 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalar Distances: Semantic Attribute Gradients from Frozen MLLMs for Visual Embeddings
Jun 13, 2026Vision encoders for retrieval are typically trained with class-label supervision: each training pair reduces to a scalar that uniformly pushes the embedding apart or pulls it together, as if every visual attribute either differed or matched. A multimodal large language model (MLLM), shown the same pair, can articulate those attributes and use them to predict whether the images share a class. We propose \textbf{SAGA}, a framework that turns this language-grounded, attribute-aware perception into a training signal for the encoder itself. Specifically, we use Group Relative Policy Optimization (GRPO) to reward the MLLM for correct predictions on the vision encoder's tokens. Since correct predictions require those tokens to expose the specific attributes that differ or match between the pair, the gradient pushes the encoder to encode them, replacing the uniform pair-level scalar with attribute-resolved supervision. An auxiliary attention-distillation loss anchors the encoder's embedding to tokens the MLLM attended to, and a standard metric-learning loss shapes the embedding geometry for nearest-neighbour retrieval. The MLLM is frozen throughout and discarded at inference, matching the deployment cost of a metric-learning baseline. SAGA improves Recall@1 by 3 to 6 points over state-of-the-art baselines on CUB-200-2011, Cars-196, FGVC-Aircraft, and iNaturalist Aves on zero-shot image retrieval.
World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Jun 11, 2026Image-to-3D methods often trade off faithfulness and completeness: depth estimators are anchored to input pixels but stop at the visible surface, while image-to-3D models generate complete shapes that are often misaligned with the input. We introduce World Tracing, a generative pixel-aligned geometry representation that predicts 3D points aligned with observed pixels while completing geometry beyond the visible surface. For each input pixel, World Tracing predicts an ordered stack of camera-space 3D points, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. We instantiate this representation with a world-tracing diffusion transformer, WT-DiT, which treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention. WT-DiT is trained with pixel-space flow matching and a mixed noise schedule that balances visible-surface reconstruction with occluded-geometry generation. World Tracing achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators. It also preserves 2D-to-3D correspondence, enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
Finding Distributed Object-Centric Properties in Self-Supervised Transformers
Mar 27, 2026Self-supervised Vision Transformers (ViTs) like DINO show an emergent ability to discover objects, typically observed in [CLS] token attention maps of the final layer. However, these maps often contain spurious activations resulting in poor localization of objects. This is because the [CLS] token, trained on an image-level objective, summarizes the entire image instead of focusing on objects. This aggregation dilutes the object-centric information existing in the local, patch-level interactions. We analyze this by computing inter-patch similarity using patch-level attention components (query, key, and value) across all layers. We find that: (1) Object-centric properties are encoded in the similarity maps derived from all three components ($q, k, v$), unlike prior work that uses only key features or the [CLS] token. (2) This object-centric information is distributed across the network, not just confined to the final layer. Based on these insights, we introduce Object-DINO, a training-free method that extracts this distributed object-centric information. Object-DINO clusters attention heads across all layers based on the similarities of their patches and automatically identifies the object-centric cluster corresponding to all objects. We demonstrate Object-DINO's effectiveness on two applications: enhancing unsupervised object discovery (+3.6 to +12.4 CorLoc gains) and mitigating object hallucination in Multimodal Large Language Models by providing visual grounding. Our results demonstrate that using this distributed object-centric information improves downstream tasks without additional training.
City Navigation in the Wild: Exploring Emergent Navigation from Web-Scale Knowledge in MLLMs
Dec 17, 2025Leveraging multimodal large language models (MLLMs) to develop embodied agents offers significant promise for addressing complex real-world tasks. However, current evaluation benchmarks remain predominantly language-centric or heavily reliant on simulated environments, rarely probing the nuanced, knowledge-intensive reasoning essential for practical, real-world scenarios. To bridge this critical gap, we introduce the task of Sparsely Grounded Visual Navigation, explicitly designed to evaluate the sequential decision-making abilities of MLLMs in challenging, knowledge-intensive real-world environments. We operationalize this task with CityNav, a comprehensive benchmark encompassing four diverse global cities, specifically constructed to assess raw MLLM-driven agents in city navigation. Agents are required to rely solely on visual inputs and internal multimodal reasoning to sequentially navigate 50+ decision points without additional environmental annotations or specialized architectural modifications. Crucially, agents must autonomously achieve localization through interpreting city-specific cues and recognizing landmarks, perform spatial reasoning, and strategically plan and execute routes to their destinations. Through extensive evaluations, we demonstrate that current state-of-the-art MLLMs and standard reasoning techniques (e.g., Chain-of-Thought, Reflection) significantly underperform in this challenging setting. To address this, we propose Verbalization of Path (VoP), which explicitly grounds the agent's internal reasoning by probing an explicit cognitive map (key landmarks and directions toward the destination) from the MLLMs, substantially enhancing navigation success. Project Webpage: https://dwipddalal.github.io/AgentNav/
RGB-Only Supervised Camera Parameter Optimization in Dynamic Scenes
Sep 18, 2025
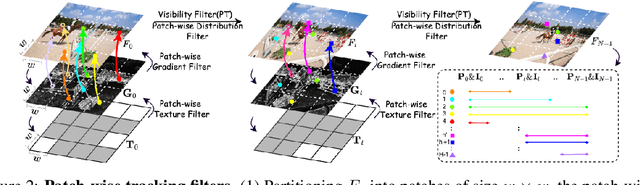
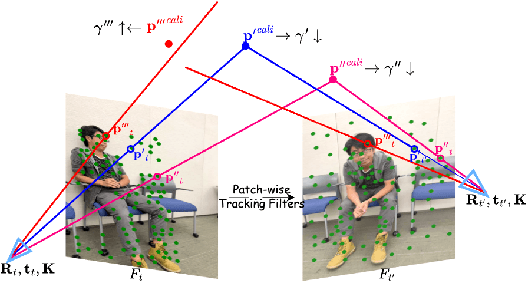
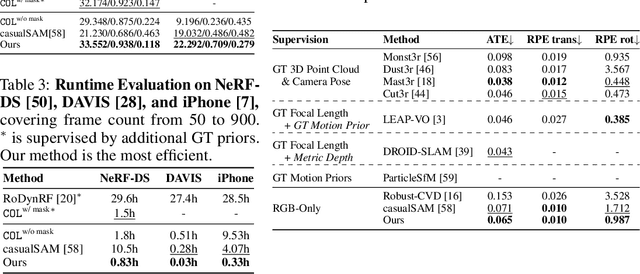
Although COLMAP has long remained the predominant method for camera parameter optimization in static scenes, it is constrained by its lengthy runtime and reliance on ground truth (GT) motion masks for application to dynamic scenes. Many efforts attempted to improve it by incorporating more priors as supervision such as GT focal length, motion masks, 3D point clouds, camera poses, and metric depth, which, however, are typically unavailable in casually captured RGB videos. In this paper, we propose a novel method for more accurate and efficient camera parameter optimization in dynamic scenes solely supervised by a single RGB video. Our method consists of three key components: (1) Patch-wise Tracking Filters, to establish robust and maximally sparse hinge-like relations across the RGB video. (2) Outlier-aware Joint Optimization, for efficient camera parameter optimization by adaptive down-weighting of moving outliers, without reliance on motion priors. (3) A Two-stage Optimization Strategy, to enhance stability and optimization speed by a trade-off between the Softplus limits and convex minima in losses. We visually and numerically evaluate our camera estimates. To further validate accuracy, we feed the camera estimates into a 4D reconstruction method and assess the resulting 3D scenes, and rendered 2D RGB and depth maps. We perform experiments on 4 real-world datasets (NeRF-DS, DAVIS, iPhone, and TUM-dynamics) and 1 synthetic dataset (MPI-Sintel), demonstrating that our method estimates camera parameters more efficiently and accurately with a single RGB video as the only supervision.
PhysRig: Differentiable Physics-Based Skinning and Rigging Framework for Realistic Articulated Object Modeling
Jun 26, 2025Skinning and rigging are fundamental components in animation, articulated object reconstruction, motion transfer, and 4D generation. Existing approaches predominantly rely on Linear Blend Skinning (LBS), due to its simplicity and differentiability. However, LBS introduces artifacts such as volume loss and unnatural deformations, and it fails to model elastic materials like soft tissues, fur, and flexible appendages (e.g., elephant trunks, ears, and fatty tissues). In this work, we propose PhysRig: a differentiable physics-based skinning and rigging framework that overcomes these limitations by embedding the rigid skeleton into a volumetric representation (e.g., a tetrahedral mesh), which is simulated as a deformable soft-body structure driven by the animated skeleton. Our method leverages continuum mechanics and discretizes the object as particles embedded in an Eulerian background grid to ensure differentiability with respect to both material properties and skeletal motion. Additionally, we introduce material prototypes, significantly reducing the learning space while maintaining high expressiveness. To evaluate our framework, we construct a comprehensive synthetic dataset using meshes from Objaverse, The Amazing Animals Zoo, and MixaMo, covering diverse object categories and motion patterns. Our method consistently outperforms traditional LBS-based approaches, generating more realistic and physically plausible results. Furthermore, we demonstrate the applicability of our framework in the pose transfer task highlighting its versatility for articulated object modeling.
Towards Spatially-Aware and Optimally Faithful Concept-Based Explanations
Apr 15, 2025



Post-hoc, unsupervised concept-based explanation methods (U-CBEMs) are a promising tool for generating semantic explanations of the decision-making processes in deep neural networks, having applications in both model improvement and understanding. It is vital that the explanation is accurate, or faithful, to the model, yet we identify several limitations of prior faithfulness metrics that inhibit an accurate evaluation; most notably, prior metrics involve only the set of concepts present, ignoring how they may be spatially distributed. We address these limitations with Surrogate Faithfulness (SF), an evaluation method that introduces a spatially-aware surrogate and two novel faithfulness metrics. Using SF, we produce Optimally Faithful (OF) explanations, where concepts are found that maximize faithfulness. Our experiments show that (1) adding spatial-awareness to prior U-CBEMs increases faithfulness in all cases; (2) OF produces significantly more faithful explanations than prior U-CBEMs (30% or higher improvement in error); (3) OF's learned concepts generalize well to out-of-domain data and are more robust to adversarial examples, where prior U-CBEMs struggle.
Disentangling CLIP Features for Enhanced Localized Understanding
Feb 05, 2025Vision-language models (VLMs) demonstrate impressive capabilities in coarse-grained tasks like image classification and retrieval. However, they struggle with fine-grained tasks that require localized understanding. To investigate this weakness, we comprehensively analyze CLIP features and identify an important issue: semantic features are highly correlated. Specifically, the features of a class encode information about other classes, which we call mutual feature information (MFI). This mutual information becomes evident when we query a specific class and unrelated objects are activated along with the target class. To address this issue, we propose Unmix-CLIP, a novel framework designed to reduce MFI and improve feature disentanglement. We introduce MFI loss, which explicitly separates text features by projecting them into a space where inter-class similarity is minimized. To ensure a corresponding separation in image features, we use multi-label recognition (MLR) to align the image features with the separated text features. This ensures that both image and text features are disentangled and aligned across modalities, improving feature separation for downstream tasks. For the COCO- 14 dataset, Unmix-CLIP reduces feature similarity by 24.9%. We demonstrate its effectiveness through extensive evaluations of MLR and zeroshot semantic segmentation (ZS3). In MLR, our method performs competitively on the VOC2007 and surpasses SOTA approaches on the COCO-14 dataset, using fewer training parameters. Additionally, Unmix-CLIP consistently outperforms existing ZS3 methods on COCO and VOC
R2I-rPPG: A Robust Region of Interest Selection Method for Remote Photoplethysmography to Extract Heart Rate
Oct 21, 2024



The COVID-19 pandemic has underscored the need for low-cost, scalable approaches to measuring contactless vital signs, either during initial triage at a healthcare facility or virtual telemedicine visits. Remote photoplethysmography (rPPG) can accurately estimate heart rate (HR) when applied to close-up videos of healthy volunteers in well-lit laboratory settings. However, results from such highly optimized laboratory studies may not be readily translated to healthcare settings. One significant barrier to the practical application of rPPG in health care is the accurate localization of the region of interest (ROI). Clinical or telemedicine visits may involve sub-optimal lighting, movement artifacts, variable camera angle, and subject distance. This paper presents an rPPG ROI selection method based on 3D facial landmarks and patient head yaw angle. We then demonstrate the robustness of this ROI selection method when coupled to the Plane-Orthogonal-to-Skin (POS) rPPG method when applied to videos of patients presenting to an Emergency Department for respiratory complaints. Our results demonstrate the effectiveness of our proposed approach in improving the accuracy and robustness of rPPG in a challenging clinical environment.
Rethinking Prompting Strategies for Multi-Label Recognition with Partial Annotations
Sep 12, 2024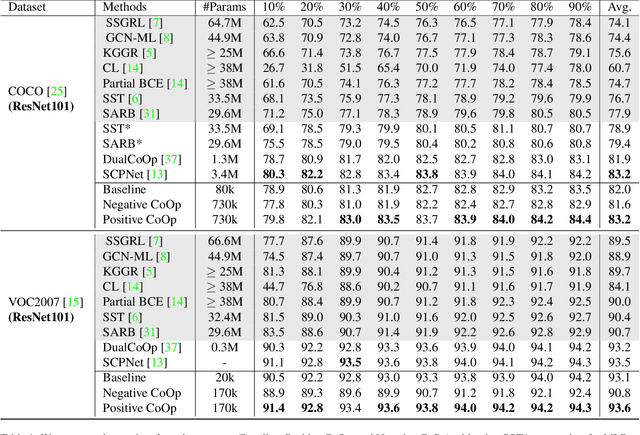
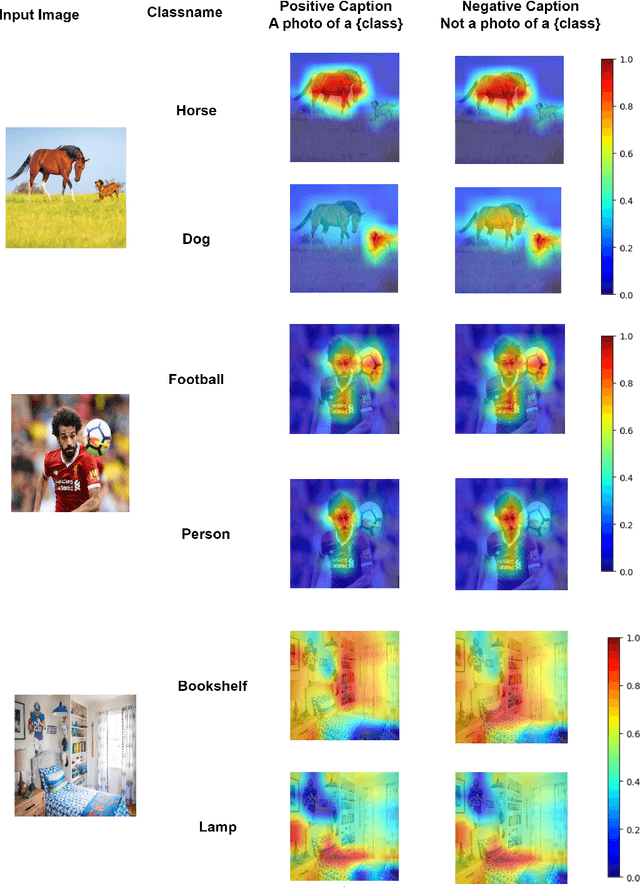
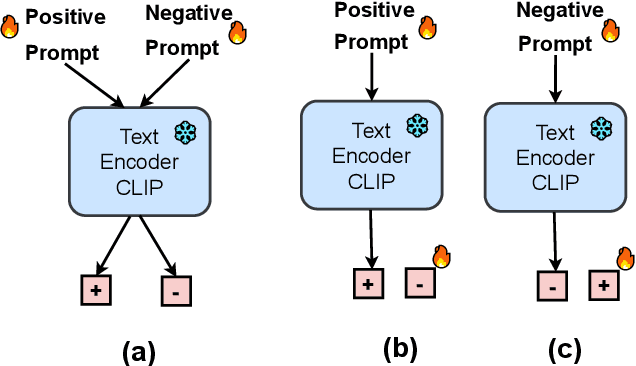
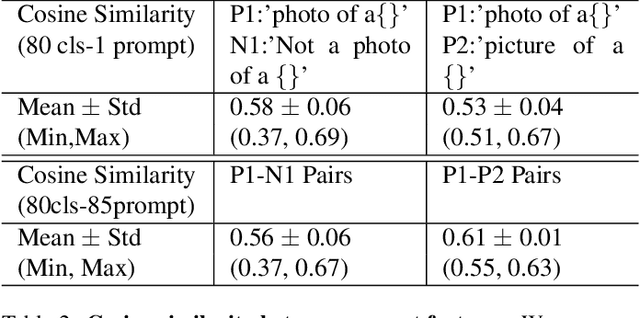
Vision-language models (VLMs) like CLIP have been adapted for Multi-Label Recognition (MLR) with partial annotations by leveraging prompt-learning, where positive and negative prompts are learned for each class to associate their embeddings with class presence or absence in the shared vision-text feature space. While this approach improves MLR performance by relying on VLM priors, we hypothesize that learning negative prompts may be suboptimal, as the datasets used to train VLMs lack image-caption pairs explicitly focusing on class absence. To analyze the impact of positive and negative prompt learning on MLR, we introduce PositiveCoOp and NegativeCoOp, where only one prompt is learned with VLM guidance while the other is replaced by an embedding vector learned directly in the shared feature space without relying on the text encoder. Through empirical analysis, we observe that negative prompts degrade MLR performance, and learning only positive prompts, combined with learned negative embeddings (PositiveCoOp), outperforms dual prompt learning approaches. Moreover, we quantify the performance benefits that prompt-learning offers over a simple vision-features-only baseline, observing that the baseline displays strong performance comparable to dual prompt learning approach (DualCoOp), when the proportion of missing labels is low, while requiring half the training compute and 16 times fewer parameters