 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCity Navigation in the Wild: Exploring Emergent Navigation from Web-Scale Knowledge in MLLMs
Dec 17, 2025Leveraging multimodal large language models (MLLMs) to develop embodied agents offers significant promise for addressing complex real-world tasks. However, current evaluation benchmarks remain predominantly language-centric or heavily reliant on simulated environments, rarely probing the nuanced, knowledge-intensive reasoning essential for practical, real-world scenarios. To bridge this critical gap, we introduce the task of Sparsely Grounded Visual Navigation, explicitly designed to evaluate the sequential decision-making abilities of MLLMs in challenging, knowledge-intensive real-world environments. We operationalize this task with CityNav, a comprehensive benchmark encompassing four diverse global cities, specifically constructed to assess raw MLLM-driven agents in city navigation. Agents are required to rely solely on visual inputs and internal multimodal reasoning to sequentially navigate 50+ decision points without additional environmental annotations or specialized architectural modifications. Crucially, agents must autonomously achieve localization through interpreting city-specific cues and recognizing landmarks, perform spatial reasoning, and strategically plan and execute routes to their destinations. Through extensive evaluations, we demonstrate that current state-of-the-art MLLMs and standard reasoning techniques (e.g., Chain-of-Thought, Reflection) significantly underperform in this challenging setting. To address this, we propose Verbalization of Path (VoP), which explicitly grounds the agent's internal reasoning by probing an explicit cognitive map (key landmarks and directions toward the destination) from the MLLMs, substantially enhancing navigation success. Project Webpage: https://dwipddalal.github.io/AgentNav/
Towards Spatially-Aware and Optimally Faithful Concept-Based Explanations
Apr 15, 2025



Post-hoc, unsupervised concept-based explanation methods (U-CBEMs) are a promising tool for generating semantic explanations of the decision-making processes in deep neural networks, having applications in both model improvement and understanding. It is vital that the explanation is accurate, or faithful, to the model, yet we identify several limitations of prior faithfulness metrics that inhibit an accurate evaluation; most notably, prior metrics involve only the set of concepts present, ignoring how they may be spatially distributed. We address these limitations with Surrogate Faithfulness (SF), an evaluation method that introduces a spatially-aware surrogate and two novel faithfulness metrics. Using SF, we produce Optimally Faithful (OF) explanations, where concepts are found that maximize faithfulness. Our experiments show that (1) adding spatial-awareness to prior U-CBEMs increases faithfulness in all cases; (2) OF produces significantly more faithful explanations than prior U-CBEMs (30% or higher improvement in error); (3) OF's learned concepts generalize well to out-of-domain data and are more robust to adversarial examples, where prior U-CBEMs struggle.
SEPSIS: I Can Catch Your Lies -- A New Paradigm for Deception Detection
Dec 01, 2023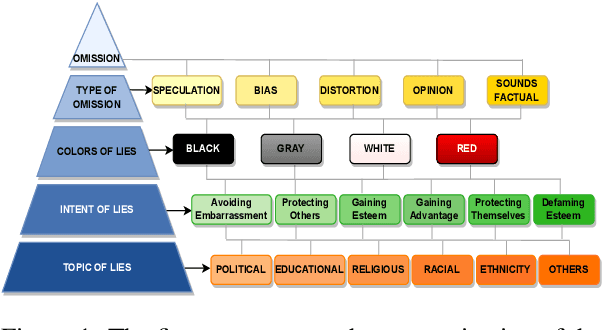


Deception is the intentional practice of twisting information. It is a nuanced societal practice deeply intertwined with human societal evolution, characterized by a multitude of facets. This research explores the problem of deception through the lens of psychology, employing a framework that categorizes deception into three forms: lies of omission, lies of commission, and lies of influence. The primary focus of this study is specifically on investigating only lies of omission. We propose a novel framework for deception detection leveraging NLP techniques. We curated an annotated dataset of 876,784 samples by amalgamating a popular large-scale fake news dataset and scraped news headlines from the Twitter handle of Times of India, a well-known Indian news media house. Each sample has been labeled with four layers, namely: (i) the type of omission (speculation, bias, distortion, sounds factual, and opinion), (ii) colors of lies(black, white, etc), and (iii) the intention of such lies (to influence, etc) (iv) topic of lies (political, educational, religious, etc). We present a novel multi-task learning pipeline that leverages the dataless merging of fine-tuned language models to address the deception detection task mentioned earlier. Our proposed model achieved an F1 score of 0.87, demonstrating strong performance across all layers including the type, color, intent, and topic aspects of deceptive content. Finally, our research explores the relationship between lies of omission and propaganda techniques. To accomplish this, we conducted an in-depth analysis, uncovering compelling findings. For instance, our analysis revealed a significant correlation between loaded language and opinion, shedding light on their interconnectedness. To encourage further research in this field, we will be making the models and dataset available with the MIT License, making it favorable for open-source research.
Learning Robust Deep Visual Representations from EEG Brain Recordings
Oct 25, 2023Decoding the human brain has been a hallmark of neuroscientists and Artificial Intelligence researchers alike. Reconstruction of visual images from brain Electroencephalography (EEG) signals has garnered a lot of interest due to its applications in brain-computer interfacing. This study proposes a two-stage method where the first step is to obtain EEG-derived features for robust learning of deep representations and subsequently utilize the learned representation for image generation and classification. We demonstrate the generalizability of our feature extraction pipeline across three different datasets using deep-learning architectures with supervised and contrastive learning methods. We have performed the zero-shot EEG classification task to support the generalizability claim further. We observed that a subject invariant linearly separable visual representation was learned using EEG data alone in an unimodal setting that gives better k-means accuracy as compared to a joint representation learning between EEG and images. Finally, we propose a novel framework to transform unseen images into the EEG space and reconstruct them with approximation, showcasing the potential for image reconstruction from EEG signals. Our proposed image synthesis method from EEG shows 62.9% and 36.13% inception score improvement on the EEGCVPR40 and the Thoughtviz datasets, which is better than state-of-the-art performance in GAN.
Single Image LDR to HDR Conversion using Conditional Diffusion
Jul 06, 2023Digital imaging aims to replicate realistic scenes, but Low Dynamic Range (LDR) cameras cannot represent the wide dynamic range of real scenes, resulting in under-/overexposed images. This paper presents a deep learning-based approach for recovering intricate details from shadows and highlights while reconstructing High Dynamic Range (HDR) images. We formulate the problem as an image-to-image (I2I) translation task and propose a conditional Denoising Diffusion Probabilistic Model (DDPM) based framework using classifier-free guidance. We incorporate a deep CNN-based autoencoder in our proposed framework to enhance the quality of the latent representation of the input LDR image used for conditioning. Moreover, we introduce a new loss function for LDR-HDR translation tasks, termed Exposure Loss. This loss helps direct gradients in the opposite direction of the saturation, further improving the results' quality. By conducting comprehensive quantitative and qualitative experiments, we have effectively demonstrated the proficiency of our proposed method. The results indicate that a simple conditional diffusion-based method can replace the complex camera pipeline-based architectures.
FACTIFY-5WQA: 5W Aspect-based Fact Verification through Question Answering
May 07, 2023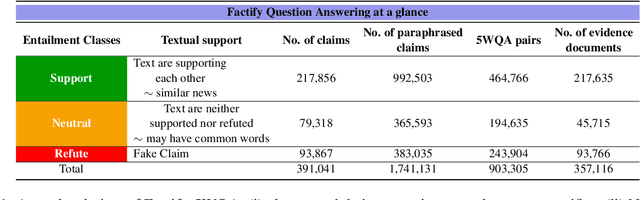
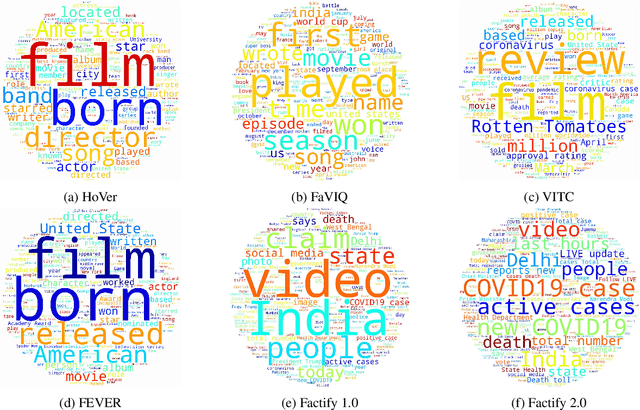

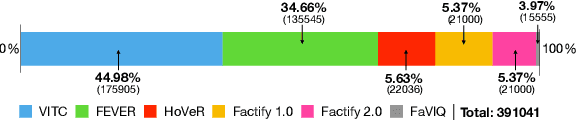
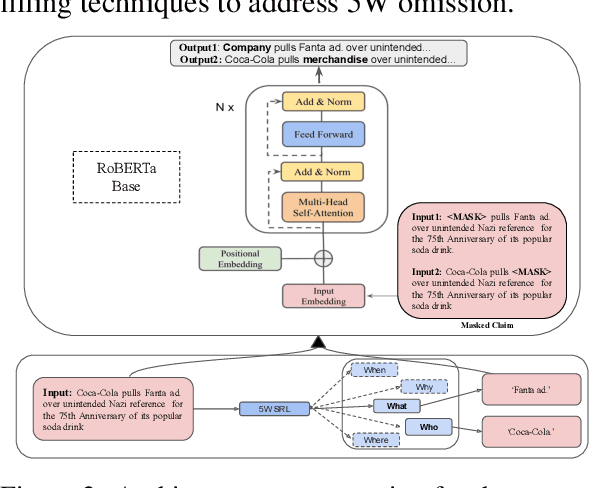
Automatic fact verification has received significant attention recently. Contemporary automatic fact-checking systems focus on estimating truthfulness using numerical scores which are not human-interpretable. A human fact-checker generally follows several logical steps to verify a verisimilitude claim and conclude whether it is truthful or a mere masquerade. Popular fact-checking websites follow a common structure for fact categorization such as half true, half false, false, pants on fire, etc. Therefore, it is necessary to have an aspect-based (which part is true and which part is false) explainable system that can assist human fact-checkers in asking relevant questions related to a fact, which can then be validated separately to reach a final verdict. In this paper, we propose a 5W framework (who, what, when, where, and why) for question-answer-based fact explainability. To that end, we have gathered a semi-automatically generated dataset called FACTIFY-5WQA, which consists of 395, 019 facts along with relevant 5W QAs underscoring our major contribution to this paper. A semantic role labeling system has been utilized to locate 5Ws, which generates QA pairs for claims using a masked language model. Finally, we report a baseline QA system to automatically locate those answers from evidence documents, which can be served as the baseline for future research in this field. Lastly, we propose a robust fact verification system that takes paraphrased claims and automatically validates them. The dataset and the baseline model are available at https://github.com/ankuranii/acl-5W-QA.
MMT: A Multilingual and Multi-Topic Indian Social Media Dataset
Apr 02, 2023Social media plays a significant role in cross-cultural communication. A vast amount of this occurs in code-mixed and multilingual form, posing a significant challenge to Natural Language Processing (NLP) tools for processing such information, like language identification, topic modeling, and named-entity recognition. To address this, we introduce a large-scale multilingual, and multi-topic dataset (MMT) collected from Twitter (1.7 million Tweets), encompassing 13 coarse-grained and 63 fine-grained topics in the Indian context. We further annotate a subset of 5,346 tweets from the MMT dataset with various Indian languages and their code-mixed counterparts. Also, we demonstrate that the currently existing tools fail to capture the linguistic diversity in MMT on two downstream tasks, i.e., topic modeling and language identification. To facilitate future research, we will make the anonymized and annotated dataset available in the public domain.