 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjMST: An Object-Focused Multimodal Style Transfer Framework
Mar 06, 2025We propose ObjMST, an object-focused multimodal style transfer framework that provides separate style supervision for salient objects and surrounding elements while addressing alignment issues in multimodal representation learning. Existing image-text multimodal style transfer methods face the following challenges: (1) generating non-aligned and inconsistent multimodal style representations; and (2) content mismatch, where identical style patterns are applied to both salient objects and their surrounding elements. Our approach mitigates these issues by: (1) introducing a Style-Specific Masked Directional CLIP Loss, which ensures consistent and aligned style representations for both salient objects and their surroundings; and (2) incorporating a salient-to-key mapping mechanism for stylizing salient objects, followed by image harmonization to seamlessly blend the stylized objects with their environment. We validate the effectiveness of ObjMST through experiments, using both quantitative metrics and qualitative visual evaluations of the stylized outputs. Our code is available at: https://github.com/chandagrover/ObjMST.
* 8 pages, 8 Figures, 3 Tables
BloomCoreset: Fast Coreset Sampling using Bloom Filters for Fine-Grained Self-Supervised Learning
Dec 22, 2024



The success of deep learning in supervised fine-grained recognition for domain-specific tasks relies heavily on expert annotations. The Open-Set for fine-grained Self-Supervised Learning (SSL) problem aims to enhance performance on downstream tasks by strategically sampling a subset of images (the Core-Set) from a large pool of unlabeled data (the Open-Set). In this paper, we propose a novel method, BloomCoreset, that significantly reduces sampling time from Open-Set while preserving the quality of samples in the coreset. To achieve this, we utilize Bloom filters as an innovative hashing mechanism to store both low- and high-level features of the fine-grained dataset, as captured by Open-CLIP, in a space-efficient manner that enables rapid retrieval of the coreset from the Open-Set. To show the effectiveness of the sampled coreset, we integrate the proposed method into the state-of-the-art fine-grained SSL framework, SimCore [1]. The proposed algorithm drastically outperforms the sampling strategy of the baseline in SimCore [1] with a $98.5\%$ reduction in sampling time with a mere $0.83\%$ average trade-off in accuracy calculated across $11$ downstream datasets.
SimSAM: Simple Siamese Representations Based Semantic Affinity Matrix for Unsupervised Image Segmentation
Jun 12, 2024



Recent developments in self-supervised learning (SSL) have made it possible to learn data representations without the need for annotations. Inspired by the non-contrastive SSL approach (SimSiam), we introduce a novel framework SIMSAM to compute the Semantic Affinity Matrix, which is significant for unsupervised image segmentation. Given an image, SIMSAM first extracts features using pre-trained DINO-ViT, then projects the features to predict the correlations of dense features in a non-contrastive way. We show applications of the Semantic Affinity Matrix in object segmentation and semantic segmentation tasks. Our code is available at https://github.com/chandagrover/SimSAM.
* 6 Pages-Main Paper , 6 figures, 6Tables (Main Paper), ICIP 2024, 8 Pages: Supplementary
Sem-CS: Semantic CLIPStyler for Text-Based Image Style Transfer
Jul 12, 2023
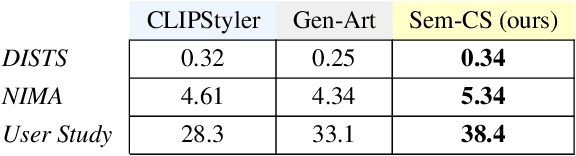
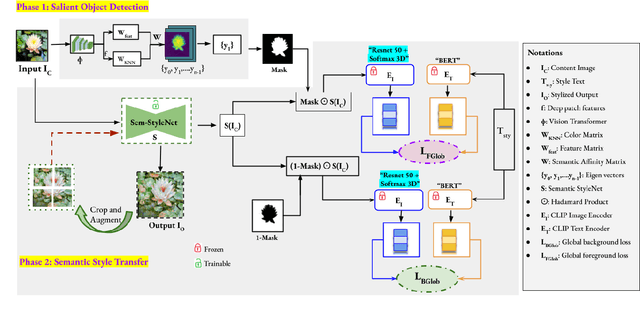
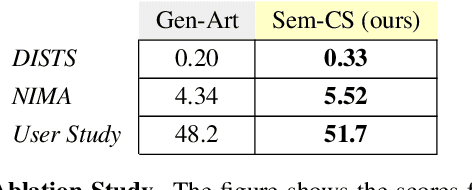
CLIPStyler demonstrated image style transfer with realistic textures using only a style text description (instead of requiring a reference style image). However, the ground semantics of objects in the style transfer output is lost due to style spill-over on salient and background objects (content mismatch) or over-stylization. To solve this, we propose Semantic CLIPStyler (Sem-CS), that performs semantic style transfer. Sem-CS first segments the content image into salient and non-salient objects and then transfers artistic style based on a given style text description. The semantic style transfer is achieved using global foreground loss (for salient objects) and global background loss (for non-salient objects). Our empirical results, including DISTS, NIMA and user study scores, show that our proposed framework yields superior qualitative and quantitative performance. Our code is available at github.com/chandagrover/sem-cs.
* 5 pages, 4 Figures, 2 Tables. arXiv admin note: substantial text overlap with arXiv:2303.06334
ContextCLIP: Contextual Alignment of Image-Text pairs on CLIP visual representations
Nov 14, 2022State-of-the-art empirical work has shown that visual representations learned by deep neural networks are robust in nature and capable of performing classification tasks on diverse datasets. For example, CLIP demonstrated zero-shot transfer performance on multiple datasets for classification tasks in a joint embedding space of image and text pairs. However, it showed negative transfer performance on standard datasets, e.g., BirdsNAP, RESISC45, and MNIST. In this paper, we propose ContextCLIP, a contextual and contrastive learning framework for the contextual alignment of image-text pairs by learning robust visual representations on Conceptual Captions dataset. Our framework was observed to improve the image-text alignment by aligning text and image representations contextually in the joint embedding space. ContextCLIP showed good qualitative performance for text-to-image retrieval tasks and enhanced classification accuracy. We evaluated our model quantitatively with zero-shot transfer and fine-tuning experiments on CIFAR-10, CIFAR-100, Birdsnap, RESISC45, and MNIST datasets for classification task.
FMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Dec 09, 2021
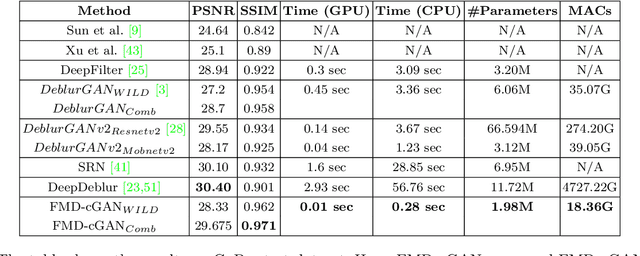


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.
DeepObjStyle: Deep Object-based Photo Style Transfer
Dec 11, 2020
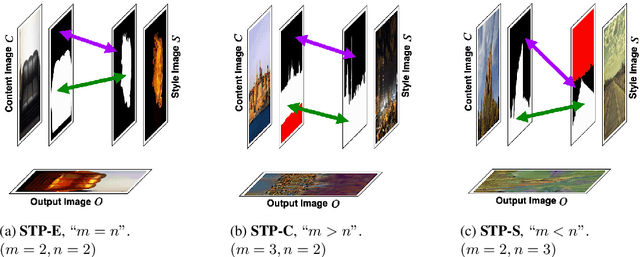


One of the major challenges of style transfer is the appropriate image features supervision between the output image and the input (style and content) images. An efficient strategy would be to define an object map between the objects of the style and the content images. However, such a mapping is not well established when there are semantic objects of different types and numbers in the style and the content images. It also leads to content mismatch in the style transfer output, which could reduce the visual quality of the results. We propose an object-based style transfer approach, called DeepObjStyle, for the style supervision in the training data-independent framework. DeepObjStyle preserves the semantics of the objects and achieves better style transfer in the challenging scenario when the style and the content images have a mismatch of image features. We also perform style transfer of images containing a word cloud to demonstrate that DeepObjStyle enables an appropriate image features supervision. We validate the results using quantitative comparisons and user studies.
DILIE: Deep Internal Learning for Image Enhancement
Dec 11, 2020

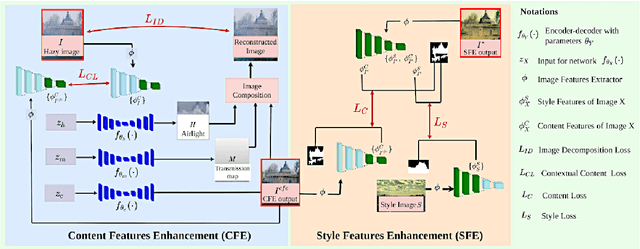

We consider the generic deep image enhancement problem where an input image is transformed into a perceptually better-looking image. Recent methods for image enhancement consider the problem by performing style transfer and image restoration. The methods mostly fall into two categories: training data-based and training data-independent (deep internal learning methods). We perform image enhancement in the deep internal learning framework. Our Deep Internal Learning for Image Enhancement framework enhances content features and style features and uses contextual content loss for preserving image context in the enhanced image. We show results on both hazy and noisy image enhancement. To validate the results, we use structure similarity and perceptual error, which is efficient in measuring the unrealistic deformation present in the images. We show that the proposed framework outperforms the relevant state-of-the-art works for image enhancement.
DeepCFL: Deep Contextual Features Learning from a Single Image
Nov 07, 2020
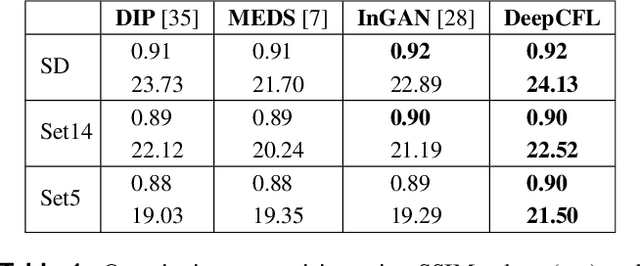
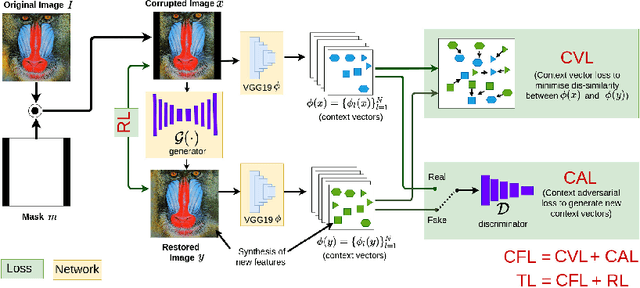
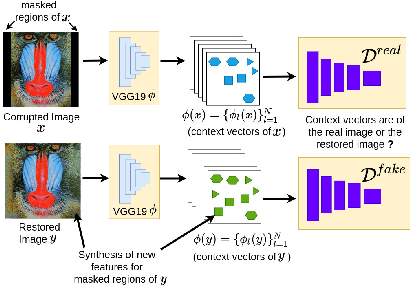
Recently, there is a vast interest in developing image feature learning methods that are independent of the training data, such as deep image prior, InGAN, SinGAN, and DCIL. These methods are unsupervised and are used to perform low-level vision tasks such as image restoration, image editing, and image synthesis. In this work, we proposed a new training data-independent framework, called Deep Contextual Features Learning (DeepCFL), to perform image synthesis and image restoration based on the semantics of the input image. The contextual features are simply the high dimensional vectors representing the semantics of the given image. DeepCFL is a single image GAN framework that learns the distribution of the context vectors from the input image. We show the performance of contextual learning in various challenging scenarios: outpainting, inpainting, and restoration of randomly removed pixels. DeepCFL is applicable when the input source image and the generated target image are not aligned. We illustrate image synthesis using DeepCFL for the task of image resizing.
Blind Motion Deblurring through SinGAN Architecture
Nov 07, 2020
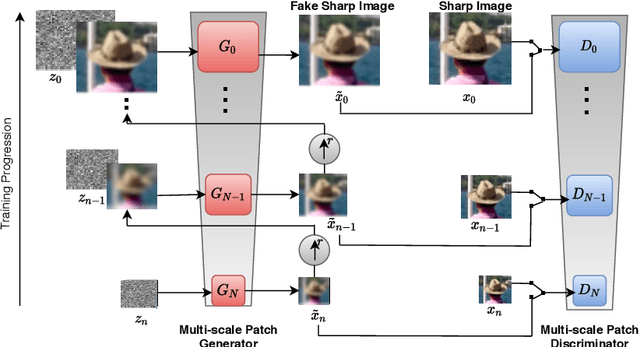
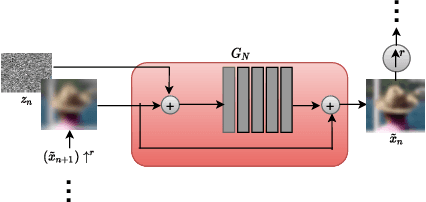

Blind motion deblurring involves reconstructing a sharp image from an observation that is blurry. It is a problem that is ill-posed and lies in the categories of image restoration problems. The training data-based methods for image deblurring mostly involve training models that take a lot of time. These models are data-hungry i.e., they require a lot of training data to generate satisfactory results. Recently, there are various image feature learning methods developed which relieve us of the need for training data and perform image restoration and image synthesis, e.g., DIP, InGAN, and SinGAN. SinGAN is a generative model that is unconditional and could be learned from a single natural image. This model primarily captures the internal distribution of the patches which are present in the image and is capable of generating samples of varied diversity while preserving the visual content of the image. Images generated from the model are very much like real natural images. In this paper, we focus on blind motion deblurring through SinGAN architecture.