 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRASP: Revisiting 3D Anamorphic Art for Shadow-Guided Packing of Irregular Objects
Apr 03, 2025Recent advancements in learning-based methods have opened new avenues for exploring and interpreting art forms, such as shadow art, origami, and sketch art, through computational models. One notable visual art form is 3D Anamorphic Art in which an ensemble of arbitrarily shaped 3D objects creates a realistic and meaningful expression when observed from a particular viewpoint and loses its coherence over the other viewpoints. In this work, we build on insights from 3D Anamorphic Art to perform 3D object arrangement. We introduce RASP, a differentiable-rendering-based framework to arrange arbitrarily shaped 3D objects within a bounded volume via shadow (or silhouette)-guided optimization with an aim of minimal inter-object spacing and near-maximal occupancy. Furthermore, we propose a novel SDF-based formulation to handle inter-object intersection and container extrusion. We demonstrate that RASP can be extended to part assembly alongside object packing considering 3D objects to be "parts" of another 3D object. Finally, we present artistic illustrations of multi-view anamorphic art, achieving meaningful expressions from multiple viewpoints within a single ensemble.
Single-Photon 3D Imaging with Equi-Depth Photon Histograms
Aug 28, 2024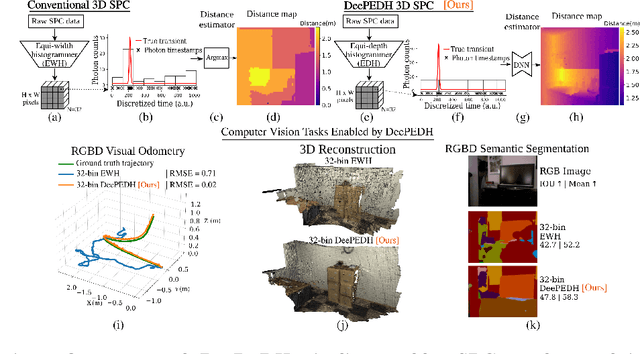
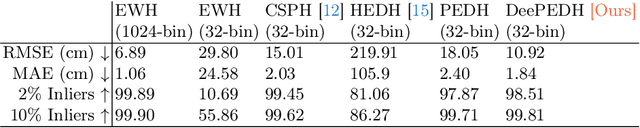
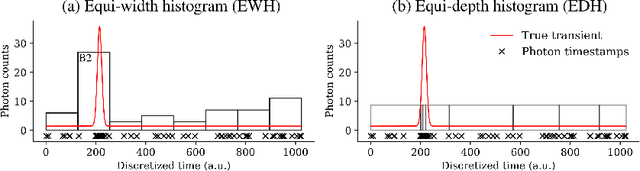
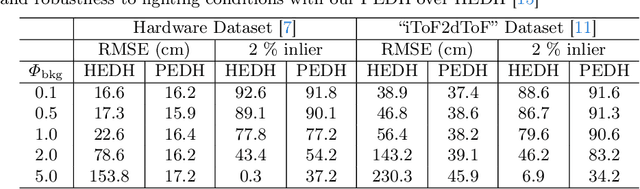
Single-photon cameras present a promising avenue for high-resolution 3D imaging. They have ultra-high sensitivity -- down to individual photons -- and can record photon arrival times with extremely high (sub-nanosecond) resolution. Single-photon 3D cameras estimate the round-trip time of a laser pulse by forming equi-width (EW) histograms of detected photon timestamps. Acquiring and transferring such EW histograms requires high bandwidth and in-pixel memory, making SPCs less attractive in resource-constrained settings such as mobile devices and AR/VR headsets. In this work we propose a 3D sensing technique based on equi-depth (ED) histograms. ED histograms compress timestamp data more efficiently than EW histograms, reducing the bandwidth requirement. Moreover, to reduce the in-pixel memory requirement, we propose a lightweight algorithm to estimate ED histograms in an online fashion without explicitly storing the photon timestamps. This algorithm is amenable to future in-pixel implementations. We propose algorithms that process ED histograms to perform 3D computer-vision tasks of estimating scene distance maps and performing visual odometry under challenging conditions such as high ambient light. Our work paves the way towards lower bandwidth and reduced in-pixel memory requirements for SPCs, making them attractive for resource-constrained 3D vision applications. Project page: $\href{https://www.computational.camera/pedh}{https://www.computational.camera/pedh}$
TreeGCN-ED: Encoding Point Cloud using a Tree-Structured Graph Network
Oct 11, 2021

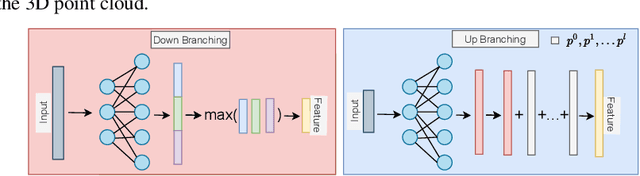
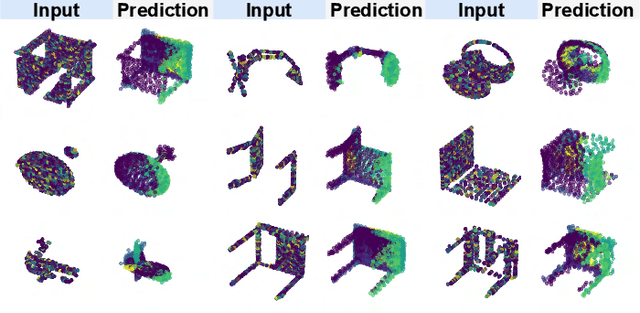
Point cloud is an efficient way of representing and storing 3D geometric data. Deep learning algorithms on point clouds are time and memory efficient. Several methods such as PointNet and FoldingNet have been proposed for processing point clouds. This work proposes an autoencoder based framework to generate robust embeddings for point clouds by utilizing hierarchical information using graph convolution. We perform multiple experiments to assess the quality of embeddings generated by the proposed encoder architecture and visualize the t-SNE map to highlight its ability to distinguish between different object classes. We further demonstrate the applicability of the proposed framework in applications like: 3D point cloud completion and Single image based 3D reconstruction.
Shadow Art Revisited: A Differentiable Rendering Based Approach
Jul 30, 2021
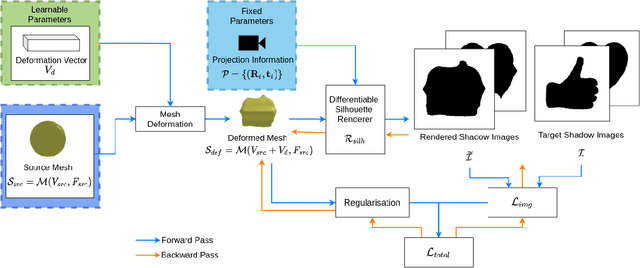
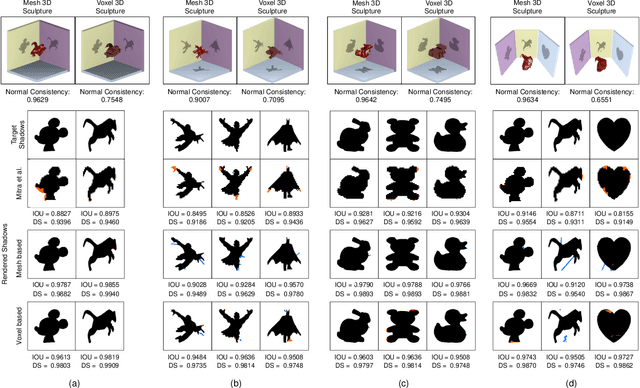
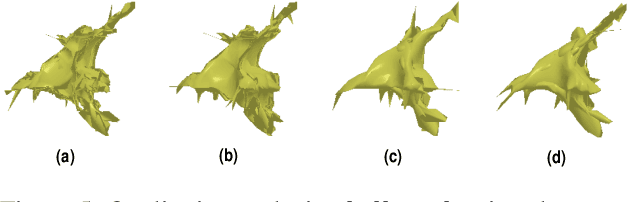
While recent learning based methods have been observed to be superior for several vision-related applications, their potential in generating artistic effects has not been explored much. One such interesting application is Shadow Art - a unique form of sculptural art where 2D shadows cast by a 3D sculpture produce artistic effects. In this work, we revisit shadow art using differentiable rendering based optimization frameworks to obtain the 3D sculpture from a set of shadow (binary) images and their corresponding projection information. Specifically, we discuss shape optimization through voxel as well as mesh-based differentiable renderers. Our choice of using differentiable rendering for generating shadow art sculptures can be attributed to its ability to learn the underlying 3D geometry solely from image data, thus reducing the dependence on 3D ground truth. The qualitative and quantitative results demonstrate the potential of the proposed framework in generating complex 3D sculptures that go beyond those seen in contemporary art pieces using just a set of shadow images as input. Further, we demonstrate the generation of 3D sculptures to cast shadows of faces, animated movie characters, and applicability of the framework to sketch-based 3D reconstruction of underlying shapes.
HDIB1M -- Handwritten Document Image Binarization 1 Million Dataset
Feb 11, 2021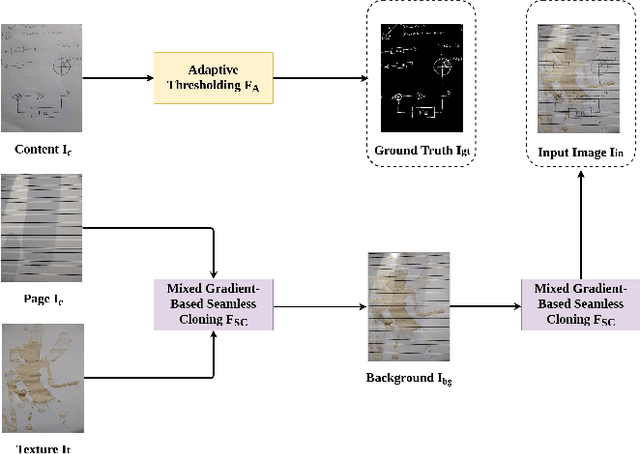
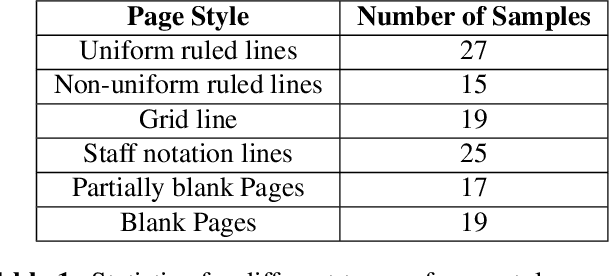
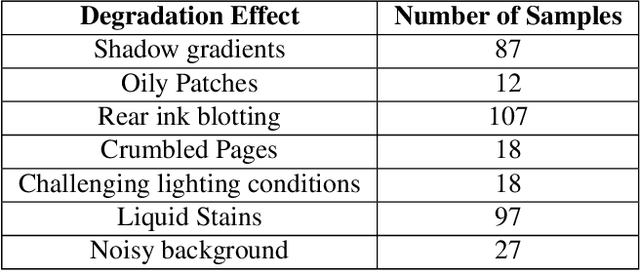

Handwritten document image binarization is a challenging task due to high diversity in the content, page style, and condition of the documents. While the traditional thresholding methods fail to generalize on such challenging scenarios, deep learning based methods can generalize well however, require a large training data. Current datasets for handwritten document image binarization are limited in size and fail to represent several challenging real-world scenarios. To solve this problem, we propose HDIB1M - a handwritten document image binarization dataset of 1M images. We also present a novel method used to generate this dataset. To show the effectiveness of our dataset we train a deep learning model UNetED on our dataset and evaluate its performance on other publicly available datasets. The dataset and the code will be made available to the community.