 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Graph Neural Network Approach for Temporal Mesh Blending and Correspondence
Jun 23, 2023



We have proposed a self-supervised deep learning framework for solving the mesh blending problem in scenarios where the meshes are not in correspondence. To solve this problem, we have developed Red-Blue MPNN, a novel graph neural network that processes an augmented graph to estimate the correspondence. We have designed a novel conditional refinement scheme to find the exact correspondence when certain conditions are satisfied. We further develop a graph neural network that takes the aligned meshes and the time value as input and fuses this information to process further and generate the desired result. Using motion capture datasets and human mesh designing software, we create a large-scale synthetic dataset consisting of temporal sequences of human meshes in motion. Our results demonstrate that our approach generates realistic deformation of body parts given complex inputs.
APEX-Net: Automatic Plot Extractor Network
Feb 11, 2021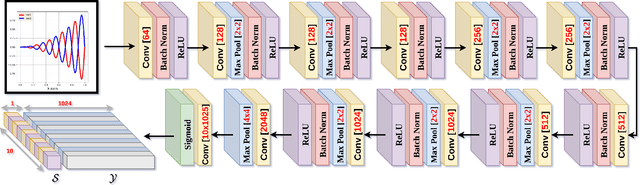

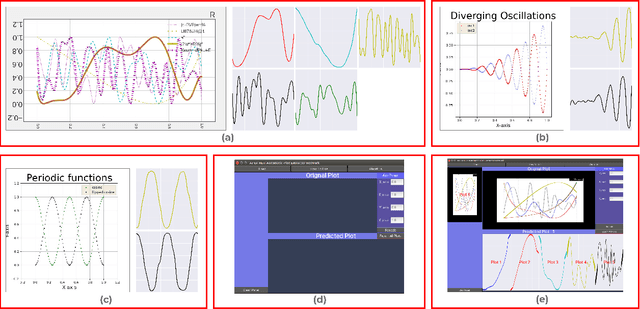
Automatic extraction of raw data from 2D line plot images is a problem of great importance having many real-world applications. Several algorithms have been proposed for solving this problem. However, these algorithms involve a significant amount of human intervention. To minimize this intervention, we propose APEX-Net, a deep learning based framework with novel loss functions for solving the plot extraction problem. We introduce APEX-1M, a new large scale dataset which contains both the plot images and the raw data. We demonstrate the performance of APEX-Net on the APEX-1M test set and show that it obtains impressive accuracy. We also show visual results of our network on unseen plot images and demonstrate that it extracts the shape of the plots to a great extent. Finally, we develop a GUI based software for plot extraction that can benefit the community at large. For dataset and more information visit https://sites.google.com/view/apexnetpaper/.
SA-CNN: Dynamic Scene Classification using Convolutional Neural Networks
Aug 29, 2015
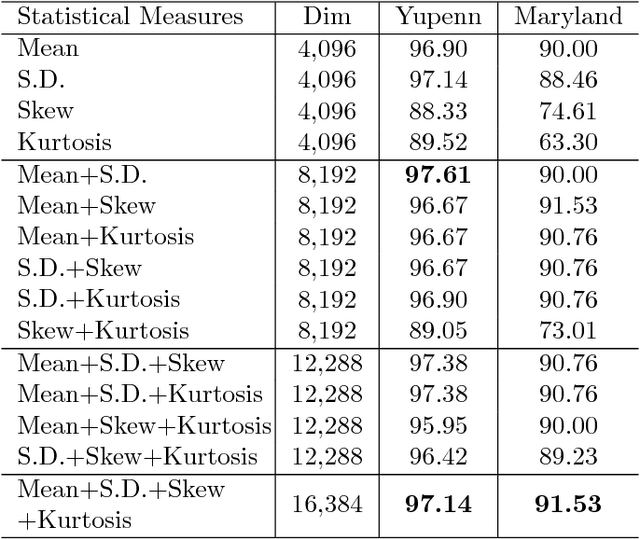

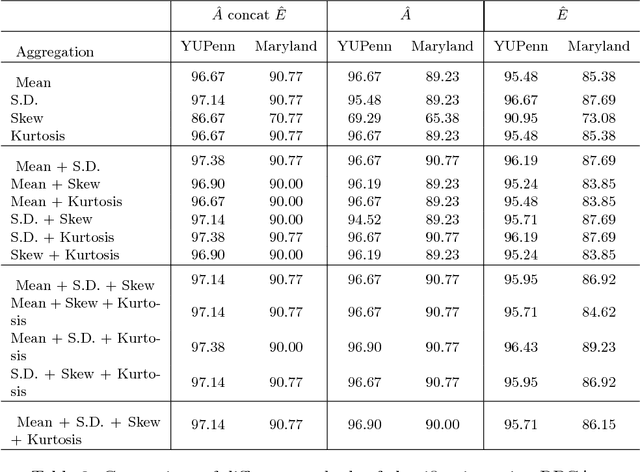
The task of classifying videos of natural dynamic scenes into appropriate classes has gained lot of attention in recent years. The problem especially becomes challenging when the camera used to capture the video is dynamic. In this paper, we analyse the performance of statistical aggregation (SA) techniques on various pre-trained convolutional neural network(CNN) models to address this problem. The proposed approach works by extracting CNN activation features for a number of frames in a video and then uses an aggregation scheme in order to obtain a robust feature descriptor for the video. We show through results that the proposed approach performs better than the-state-of-the arts for the Maryland and YUPenn dataset. The final descriptor obtained is powerful enough to distinguish among dynamic scenes and is even capable of addressing the scenario where the camera motion is dominant and the scene dynamics are complex. Further, this paper shows an extensive study on the performance of various aggregation methods and their combinations. We compare the proposed approach with other dynamic scene classification algorithms on two publicly available datasets - Maryland and YUPenn to demonstrate the superior performance of the proposed approach.