 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBloomCoreset: Fast Coreset Sampling using Bloom Filters for Fine-Grained Self-Supervised Learning
Dec 22, 2024



The success of deep learning in supervised fine-grained recognition for domain-specific tasks relies heavily on expert annotations. The Open-Set for fine-grained Self-Supervised Learning (SSL) problem aims to enhance performance on downstream tasks by strategically sampling a subset of images (the Core-Set) from a large pool of unlabeled data (the Open-Set). In this paper, we propose a novel method, BloomCoreset, that significantly reduces sampling time from Open-Set while preserving the quality of samples in the coreset. To achieve this, we utilize Bloom filters as an innovative hashing mechanism to store both low- and high-level features of the fine-grained dataset, as captured by Open-CLIP, in a space-efficient manner that enables rapid retrieval of the coreset from the Open-Set. To show the effectiveness of the sampled coreset, we integrate the proposed method into the state-of-the-art fine-grained SSL framework, SimCore [1]. The proposed algorithm drastically outperforms the sampling strategy of the baseline in SimCore [1] with a $98.5\%$ reduction in sampling time with a mere $0.83\%$ average trade-off in accuracy calculated across $11$ downstream datasets.
$C^{3}$-NeRF: Modeling Multiple Scenes via Conditional-cum-Continual Neural Radiance Fields
Nov 29, 2024Neural radiance fields (NeRF) have exhibited highly photorealistic rendering of novel views through per-scene optimization over a single 3D scene. With the growing popularity of NeRF and its variants, they have become ubiquitous and have been identified as efficient 3D resources. However, they are still far from being scalable since a separate model needs to be stored for each scene, and the training time increases linearly with every newly added scene. Surprisingly, the idea of encoding multiple 3D scenes into a single NeRF model is heavily under-explored. In this work, we propose a novel conditional-cum-continual framework, called $C^{3}$-NeRF, to accommodate multiple scenes into the parameters of a single neural radiance field. Unlike conventional approaches that leverage feature extractors and pre-trained priors for scene conditioning, we use simple pseudo-scene labels to model multiple scenes in NeRF. Interestingly, we observe the framework is also inherently continual (via generative replay) with minimal, if not no, forgetting of the previously learned scenes. Consequently, the proposed framework adapts to multiple new scenes without necessarily accessing the old data. Through extensive qualitative and quantitative evaluation using synthetic and real datasets, we demonstrate the inherent capacity of the NeRF model to accommodate multiple scenes with high-quality novel-view renderings without adding additional parameters. We provide implementation details and dynamic visualizations of our results in the supplementary file.
Learning Robust Deep Visual Representations from EEG Brain Recordings
Oct 25, 2023Decoding the human brain has been a hallmark of neuroscientists and Artificial Intelligence researchers alike. Reconstruction of visual images from brain Electroencephalography (EEG) signals has garnered a lot of interest due to its applications in brain-computer interfacing. This study proposes a two-stage method where the first step is to obtain EEG-derived features for robust learning of deep representations and subsequently utilize the learned representation for image generation and classification. We demonstrate the generalizability of our feature extraction pipeline across three different datasets using deep-learning architectures with supervised and contrastive learning methods. We have performed the zero-shot EEG classification task to support the generalizability claim further. We observed that a subject invariant linearly separable visual representation was learned using EEG data alone in an unimodal setting that gives better k-means accuracy as compared to a joint representation learning between EEG and images. Finally, we propose a novel framework to transform unseen images into the EEG space and reconstruct them with approximation, showcasing the potential for image reconstruction from EEG signals. Our proposed image synthesis method from EEG shows 62.9% and 36.13% inception score improvement on the EEGCVPR40 and the Thoughtviz datasets, which is better than state-of-the-art performance in GAN.
Single Image LDR to HDR Conversion using Conditional Diffusion
Jul 06, 2023Digital imaging aims to replicate realistic scenes, but Low Dynamic Range (LDR) cameras cannot represent the wide dynamic range of real scenes, resulting in under-/overexposed images. This paper presents a deep learning-based approach for recovering intricate details from shadows and highlights while reconstructing High Dynamic Range (HDR) images. We formulate the problem as an image-to-image (I2I) translation task and propose a conditional Denoising Diffusion Probabilistic Model (DDPM) based framework using classifier-free guidance. We incorporate a deep CNN-based autoencoder in our proposed framework to enhance the quality of the latent representation of the input LDR image used for conditioning. Moreover, we introduce a new loss function for LDR-HDR translation tasks, termed Exposure Loss. This loss helps direct gradients in the opposite direction of the saturation, further improving the results' quality. By conducting comprehensive quantitative and qualitative experiments, we have effectively demonstrated the proficiency of our proposed method. The results indicate that a simple conditional diffusion-based method can replace the complex camera pipeline-based architectures.
A Graph Neural Network Approach for Temporal Mesh Blending and Correspondence
Jun 23, 2023



We have proposed a self-supervised deep learning framework for solving the mesh blending problem in scenarios where the meshes are not in correspondence. To solve this problem, we have developed Red-Blue MPNN, a novel graph neural network that processes an augmented graph to estimate the correspondence. We have designed a novel conditional refinement scheme to find the exact correspondence when certain conditions are satisfied. We further develop a graph neural network that takes the aligned meshes and the time value as input and fuses this information to process further and generate the desired result. Using motion capture datasets and human mesh designing software, we create a large-scale synthetic dataset consisting of temporal sequences of human meshes in motion. Our results demonstrate that our approach generates realistic deformation of body parts given complex inputs.
TreeGCN-ED: Encoding Point Cloud using a Tree-Structured Graph Network
Oct 11, 2021

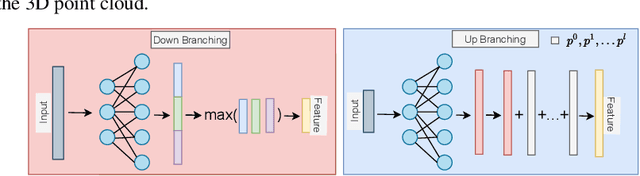
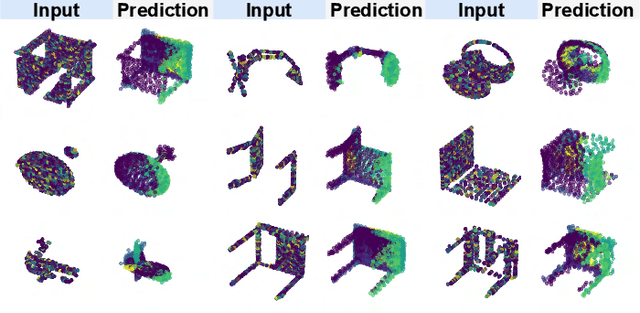
Point cloud is an efficient way of representing and storing 3D geometric data. Deep learning algorithms on point clouds are time and memory efficient. Several methods such as PointNet and FoldingNet have been proposed for processing point clouds. This work proposes an autoencoder based framework to generate robust embeddings for point clouds by utilizing hierarchical information using graph convolution. We perform multiple experiments to assess the quality of embeddings generated by the proposed encoder architecture and visualize the t-SNE map to highlight its ability to distinguish between different object classes. We further demonstrate the applicability of the proposed framework in applications like: 3D point cloud completion and Single image based 3D reconstruction.
HDIB1M -- Handwritten Document Image Binarization 1 Million Dataset
Feb 11, 2021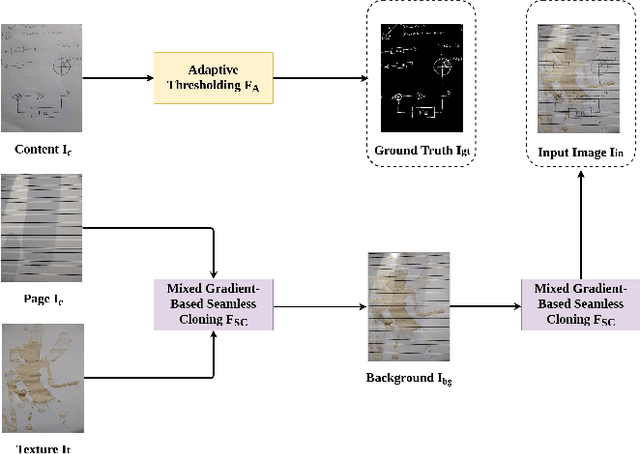
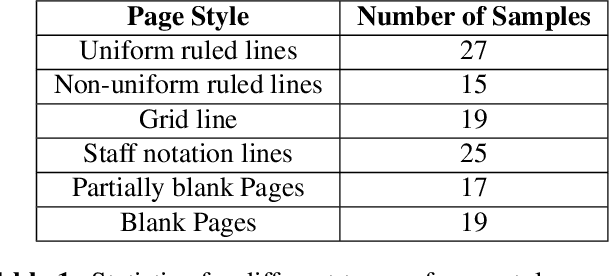
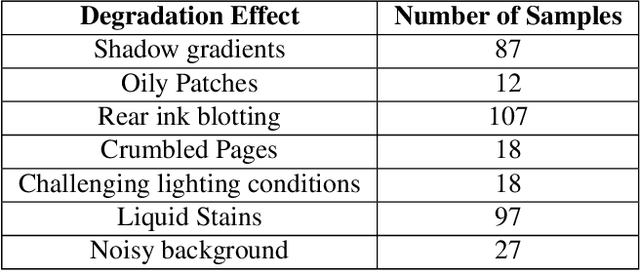

Handwritten document image binarization is a challenging task due to high diversity in the content, page style, and condition of the documents. While the traditional thresholding methods fail to generalize on such challenging scenarios, deep learning based methods can generalize well however, require a large training data. Current datasets for handwritten document image binarization are limited in size and fail to represent several challenging real-world scenarios. To solve this problem, we propose HDIB1M - a handwritten document image binarization dataset of 1M images. We also present a novel method used to generate this dataset. To show the effectiveness of our dataset we train a deep learning model UNetED on our dataset and evaluate its performance on other publicly available datasets. The dataset and the code will be made available to the community.
APEX-Net: Automatic Plot Extractor Network
Feb 11, 2021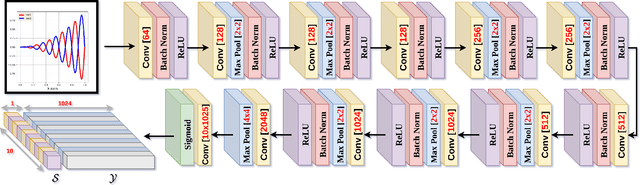

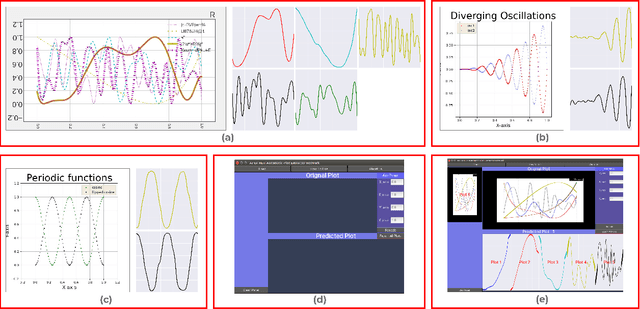
Automatic extraction of raw data from 2D line plot images is a problem of great importance having many real-world applications. Several algorithms have been proposed for solving this problem. However, these algorithms involve a significant amount of human intervention. To minimize this intervention, we propose APEX-Net, a deep learning based framework with novel loss functions for solving the plot extraction problem. We introduce APEX-1M, a new large scale dataset which contains both the plot images and the raw data. We demonstrate the performance of APEX-Net on the APEX-1M test set and show that it obtains impressive accuracy. We also show visual results of our network on unseen plot images and demonstrate that it extracts the shape of the plots to a great extent. Finally, we develop a GUI based software for plot extraction that can benefit the community at large. For dataset and more information visit https://sites.google.com/view/apexnetpaper/.