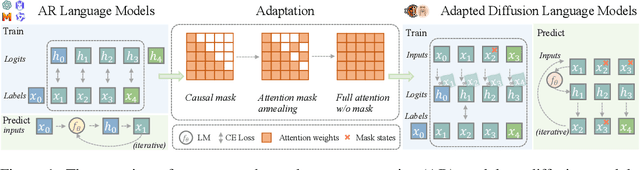
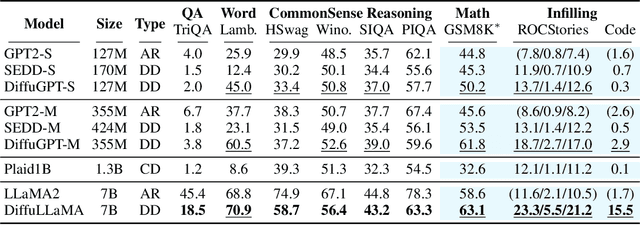
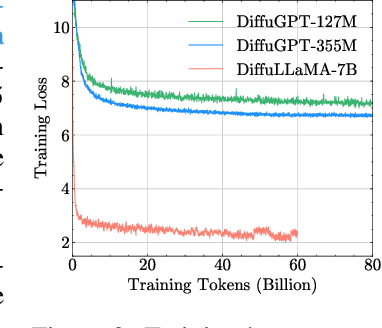
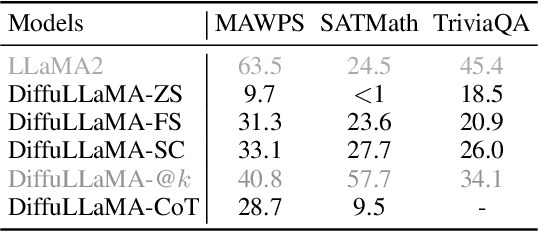
Diffusion Language Models (DLMs) have emerged as a promising new paradigm for text generative modeling, potentially addressing limitations of autoregressive (AR) models. However, current DLMs have been studied at a smaller scale compared to their AR counterparts and lack fair comparison on language modeling benchmarks. Additionally, training diffusion models from scratch at scale remains challenging. Given the prevalence of open-source AR language models, we propose adapting these models to build text diffusion models. We demonstrate connections between AR and diffusion modeling objectives and introduce a simple continual pre-training approach for training diffusion models. Through systematic evaluation on language modeling, reasoning, and commonsense benchmarks, we show that we can convert AR models ranging from 127M to 7B parameters (GPT2 and LLaMA) into diffusion models DiffuGPT and DiffuLLaMA, using less than 200B tokens for training. Our experimental results reveal that these models outperform earlier DLMs and are competitive with their AR counterparts. We release a suite of DLMs (with 127M, 355M, and 7B parameters) capable of generating fluent text, performing in-context learning, filling in the middle without prompt re-ordering, and following instructions \url{https://github.com/HKUNLP/DiffuLLaMA}.
Improving Retrieval in Theme-specific Applications using a Corpus Topical Taxonomy
Mar 07, 2024Document retrieval has greatly benefited from the advancements of large-scale pre-trained language models (PLMs). However, their effectiveness is often limited in theme-specific applications for specialized areas or industries, due to unique terminologies, incomplete contexts of user queries, and specialized search intents. To capture the theme-specific information and improve retrieval, we propose to use a corpus topical taxonomy, which outlines the latent topic structure of the corpus while reflecting user-interested aspects. We introduce ToTER (Topical Taxonomy Enhanced Retrieval) framework, which identifies the central topics of queries and documents with the guidance of the taxonomy, and exploits their topical relatedness to supplement missing contexts. As a plug-and-play framework, ToTER can be flexibly employed to enhance various PLM-based retrievers. Through extensive quantitative, ablative, and exploratory experiments on two real-world datasets, we ascertain the benefits of using topical taxonomy for retrieval in theme-specific applications and demonstrate the effectiveness of ToTER.
Text-Augmented Open Knowledge Graph Completion via Pre-Trained Language Models
May 24, 2023



The mission of open knowledge graph (KG) completion is to draw new findings from known facts. Existing works that augment KG completion require either (1) factual triples to enlarge the graph reasoning space or (2) manually designed prompts to extract knowledge from a pre-trained language model (PLM), exhibiting limited performance and requiring expensive efforts from experts. To this end, we propose TAGREAL that automatically generates quality query prompts and retrieves support information from large text corpora to probe knowledge from PLM for KG completion. The results show that TAGREAL achieves state-of-the-art performance on two benchmark datasets. We find that TAGREAL has superb performance even with limited training data, outperforming existing embedding-based, graph-based, and PLM-based methods.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021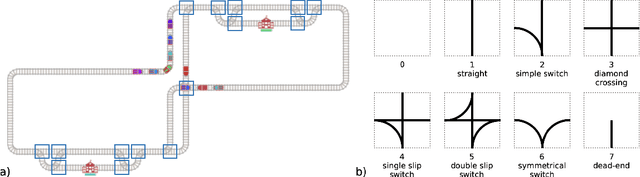
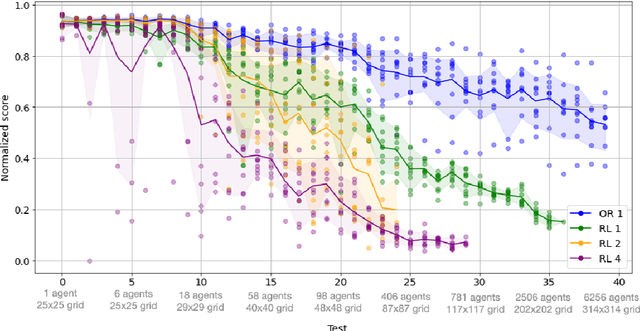
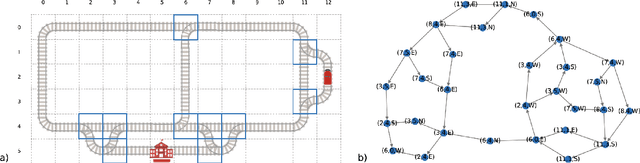
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
S++: A Fast and Deployable Secure-Computation Framework for Privacy-Preserving Neural Network Training
Jan 28, 2021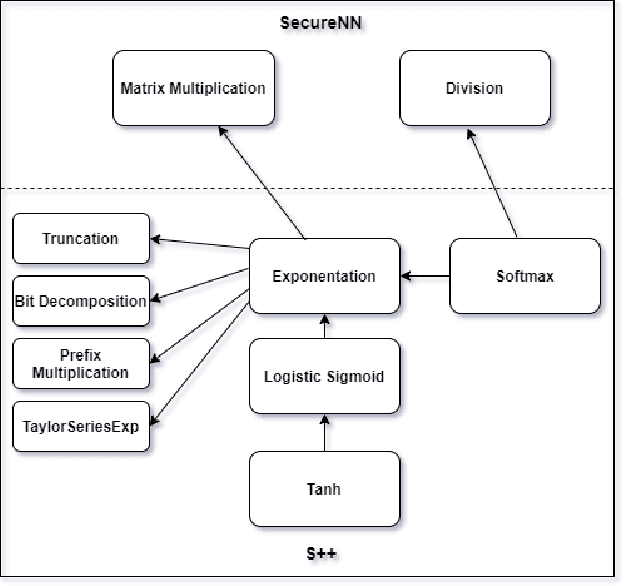
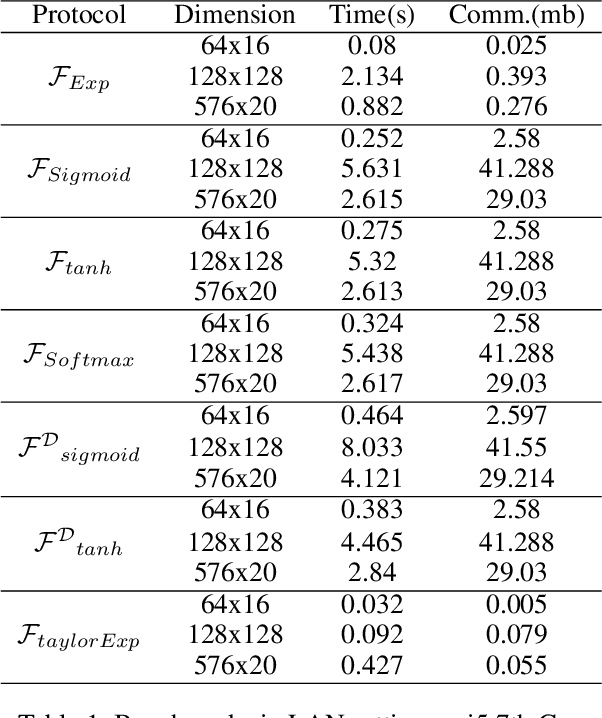
We introduce S++, a simple, robust, and deployable framework for training a neural network (NN) using private data from multiple sources, using secret-shared secure function evaluation. In short, consider a virtual third party to whom every data-holder sends their inputs, and which computes the neural network: in our case, this virtual third party is actually a set of servers which individually learn nothing, even with a malicious (but non-colluding) adversary. Previous work in this area has been limited to just one specific activation function: ReLU, rendering the approach impractical for many use-cases. For the first time, we provide fast and verifiable protocols for all common activation functions and optimize them for running in a secret-shared manner. The ability to quickly, verifiably, and robustly compute exponentiation, softmax, sigmoid, etc., allows us to use previously written NNs without modification, vastly reducing developer effort and complexity of code. In recent times, ReLU has been found to converge much faster and be more computationally efficient as compared to non-linear functions like sigmoid or tanh. However, we argue that it would be remiss not to extend the mechanism to non-linear functions such as the logistic sigmoid, tanh, and softmax that are fundamental due to their ability to express outputs as probabilities and their universal approximation property. Their contribution in RNNs and a few recent advancements also makes them more relevant.