 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Order Matter : Connecting The Law of Robustness to Robust Generalization
Feb 25, 2026Bubeck and Sellke (2021) pose as an open problem the connection between the law of robustness and robust generalization. The law of robustness states that overparameterization is necessary for models to interpolate robustly; in particular, robust interpolation requires the learned function to be Lipschitz. Robust generalization asks whether small robust training loss implies small robust test loss. We resolve this problem by explicitly connecting the two for arbitrary data distributions. Specifically, we introduce a nontrivial notion of robust generalization error and convert it into a lower bound on the expected Rademacher complexity of the induced robust loss class. Our bounds recover the $Ω(n^{1/d})$ regime of Wu et al. (2023) and show that, up to constants, robust generalization does not change the order of the Lipschitz constant required for smooth interpolation. We conduct experiments to probe the predicted scaling with dataset size and model capacity, testing whether empirical behavior aligns more closely with the predictions of Bubeck and Sellke (2021) or Wu et al. (2023). For MNIST, we find that the lower-bound Lipschitz constant scales on the order predicted by Wu et al. (2023). Informally, to obtain low robust generalization error, the Lipschitz constant must lie in a range that we bound, and the allowable perturbation radius is linked to the Lipschitz scale.
Physics Aware Neural Networks: Denoising for Magnetic Navigation
Feb 14, 2026Magnetic-anomaly navigation, leveraging small-scale variations in the Earth's magnetic field, is a promising alternative when GPS is unavailable or compromised. Airborne systems face a key challenge in extracting geomagnetic field data: the aircraft itself induces magnetic noise. Although the classical Tolles-Lawson model addresses this, it inadequately handles stochastically corrupted magnetic data required for navigation. To address stochastic noise, we propose a framework based on two physics-based constraints: divergence-free vector field and E(3)-equivariance. These ensure the learned magnetic field obeys Maxwell's equations and that outputs transform correctly with sensor position/orientation. The divergence-free constraint is implemented by training a neural network to output a vector potential $A$, with the magnetic field defined as its curl. For E(3)-equivariance, we use tensor products of geometric tensors representable via spherical harmonics with known rotational transformations. Enforcing physical consistency and restricting the admissible function space acts as an implicit regularizer that improves spatio-temporal performance. We present ablation studies evaluating each constraint alone and jointly across CNNs, MLPs, Liquid Time Constant models, and Contiformers. Continuous-time dynamics and long-term memory are critical for modelling magnetic time series; the Contiformer architecture, which provides both, outperforms state-of-the-art methods. To mitigate data scarcity, we generate synthetic datasets using the World Magnetic Model (WMM) with time-series conditional GANs, producing realistic, temporally consistent magnetic sequences across varied trajectories and environments. Experiments show that embedding these constraints significantly improves predictive accuracy and physical plausibility, outperforming classical and unconstrained deep learning approaches.
Oscillators Are All You Need: Irregular Time Series Modelling via Damped Harmonic Oscillators with Closed-Form Solutions
Feb 12, 2026Transformers excel at time series modelling through attention mechanisms that capture long-term temporal patterns. However, they assume uniform time intervals and therefore struggle with irregular time series. Neural Ordinary Differential Equations (NODEs) effectively handle irregular time series by modelling hidden states as continuously evolving trajectories. ContiFormers arxiv:2402.10635 combine NODEs with Transformers, but inherit the computational bottleneck of the former by using heavy numerical solvers. This bottleneck can be removed by using a closed-form solution for the given dynamical system - but this is known to be intractable in general! We obviate this by replacing NODEs with a novel linear damped harmonic oscillator analogy - which has a known closed-form solution. We model keys and values as damped, driven oscillators and expand the query in a sinusoidal basis up to a suitable number of modes. This analogy naturally captures the query-key coupling that is fundamental to any transformer architecture by modelling attention as a resonance phenomenon. Our closed-form solution eliminates the computational overhead of numerical ODE solvers while preserving expressivity. We prove that this oscillator-based parameterisation maintains the universal approximation property of continuous-time attention; specifically, any discrete attention matrix realisable by ContiFormer's continuous keys can be approximated arbitrarily well by our fixed oscillator modes. Our approach delivers both theoretical guarantees and scalability, achieving state-of-the-art performance on irregular time series benchmarks while being orders of magnitude faster.
ObjMST: An Object-Focused Multimodal Style Transfer Framework
Mar 06, 2025We propose ObjMST, an object-focused multimodal style transfer framework that provides separate style supervision for salient objects and surrounding elements while addressing alignment issues in multimodal representation learning. Existing image-text multimodal style transfer methods face the following challenges: (1) generating non-aligned and inconsistent multimodal style representations; and (2) content mismatch, where identical style patterns are applied to both salient objects and their surrounding elements. Our approach mitigates these issues by: (1) introducing a Style-Specific Masked Directional CLIP Loss, which ensures consistent and aligned style representations for both salient objects and their surroundings; and (2) incorporating a salient-to-key mapping mechanism for stylizing salient objects, followed by image harmonization to seamlessly blend the stylized objects with their environment. We validate the effectiveness of ObjMST through experiments, using both quantitative metrics and qualitative visual evaluations of the stylized outputs. Our code is available at: https://github.com/chandagrover/ObjMST.
* 8 pages, 8 Figures, 3 Tables
Improving text-conditioned latent diffusion for cancer pathology
Dec 09, 2024The development of generative models in the past decade has allowed for hyperrealistic data synthesis. While potentially beneficial, this synthetic data generation process has been relatively underexplored in cancer histopathology. One algorithm for synthesising a realistic image is diffusion; it iteratively converts an image to noise and learns the recovery process from this noise [Wang and Vastola, 2023]. While effective, it is highly computationally expensive for high-resolution images, rendering it infeasible for histopathology. The development of Variational Autoencoders (VAEs) has allowed us to learn the representation of complex high-resolution images in a latent space. A vital by-product of this is the ability to compress high-resolution images to space and recover them lossless. The marriage of diffusion and VAEs allows us to carry out diffusion in the latent space of an autoencoder, enabling us to leverage the realistic generative capabilities of diffusion while maintaining reasonable computational requirements. Rombach et al. [2021b] and Yellapragada et al. [2023] build foundational models for this task, paving the way to generate realistic histopathology images. In this paper, we discuss the pitfalls of current methods, namely [Yellapragada et al., 2023] and resolve critical errors while proposing improvements along the way. Our methods achieve an FID score of 21.11, beating its SOTA counterparts in [Yellapragada et al., 2023] by 1.2 FID, while presenting a train-time GPU memory usage reduction of 7%.
Visual Concept Networks: A Graph-Based Approach to Detecting Anomalous Data in Deep Neural Networks
Sep 26, 2024Deep neural networks (DNNs), while increasingly deployed in many applications, struggle with robustness against anomalous and out-of-distribution (OOD) data. Current OOD benchmarks often oversimplify, focusing on single-object tasks and not fully representing complex real-world anomalies. This paper introduces a new, straightforward method employing graph structures and topological features to effectively detect both far-OOD and near-OOD data. We convert images into networks of interconnected human understandable features or visual concepts. Through extensive testing on two novel tasks, including ablation studies with large vocabularies and diverse tasks, we demonstrate the method's effectiveness. This approach enhances DNN resilience to OOD data and promises improved performance in various applications.
SimSAM: Simple Siamese Representations Based Semantic Affinity Matrix for Unsupervised Image Segmentation
Jun 12, 2024



Recent developments in self-supervised learning (SSL) have made it possible to learn data representations without the need for annotations. Inspired by the non-contrastive SSL approach (SimSiam), we introduce a novel framework SIMSAM to compute the Semantic Affinity Matrix, which is significant for unsupervised image segmentation. Given an image, SIMSAM first extracts features using pre-trained DINO-ViT, then projects the features to predict the correlations of dense features in a non-contrastive way. We show applications of the Semantic Affinity Matrix in object segmentation and semantic segmentation tasks. Our code is available at https://github.com/chandagrover/SimSAM.
* 6 Pages-Main Paper , 6 figures, 6Tables (Main Paper), ICIP 2024, 8 Pages: Supplementary
Developmental Pretraining (DPT) for Image Classification Networks
Dec 01, 2023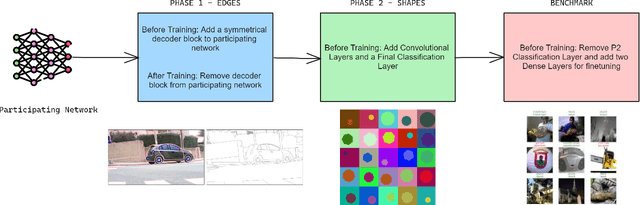
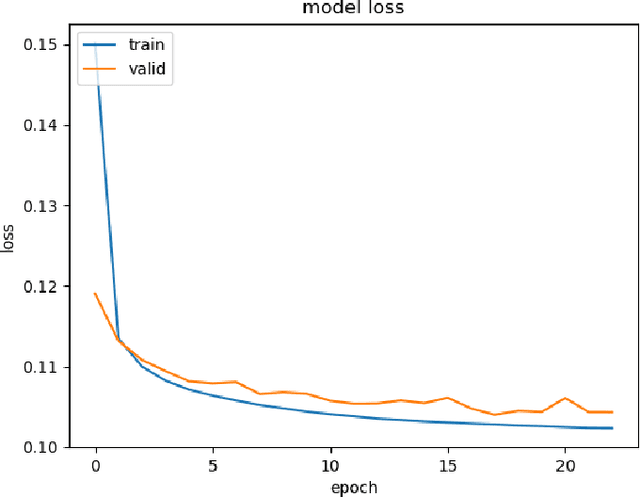
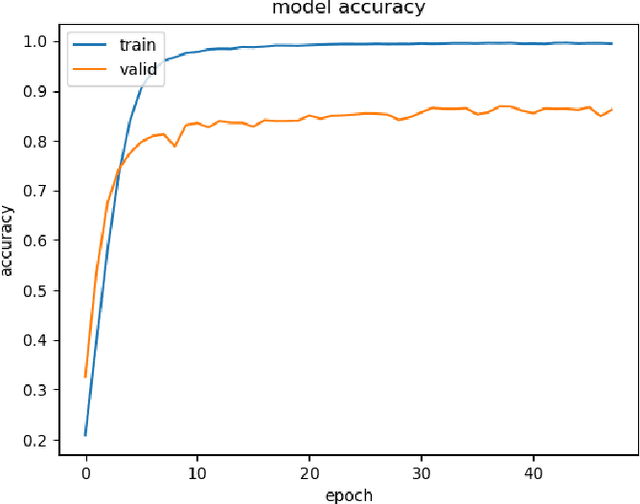
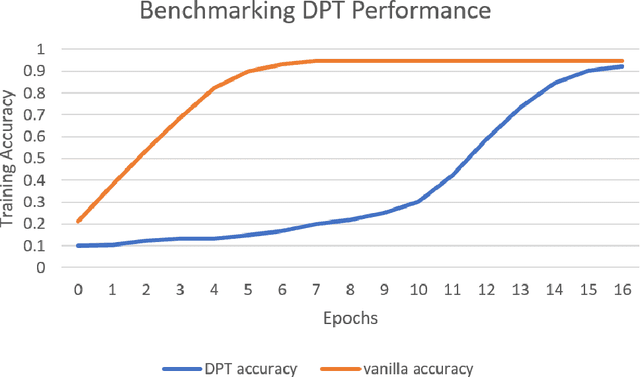
In the backdrop of increasing data requirements of Deep Neural Networks for object recognition that is growing more untenable by the day, we present Developmental PreTraining (DPT) as a possible solution. DPT is designed as a curriculum-based pre-training approach designed to rival traditional pre-training techniques that are data-hungry. These training approaches also introduce unnecessary features that could be misleading when the network is employed in a downstream classification task where the data is sufficiently different from the pre-training data and is scarce. We design the curriculum for DPT by drawing inspiration from human infant visual development. DPT employs a phased approach where carefully-selected primitive and universal features like edges and shapes are taught to the network participating in our pre-training regime. A model that underwent the DPT regime is tested against models with randomised weights to evaluate the viability of DPT.
Sem-CS: Semantic CLIPStyler for Text-Based Image Style Transfer
Jul 12, 2023
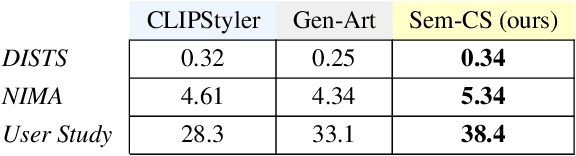
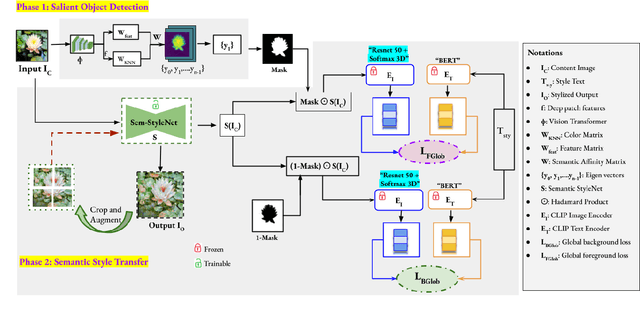
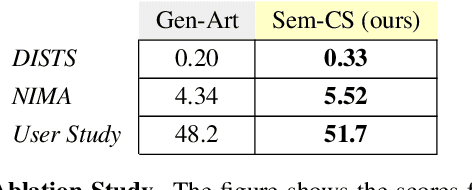
CLIPStyler demonstrated image style transfer with realistic textures using only a style text description (instead of requiring a reference style image). However, the ground semantics of objects in the style transfer output is lost due to style spill-over on salient and background objects (content mismatch) or over-stylization. To solve this, we propose Semantic CLIPStyler (Sem-CS), that performs semantic style transfer. Sem-CS first segments the content image into salient and non-salient objects and then transfers artistic style based on a given style text description. The semantic style transfer is achieved using global foreground loss (for salient objects) and global background loss (for non-salient objects). Our empirical results, including DISTS, NIMA and user study scores, show that our proposed framework yields superior qualitative and quantitative performance. Our code is available at github.com/chandagrover/sem-cs.
* 5 pages, 4 Figures, 2 Tables. arXiv admin note: substantial text overlap with arXiv:2303.06334
Synthpop++: A Hybrid Framework for Generating A Country-scale Synthetic Population
Apr 24, 2023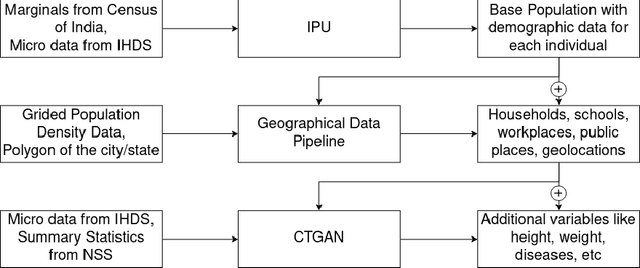
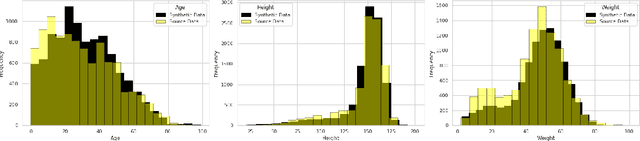
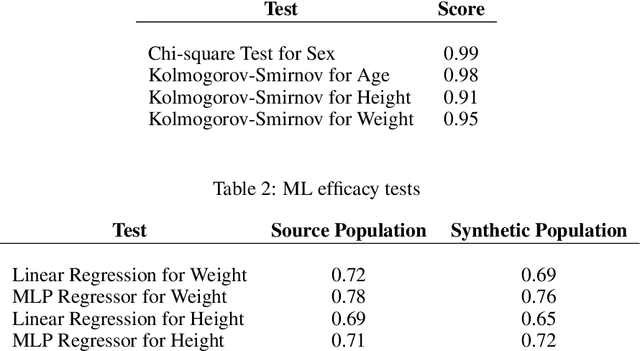
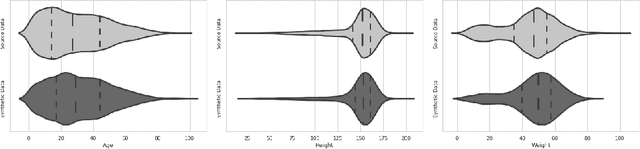
Population censuses are vital to public policy decision-making. They provide insight into human resources, demography, culture, and economic structure at local, regional, and national levels. However, such surveys are very expensive (especially for low and middle-income countries with high populations, such as India), time-consuming, and may also raise privacy concerns, depending upon the kinds of data collected. In light of these issues, we introduce SynthPop++, a novel hybrid framework, which can combine data from multiple real-world surveys (with different, partially overlapping sets of attributes) to produce a real-scale synthetic population of humans. Critically, our population maintains family structures comprising individuals with demographic, socioeconomic, health, and geolocation attributes: this means that our ``fake'' people live in realistic locations, have realistic families, etc. Such data can be used for a variety of purposes: we explore one such use case, Agent-based modelling of infectious disease in India. To gauge the quality of our synthetic population, we use both machine learning and statistical metrics. Our experimental results show that synthetic population can realistically simulate the population for various administrative units of India, producing real-scale, detailed data at the desired level of zoom -- from cities, to districts, to states, eventually combining to form a country-scale synthetic population.