 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMD-cGAN: Fast Motion Deblurring using Conditional Generative Adversarial Networks
Paper and Code

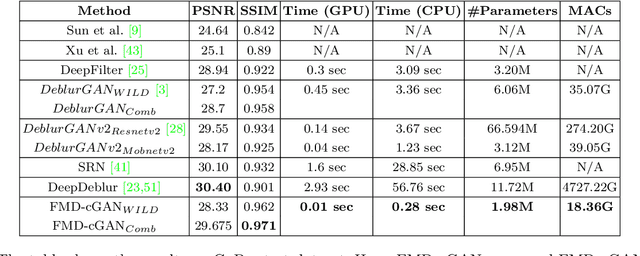


In this paper, we present a Fast Motion Deblurring-Conditional Generative Adversarial Network (FMD-cGAN) that helps in blind motion deblurring of a single image. FMD-cGAN delivers impressive structural similarity and visual appearance after deblurring an image. Like other deep neural network architectures, GANs also suffer from large model size (parameters) and computations. It is not easy to deploy the model on resource constraint devices such as mobile and robotics. With the help of MobileNet based architecture that consists of depthwise separable convolution, we reduce the model size and inference time, without losing the quality of the images. More specifically, we reduce the model size by 3-60x compare to the nearest competitor. The resulting compressed Deblurring cGAN faster than its closest competitors and even qualitative and quantitative results outperform various recently proposed state-of-the-art blind motion deblurring models. We can also use our model for real-time image deblurring tasks. The current experiment on the standard datasets shows the effectiveness of the proposed method.